✨ FLUX — UltimateSD Upscale — Simple Workflow
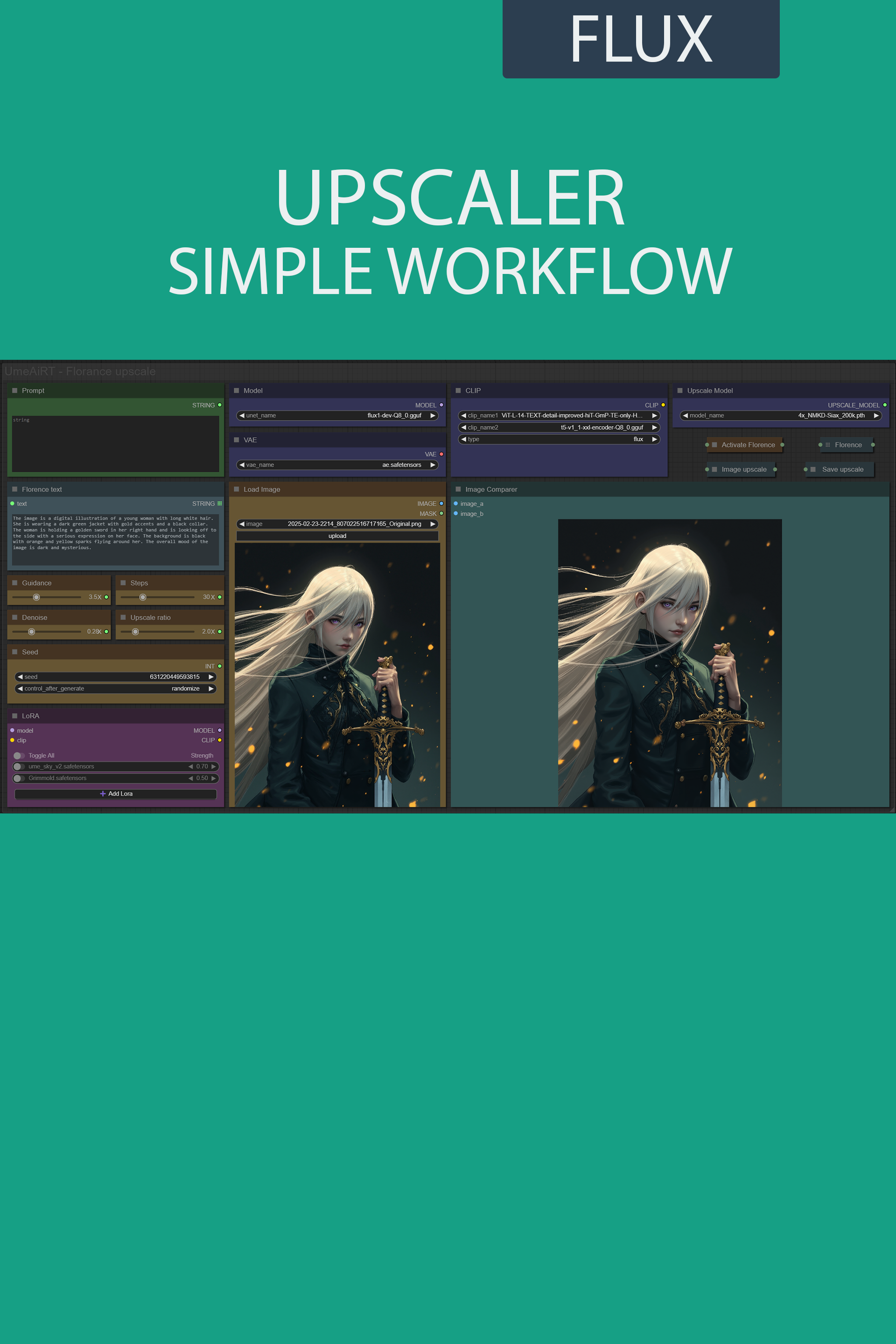
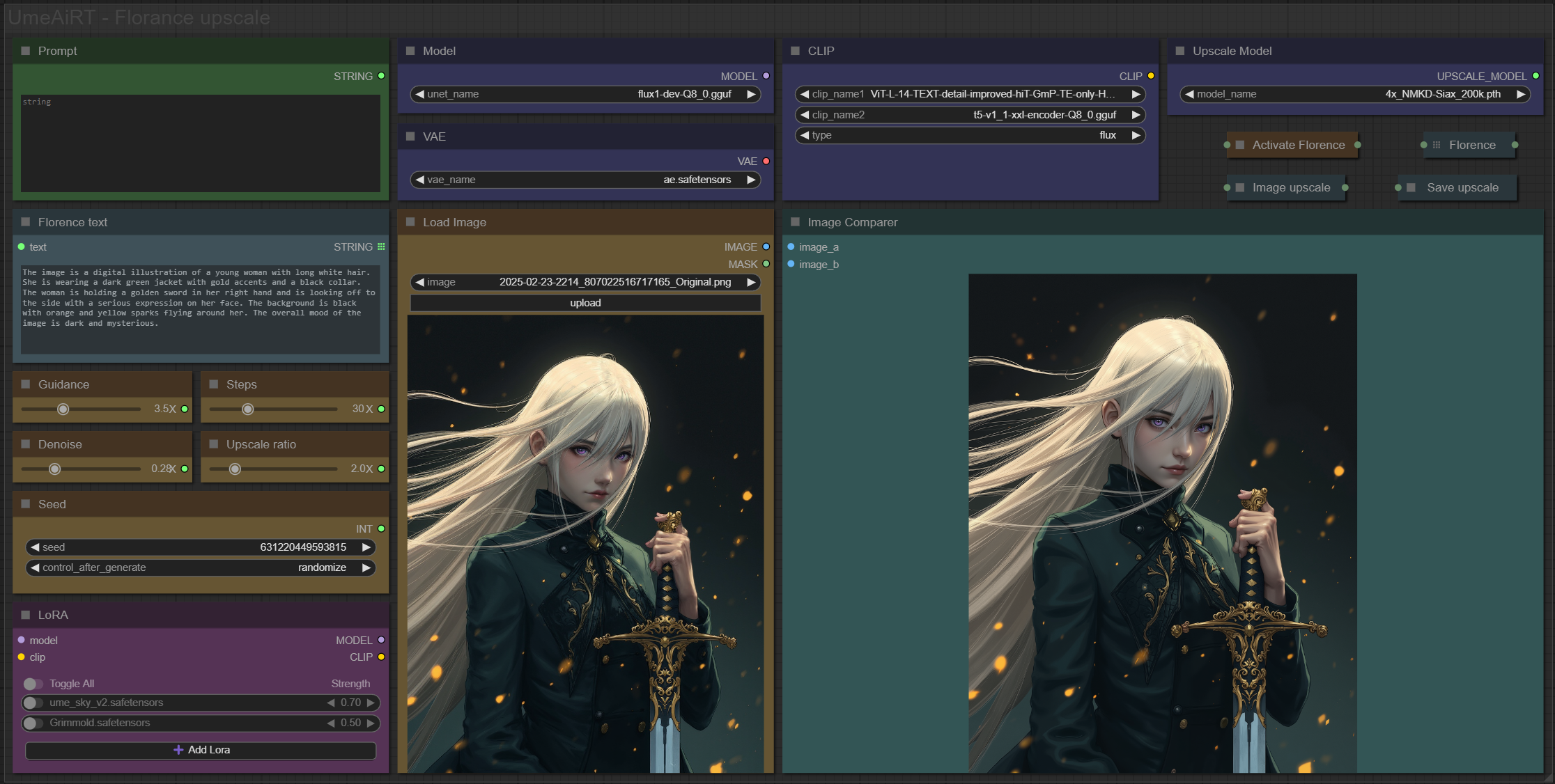
A clean, all-in-one FLUX UltimateSD Upscale workflow built entirely with the UmeAiRT Toolkit for ComfyUI.
Only 6 nodes. No spaghetti wires. Just load your model, write your prompt, and hit generate.
⚠️ IMPORTANT — Nodes 2.0 Required
This workflow is built for the Nodes 2.0 (Vue) interface of ComfyUI. If you don't enable it, the workflow may have display problems.
