






💡 Search "huggy" to find all my models on site.
💡 Civitai switched its backend from A1111 to ComfyUI earlier this year (2024). That means you can't reuse prompts or seeds from last year to generate the same image. It's best to remove all weight values and start fresh.
📒 This is a big lora complex, read following table!
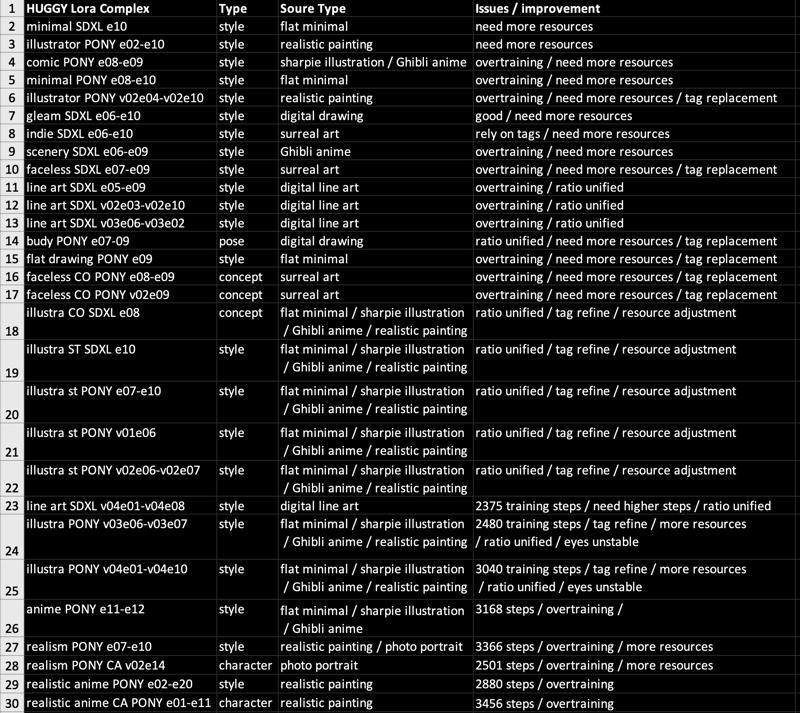
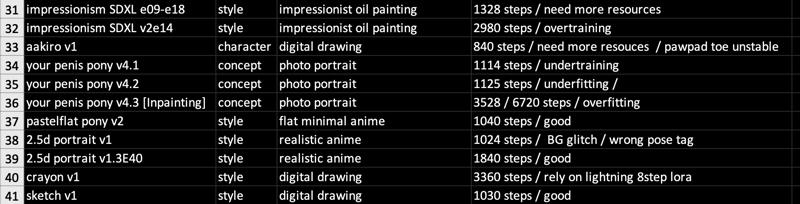
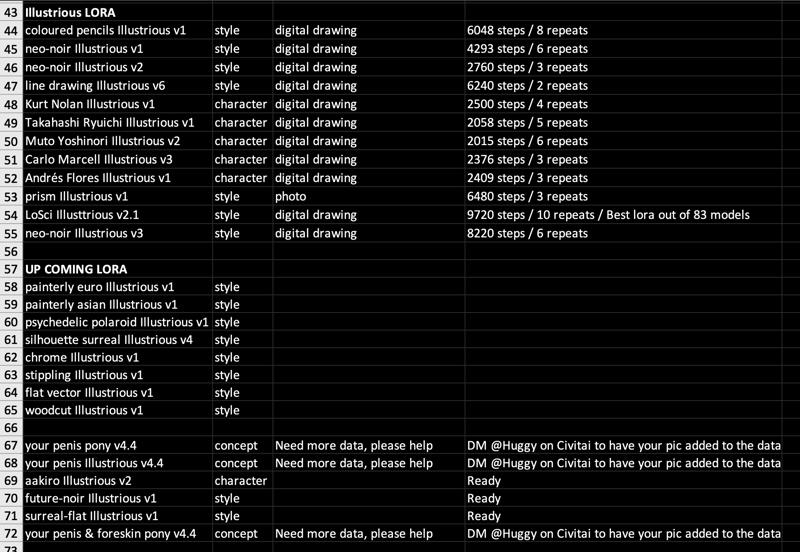
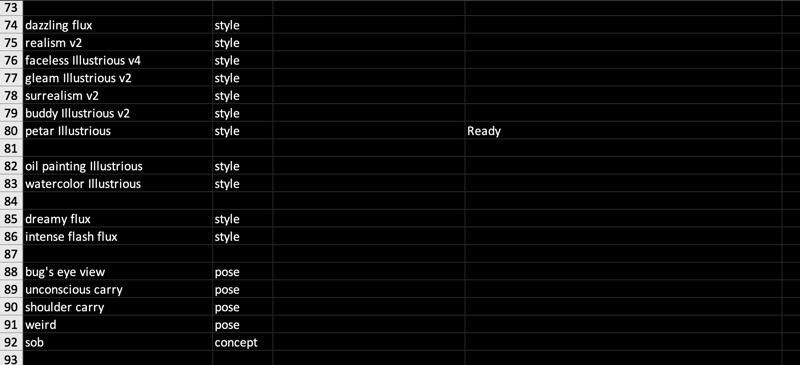
📒 Everything is an work in progress:
As you see, I uploaded lots of similar lora made with different epochs, LR and resource. Every lora is subtly unique as I will systematically compare one another by its quality (over sharpen / glitch / half baked), resemblance (to training resources) and character features (torso deformation, poor eyes, unnatural looks) in the future.
📒 Useful Tips:
Use the Lora with epoch below 7 for a stable result, like V03E06, though lora with higher epoch like V03E10 has better resemblances to the training source;
Most of my works were generated on Civitai (A1111 as a backend). Start from scratch is recommended, if you are using the prompt or parameters on a ComfyUI based generator (remove all weight values on tags).
