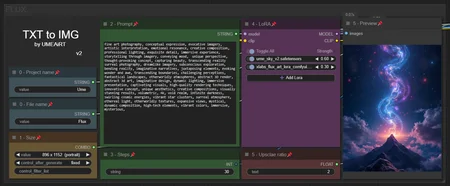
✨ FLUX — Text to Image — Simple Workflow
A clean, all-in-one FLUX text-to-image workflow built entirely with the UmeAiRT Toolkit for ComfyUI.
Only 8 nodes. No spaghetti wires. Just load your model, write your prompt, and hit generate.
⚠️ IMPORTANT — Nodes 2.0 Required
This workflow is built for the Nodes 2.0 (Vue) interface of ComfyUI. If you don't enable it, the workflow may have display problems.
How to activate Nodes 2.0:
Open ComfyUI
Go to Settings (⚙️ icon, bottom-left)
Find "Use Nodes V2 (Vue)" and toggle it ON
Refresh the page
Load the workflow
If you prefer the classic interface, check out my Legacy version of this workflow instead (link).
🎯 Features
Text-to-Image generation
Automatic download of models in auto version
Built-in SeedVR2 upscaler — high-quality tiled upscaling (toggleable on/off) Slower than a classic upscaler, but significantly better quality
Full metadata embedding — your images are saved with all generation parameters, ready for online publishing and remixing
3 LoRA slots — with individual on/off toggles and strength control and you can connect as many other lora modules to each other for as many LoRA as you want.
📦 Custom Node Required
Only one custom node to install:
Install via ComfyUI Manager (search "UmeAiRT") or use the UmeAiRT Auto-Installer.
The Toolkit packages everything internally — upscaler, face detailer, metadata saver. No other custom nodes needed.
📂 Files you need (in manual version)
for "base" version :
Model : flux1-dev-fp8.safetensors or flux1-dev-fp16.safetensors
in ComfyUI\models\diffusion_models
CLIP : clip_l.safetensors
in ComfyUI\models\clip
for GGUF version :
Model : Q8, Q6, Q5, Q4, Q3
in ComfyUI\models\unet
CLIP : Q8, Q6, Q5, Q4, Q3
in ComfyUI\models\clip
Common Files :
Text encoder : t5xxl_fp8_e4m3fn.safetensors or ViT-L-14-TEXT-detail-improved-hiT-GmP-TE-only-HF.safetensors
VAE : ae.safetensors
in ComfyUI\models\vae
Description
Reforged, add GGUF support
FAQ
Looks like we don't have an active mirror for this file right now.
CivArchive is a community-maintained index — we catalog mirrors that volunteers upload to HuggingFace, torrents, and other public hosts. Looks like no one has uploaded a copy of this file yet.
Some files do get recovered over time through contributions. If you're looking for this one, feel free to ask in Discord, or help preserve it if you have a copy.