How to activate Nodes 2.0:
Open ComfyUI
Go to Settings (⚙️ icon, bottom-left)
Find "Use Nodes V2 (Vue)" and toggle it ON
Refresh the page
Load the workflow
If you prefer the classic interface, check out my Legacy version of this workflow instead (link).
📦 Custom Node Required
Only one custom node to install:
Install via ComfyUI Manager (search "UmeAiRT") or use the UmeAiRT Auto-Installer.
The Toolkit packages everything internally — upscaler, face detailer, metadata saver. No other custom nodes needed.
📂 Files you need (in manual version)
for "base" version :
Model : flux1-dev-fp8.safetensors or flux1-dev-fp16.safetensors
in ComfyUI\models\diffusion_models
CLIP : clip_l.safetensors
in ComfyUI\models\clip
for GGUF version :
Model : Q8, Q6, Q5, Q4, Q3
in ComfyUI\models\unet
CLIP : Q8, Q6, Q5, Q4, Q3
in ComfyUI\models\clip
Common Files :
Text encoder : t5xxl_fp8_e4m3fn.safetensors or ViT-L-14-TEXT-detail-improved-hiT-GmP-TE-only-HF.safetensors
VAE : ae.safetensors
in ComfyUI\models\vae
Description
Completely reworked version, fewer modules needed, new UI and compatible with the latest version of ComfyUI.
FAQ
Comments (2)
This is the best upscale workflow I've found here on Civitai. However, it has a problem: when unzipped, it works very well, but after a few executions or configurations in Lora, it shows the following error. I don't know what it is, but if you fix this, it will be perfect. I also have a suggestion: create a workflow replacing "Save upscale" with "Save Image," because "Save upscale" isn't respecting the custom save location and is putting everything into the ComfyUI output folder. If you can make these adjustments and corrections, it will be perfect.
The error:
Prompt execution failed
Prompt outputs failed validation: ConditioningZeroOut: - Return type mismatch between linked nodes: conditioning, received_type(CLIP) mismatch input_type(CONDITIONING) CLIPTextEncode: - Return type mismatch between linked nodes: clip, received_type(STRING) mismatch input_type(CLIP) GetImageSizeAndCount: - Return type mismatch between linked nodes: image, received_type(CONDITIONING) mismatch input_type(IMAGE) DownloadAndLoadFlorence2Model: - Value not in list: precision: 'sdpa' not in ['fp16', 'bf16', 'fp32'] - Return type mismatch between linked nodes: model, received_type(IMAGE) mismatch input_type(['microsoft/Florence-2-base', 'microsoft/Florence-2-base-ft', 'microsoft/Florence-2-large', 'microsoft/Florence-2-large-ft', 'HuggingFaceM4/Florence-2-DocVQA', 'thwri/CogFlorence-2.1-Large', 'thwri/CogFlorence-2.2-Large', 'gokaygokay/Florence-2-SD3-Captioner', 'gokaygokay/Florence-2-Flux-Large', 'MiaoshouAI/Florence-2-base-PromptGen-v1.5', 'MiaoshouAI/Florence-2-large-PromptGen-v1.5', 'MiaoshouAI/Florence-2-base-PromptGen-v2.0', 'MiaoshouAI/Florence-2-large-PromptGen-v2.0']) - Value not in list: attention: '' not in ['flash_attention_2', 'sdpa', 'eager'] Florence2Run: - Value not in list: task: '3' not in ['region_caption', 'dense_region_caption', 'region_proposal', 'caption', 'detailed_caption', 'more_detailed_caption', 'caption_to_phrase_grounding', 'referring_expression_segmentation', 'ocr', 'ocr_with_region', 'docvqa', 'prompt_gen_tags', 'prompt_gen_mixed_caption', 'prompt_gen_analyze', 'prompt_gen_mixed_caption_plus'] - Value 663978632896843 bigger than max of 4096: max_new_tokens - Failed to convert an input value to a INT value: num_beams, None, int() argument must be a string, a bytes-like object or a real number, not 'NoneType'
I have the same issue. It becomes quickly unusable. Any fixes?