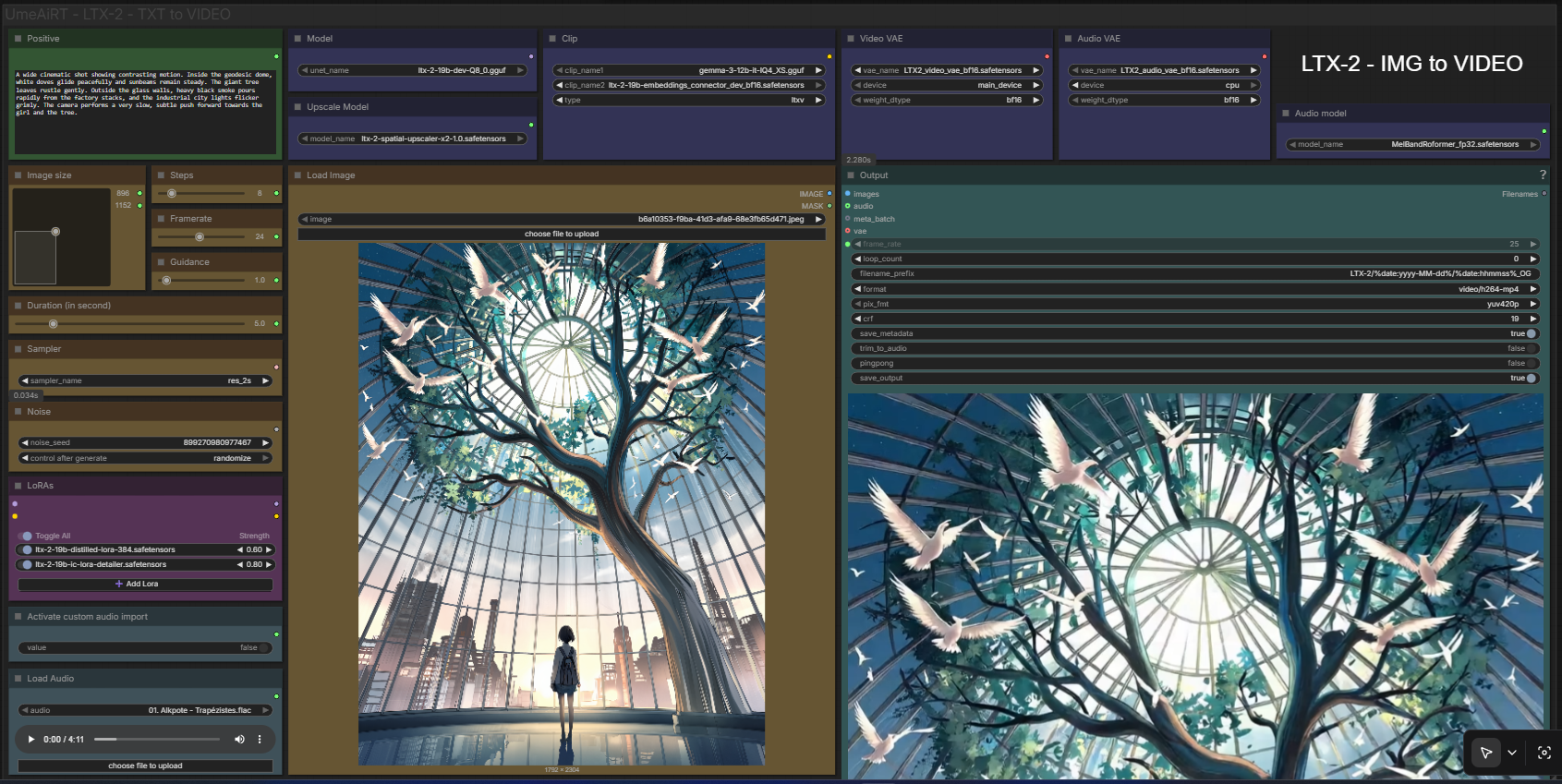
Hello, just a quick note to let you know that I created this workflow under complex conditions. I don't have my usual system and am forced to rent runpods for my tests. I haven't been able to perform as many checks and tests as usual, so please don't hesitate to send me a message if you encounter any problems.
Description:
This workflow allows you to generate video a base image and a text.
Resources you need:
📂Files :
LTX2 Quant Model: Q8, Q6, Q5, Q4, Q3 (i recommend Q5)
In models/unet
MelBandRoFormer : MelBandRoformer_fp32.safetensors
in models/diffusion_models
GEMMA-3: Q8, Q6, Q5, Q4, Q3 (i recommend Q4)
in models/clip
TEXT ENCODER: ltx-2-19b-embeddings_connector_dev_bf16.safetensors
in models/clip
VIDEO VAE: TX2_video_vae_bf16.safetensors
in models/vae
AUDIO VAE: LTX2_audio_vae_bf16.safetensors
in models/vae
Upscale model: ltx-2-spatial-upscaler-x2-1.0.safetensors
in models/latent_upscale_models
Recommanded LoRA:
in models/loras
📦Custom Nodes :

Description
base version
FAQ
Comments (12)
Thank you for the links to all the files, it makes it so much easier than having to track them all down!
Is your ComfyUI up to date?
@UmeAiRT yes
@UmeAiRT node DualClipLoader GGUF dont support LTX2. Not working
@ApchXi update your GGUF loaders in the comfyui manager installed nodes, update to latest. Worked for me!
I wondered if you happend to have any workflows for illustrius. i've found character loras for that that i can't find for other models.
I have more than 5 workflows for Illustrious : https://civitai.com/collections/14887413
@UmeAiRT oh thank you! I had heard that SD wasn't the same model as illustrius not compatible. I actually have these workflows!
I aso had another question, is there something similar to PuLID that works for blackwell GPU's? I saw that workflow was depreciated. i'm looking for something that could do image to image or keep a face consistant in generation making smaller edits. masks seem to only do so much. i was looking for a bit more control over the imaging.
Good workflow. Face consistency from image when talking seems not great most of the time, OK sometimes. Anything to combat this?
gemma 3 12B it fp8 Text Encoder Not yet working ?
raise ValueError(f"Unexpected text model architecture type in GGUF file: {arch_str!r}")
ValueError: Unexpected text model architecture type in GGUF file: 'gemma3'
having trouble
RuntimeError: mat1 and mat2 shapes cannot be multiplied (1024x3840 and 1920x4096)