















Like the work I do and want to say thanks? Buy me a coffee or Support me on Patreon for exclusive early access to my models and more!
For version specific notes and settings, look under "About this version" --->
What a time to be alive! I created this model by block merging my low weight LoRA trainings over multiple passes (very similar to how I created my SDXL series models) to the base flux.d model. The result is a model that can do basic NSFW generations including proper female anatomy and concepts. Total training was about 5k images spread across SFW cinematic stills, art photography, LaION art-pop, about 1500ish explicit and artful nudes about 80% photography, 20% AI/illustrative nudes. The model responds well to prompts just like base-flux does. This is a WIP and only a V1, I will be tuning this model more as I identify weaknesses in the output and methods to improve the quality. This model was built on top of the flux.1_dev_8x8_e4m3fn-marduk191 version, so fp8 quality, though I have included the full FP16 clip-l and T5 models, as I don't like the quality drop off with FP8 T5 clip. If there is demand for an fp8/fp8 version, I can make one available.
Description
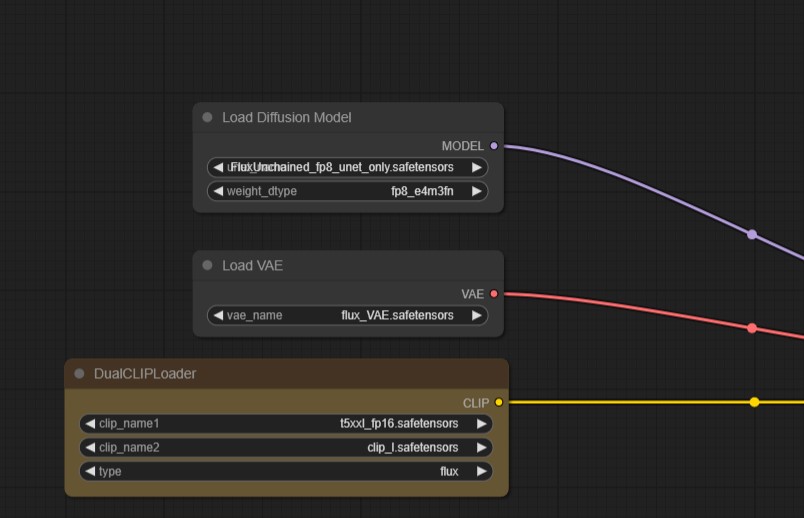
This is the same model as Flux Unchained V1, the Unet has been extracted and saved out. You can load it by dropping it into your /models/unet/ folder and load it with the Load Diffusion Model node. (see screenshot on the listing). The improvements here are multiple. You will no longer need to have unneeded clip/VAE models just taking up wasted space in the safetensor file, and even better, no more wonkiness when trying to load LoRAs from Civit!
I also want to mention that training for FU2 is already functionally complete, but it's been sitting on the backburner while I figured out all this file conversion stuff and making sure everything works. Keep an eye out for FU2 later this week!
Finally, just wanted to say thanks for all the love you guys 💖 - we as a community were in a bit of dark spot with SD3 being the 💩 that it is, but that magic of the early 1.5/SDXL days is back and I'm excited to be part of this journey with you all!
FAQ
Comments (30)
Good first go at uncensoring Flux.
Hi guys, I'm happy to release the UNET only version of FluxUnchained v1.1.0 today! This version requires you load the VAE and clip models separately (see image in listing for how to set up nodes). This version is fully compatible with Civit LoRAs I've tested, and is usable just like a normal Flux.d model now. Even better, this now lets me properly develop on this model (it was a serious hack-job to get the V1 original built) including training on on it directly. Good stuff!!!! 🔥
Anyway, I've got the training done for V2, just need to put it all together in this new process. I should have it ready to go by the end of this week I hope!
Hi! Thanks for this hard work it's changing the game!! Do you think it's better to use the Unet Flux instead of the checkpoint versions ? What are the benefits
Thank you for de-bloating your checkpoint :)
Works great for me
@Tetsuoo benefits are on the fly fp16/fp8, which is super handy, tho worth mentioning there won't be a quality increase with FP16 on FU1, as it was formerly an FP8 model to begin with... I will fix this moving forward, tho prob not until FU3, as FU2 tuning is already started with FP8 and too good to turn back now (coming soon!). Only need 1 unet and you can load up whatever clip/VAE models you want. and it's 11GB for the whole thing. it's very much a win/win/win.
Where is it? I only see the V1 UNET model.
It's not working for me. "You do not have CLIP state dict!” What am I doing wrong?
You will need to load a separate VAE and clip model to use the Unet only version and make sure you load it with the "Load Diffusion Model" loader node in Comfy, not the "Load Checkpoint" node.
This model is the standard by which all others will be judged. Well, at least for a few weeks. It's my go-to, very well done.
UNet only, Nice! I'm testing Flux 1 Dev with a 7900XTX using "Zluda" for backend, having Unet only is much more flexible. I think there's an issue with Comfy or emulation that doesn't release VRAM when using full Checkpoints.
Why does every woman look like Ana de Armas. At this point it's a bloody joke. WAY too many models seem to have been tuned with excessive pictures of this actress. It's almost hilarious.
I think the problem comes from the Flux model(s), not the Lora's training.
Well, if they're all going to look like one actress...
It's so fckng annoying to have all the female faces with square jaws and a butt (dimple) on the chin. Also, this model is incapable of generating small breasts. One bad apple spoils the bnunch.
Consider training on a D/S merge so we can make 4-8 step images really fast but keep most of the dev quality.
Just dropped SchnFU 😉 - check it out!
@socalguitarist thanks I will try it and compare to the one I merged .also will see what it does when I add the guidance layers. It's going to be interesting.
For folks who need a basic unet only flux workspace, I've pasted a very basic one here: https://pastebin.com/6RCEJLqW
just copy it and paste into comfy, should load. if not, save the text in a file as 'flux_workspace.json" and drag that into comfy.
I guess it is not possible to run the FP8 version with Forge? I was able to run the FP16 model with it
AssertionError: You do not have CLIP state dict!
i cant get it to run (FP16). Do you need a CLIP VAE?
You need https://huggingface.co/black-forest-labs/FLUX.1-dev/tree/main ae.safetensors (not the one in VAE folder), https://huggingface.co/comfyanonymous/flux_text_encoders/tree/main clip_l.safetensors and t5xxl_fp8_e4m3fn.safetensors (might as well get fp16 for the future). Dump them all into your VAE folder and load the 3 of them along the model, should work.
@airi finally got it working as per your instrucions. You beauty!
@airi this had me so aggravated the past couple of days until finally i figured it out last night. the other posts just said follow the forge 1050 thread instructions "its easy". Thats when i realized the text_encoder folder was not getting picked up and to get the ae.safetensors and not the VAE folder one lol.
@BIGR3D so all go in VAE folder? What goes in text_encoder folder?
@puma0000 Until some update addresses and changes things - nothing. As for right now, the files are not being read from that directory by default.
@svooooosh Clip_L for that problem.
So much for this
Is there any lora version?
Details
Files
Available On (1 platform)
Same model published on other platforms. May have additional downloads or version variants.