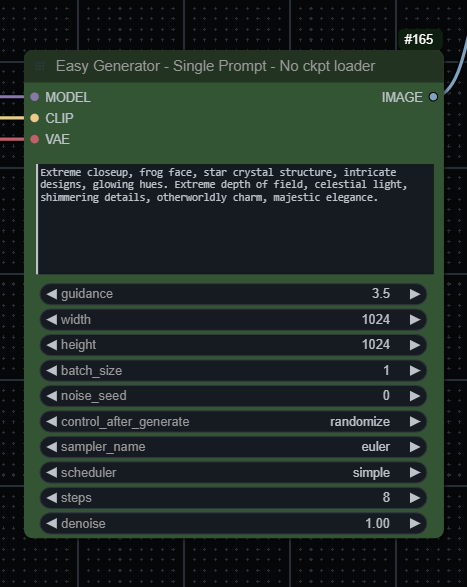

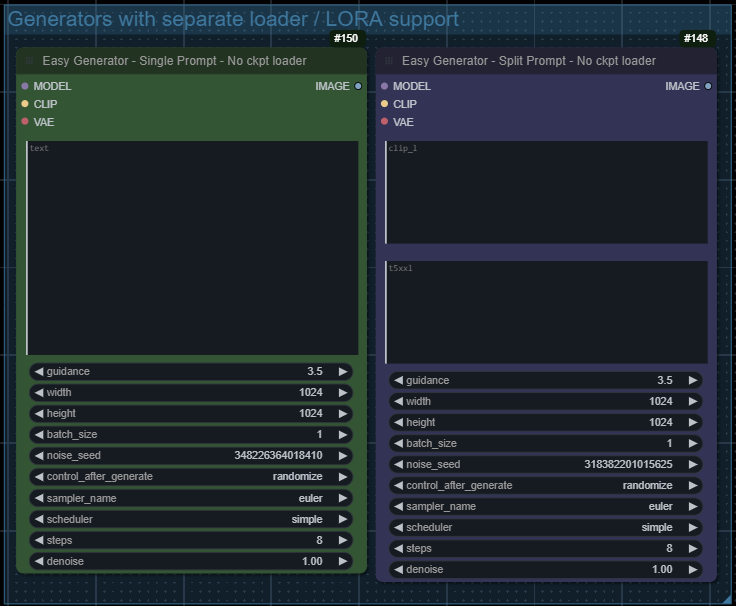
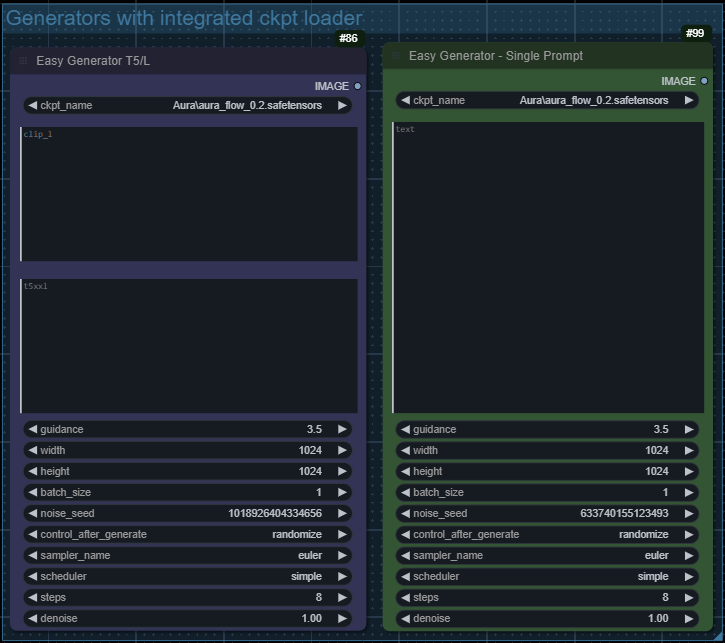
Most basic workflows for running Flux models. Needs the latest version of ComfyUI.
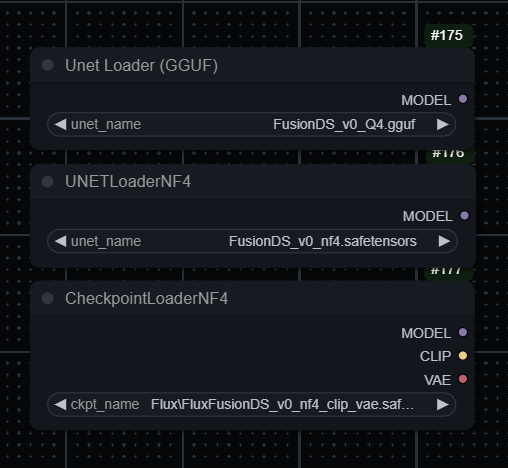
For GGUF models you need to install this node:
For BNB NF4 All-in-one models you need to install this node:
For BNB NF4/FP4 UNET models, you need to install this node:
For UNET models, separate Text encoders and VAE are necessary. You can find them here:
Description
Updated to use Lora Model Only node instead of regular lora loader. Also added workflow variants for GGUF (q4, q5, q8) and BNB (nf4, fp4) models.
FAQ
Comments (3)
Things started much faster with flux than it was with sdxl a year ago. Plus we have lots of concepts from LLM universe now. It's a bit overwhelming. I was hoping I could ask for an advice.
I managed to use q8 gguf for inference, it works. However, adding loras make it slower. There's a good explanation why it is so from city96 - https://github.com/city96/ComfyUI-GGUF/issues/36#issuecomment-2295300470.
The question is what would be the best option for inference on similar quality level but without slowing down when using loras on 16GB VRAM?
I like the groupings, nice work.
Thank you!