

My TG Channel - https://t.me/StefanFalkokAI
My TG Chat - https://t.me/+y4R5JybDZcFjMjFi
Thanks SD_Prompt_by_Art for help with testing workflow - https://t.me/prompt_by_art
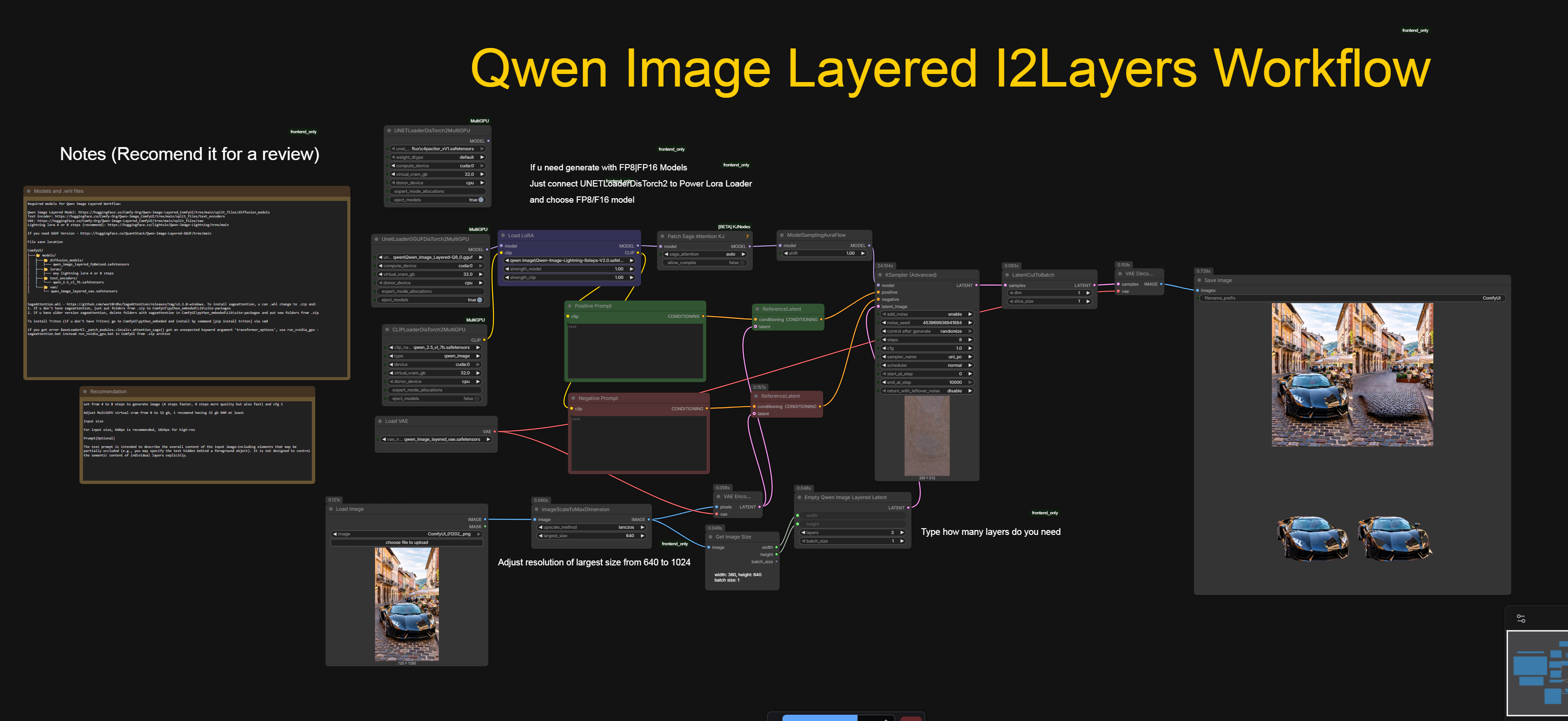
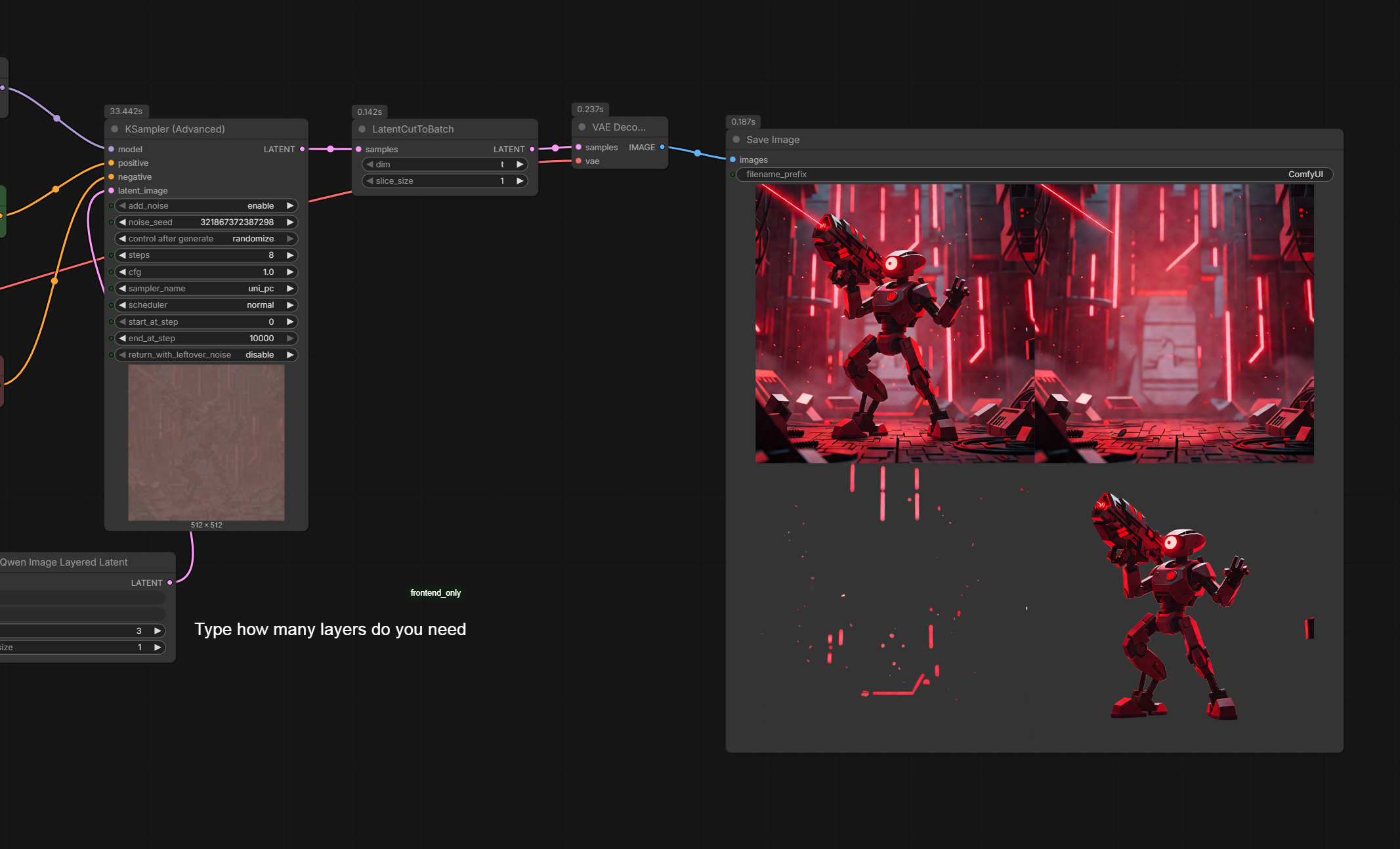
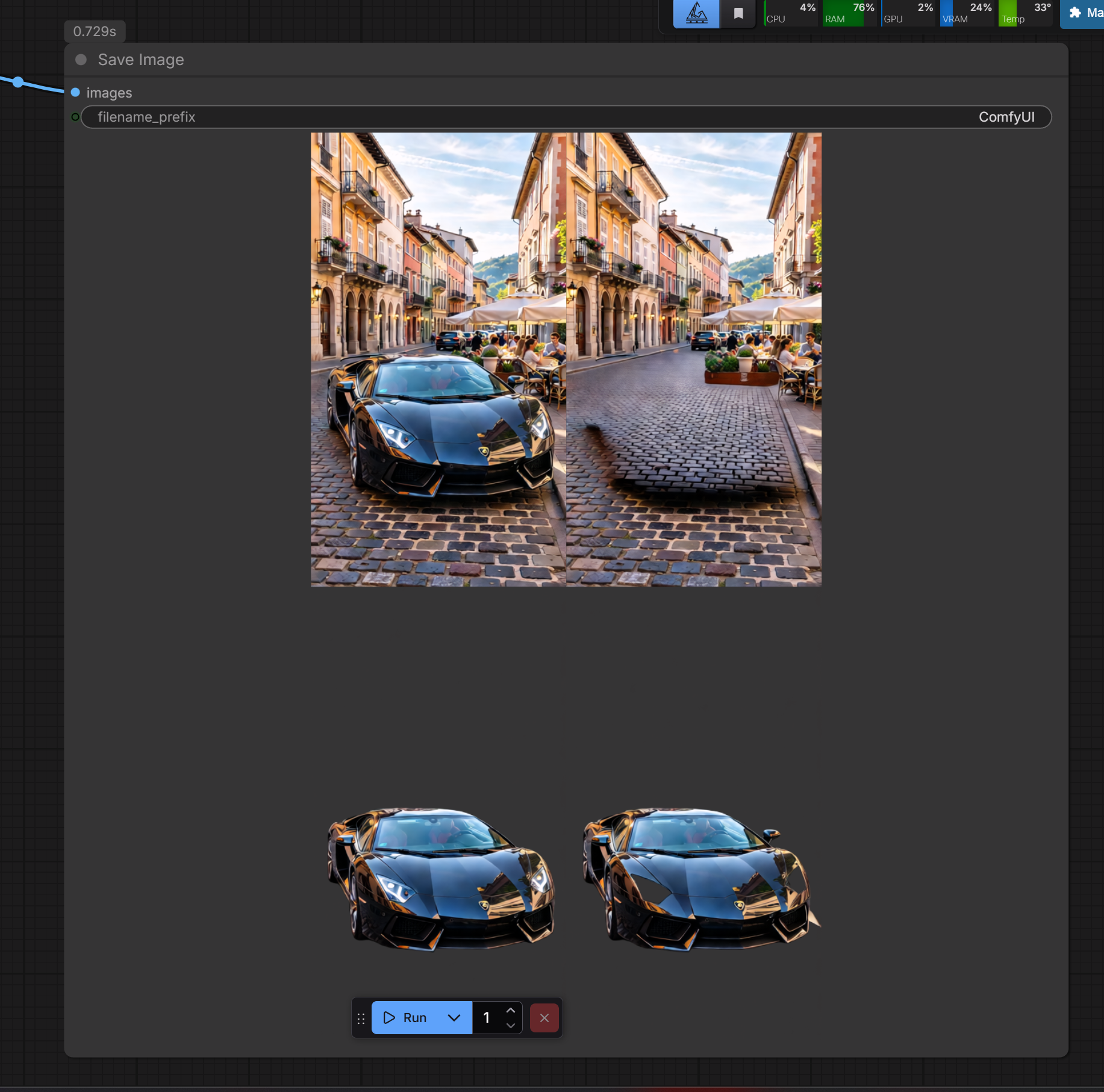
Hi! I introduce my working workflow with Qwen Image Layered I2L
I have included workflow with Qwen Image models
You need to have Qwen Image Model (https://huggingface.co/Comfy-Org/Qwen-Image-Layered_ComfyUI/tree/main/split_files/diffusion_models), clip (https://huggingface.co/Comfy-Org/Qwen-Image_ComfyUI/tree/main/split_files/text_encoders) and