Check the base model first, a Pony based lora won't work on most SDXL checkpoints, vice versa.
Some loras include multiple trigger codes (aaXXXxx, aaXXXxx, etc), representing different styles / characters.
USE fewer triggering words each time for best result;
Use CFG between 4.5 (complex scene) to 7.5 (simple);
For anime start training steps from a lower value like 19 with Euler a sampler, if you are satisfied with the result, use hi-res fix / face fix (and set Euler to 29) to increase over all quality;
For realistic photos, use DPM++2M Karra, 30+ steps for close up portrait, 35+ steps for full body shot.
There's no universal prompt / lora weight for every generation. If you're using anime style / character lora with realistic checkpoint, starting with a lower lora weight like 0.7. Ignore the lora weight in sample images, due to a recent bug, image generated online will display lora weight of 1 regardless the actual value.
step number setting (which is the weight for all tags) is closely associated with the complexity of the prompt, if your outcome has extra objects like fingers or limbs, try lower the step value (and the lora weight too); if your outcome has objects disappeared, lack of quality, texture and reality, try raising the step value.
Compose a prompt and wait for the generation seems like flipping through a mystery novel, you never know what twist is coming next. It's a way to explore the boundless of AI model. To get the exact outcome of what you planned is difficult as you have to find the proper glossary for each tag, and each word itself is a vague variant with various synonyms.
The training files are mostly focus on solo character, which means if you intent to generate a image with couple, you might get unexpected result. To fix this you need to use an additional lora trained with multiple people (like ExpressiveH) or a pose lora. A good multiple people lora should contain as many poses as it can with couple, threesome or a group of people and it is definitely a tough job.
📒 Issues to be fixed in the next version:
1) training base on Pony get versatile results than training base on SDXL, but when prompts contain 1 human and 1 animal, Pony has a great tendency of blending two species, put source_pony, source_furry in the negative prompts won't help. Does anyone knows how to solve this?
2) reduce training source quantity down to ??? or less, as this is a common problem across most of my loras, too many training images reduce the outcome quality, quality of the source images are more important.
3) Increase training source resolution.
4) Reduce training steps down to 1000, as I found lower training epochs lora got stable results
📒 Checkpoint Rating for Illustra V04E03
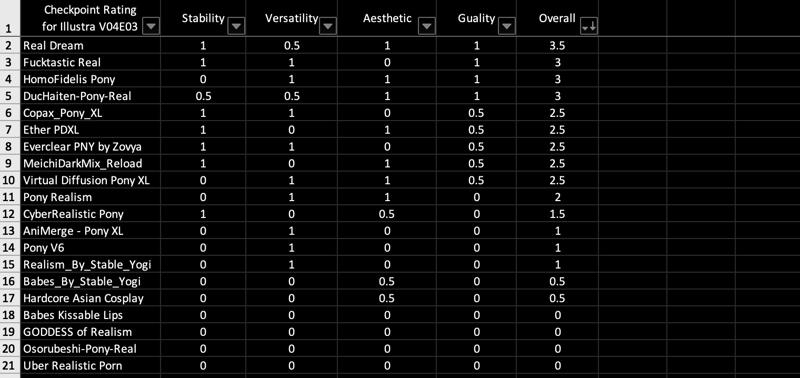
This is a lora complex which contains 11 (100 is my goal) unique styles and poses. Currently I have a list of ideas to add into this lora complex. It takes enormous time for me to prepare source images. Each Lora will need 2-15 iterations to fix glitches. I'd like to test my lora with all available checkpoints online before publishing, but I cannot do any of these since my buzz is running oooout, donate buzz if you like what you see.
📒 Mirroring
I’ve noticed a few sites, like Modelslab and yodayo, using bots to mirror my models. SeaArt in particular shows big numbers for downloads and generations.
I don’t mind if you mirror my models — sites like civitaiarchive have always done that.
I do mind if you block users from downloading the models and force them onto a paid online service.
I do mind if you claim copyright or give users ownership of the generations. These are open-source models, trained on open-source bases with limited-ownership data. No one — not even me — should claim copyright. Credit is all that’s needed.
Description
Image: 47
networkDim:64
networkAlpha:32
UPDATE NOTE
I removed all realistic painting style images, and trained it purely on portrait photos. Unfortunately due to there are only 47 training resource at this stage, and the base model is Pony 6V which is not ideal for realistic style.
The second version is unstable and required "perfect face:1.9" for positive prompt, and "poor drawn eye:1.9" for negative prompt, check my sample image for details.
FAQ
Comments (5)
what is the new version supposed to do different to the one yesterday? The same prompt makes more or less the same image. You've got it listed as /pose. Is it a pose, it's a bit confusing since you have so many obviously different loras all under the same heading.
please tell me which one, I updated multiple loras today, and I will add update note next time
@huggy I think that exemplifies my point. Putting all your different loras on the same page might seem like a clever idea but it makes things very complicated. The naming of them isn't easy to remember since they're strings of numbers and letters and I'm dyslexic. You can't easily copy and paste which one you're referring to and you can't see the lora names if you want to refer to them in a comment. Makes it all very confusing and unnecessary never mind remembering how to find it in your list of loras. Frankly it's too much trouble. You can do what you will with that information.
@Rivington I'm making a table of content in Excel to make things clear. Since some lora share similar training images, I put them under same page. At experimental stage, I do often go back to the earlier version lora for comparison. Once I'm satisfied at certain stage in the future, I will remove all similar versions. The ultimate goal is to merge all the best results into one or two big lora complex, like niji in midjourney.
@huggy It's okay, you don't have to explain. You do what suits your work. I'm just being open and honest as an end user.