vae (https://huggingface.co/Comfy-Org/Qwen-Image-Layered_ComfyUI/tree/main/split_files/vae)
i recomend use 4 or 8 steps lora qwen image to get faster result
GGUF Qwen Image Layered - https://huggingface.co/QuantStack/Qwen-Image-Layered-GGUF/tree/main
I want to warn you model is slow and on the 5080 each iteration takes 10-15 seconds. It's not because VRAM or RAM shortage. So i have included light loras in workflow
download my ComfyUI Build https://huggingface.co/datasets/StefanFalkok/ComfyUI_portable_torch_2.9.1_cu130_cp313_sageattention_triton, also u need download and install CUDA 13.0 (https://developer.nvidia.com/cuda-13-0-0-download-archive) and VS Code (https://visualstudio.microsoft.com/downloads/)
Leave comments if you have trouble or you found the problem with workflows
Description
I2Layers workflow + fix MultiGPU
FAQ
Comments (2)
Hello,
Thank you for making this public!
May I ask you - if I understand it correctly one step takes 10-15 second so for 4steps settings it takes 40-60 seconds per image on 5080?
With 4 steps 1 cfg it takes 10-15 sec
With 8 steps - 25-30 sec
If you use without Lora, set 20 steps and cfg 3-5 - 200 sec
30 steps - 300 sec