










Description
⚠️ Note: Please use CFG = 11 for model effect testing
Complete release report: https://nieta-art.feishu.cn/wiki/ARWLw99w7ikjaSkoV99cxmsOn5g
Supported first-step image(before highres fix)generation ratios:
'1:1': [1024, 1024], '3:4': [896, 1152], '4:3': [1152, 896], '16:9': [1344, 768], '9:16': [768, 1344],
1. Overview
- Introducing Neta Art XL V1.0, the easiest-to-use SDXL model to date.
- Keywords: Best character coverage, vivid storytelling, diverse styles, stable human anatomy.
- Main motivation: Better multi-style stability and human anatomy for character visual storytelling purposes: providing prompt sorting rules, easier to follow Prompts; striking a good balance between better knowledge and stability. Maintaining the aesthetic upper standards of multiple anime art styles while keeping the output baseline attractive to the general user. Less use of character/style/artist Lora, making it easier to leverage static model acceleration technologies (like TensorRT).
Contains 13500+ character reference list: please refer to A3.1 character list and training data information in the report

Prompt Guide
To avoid ambiguity in text prompts and to leave room for very complex scenes (such as multi-character scenes), we found that enforcing order in prompts can bring better instruction-following behavior (learning from NAI3 / Animagine3 / AIDXL!). Specifically, we recommend the following order in Neta Art XL:
Tag order: Subject (1boy / 1girl) -> Character name (a girl named frieren from sousou no frieren series) -> Artist (by xxx) -> race (elf) -> Camera combo (cowboy shot) -> Style (impasto style) -> Theme (fantasy theme) -> Main environment description (in the forest, at day) -> Background description (gradient background) -> Action(sitting on ground) -> Expression (is expressionless) -> Main character features (white hair) -> Body features (twintails, green eyes, parted lip) -> Clothing features (wearing a white dress) -> Accessories (frills) -> Other appendages (a cat) -> Secondary scene (grass, sunshine) -> Aesthetics (beautiful color, detailed, aesthetic) -> Quality words ((best quality:1.3))
Negative prompt words: (worst quality:1.3), low quality, lowres, messy, abstract, ugly, disfigured, bad anatomy, draft, deformed hands, fused fingers, signature, text, multi views
Sampler parameters: Eular a normal as default, 28+ steps recommended.

Prompt guidance coefficient CFG scale
Another advantage of Neta Art XL is that it supports a very wide range of prompt guidance coefficients CFG scale (supports 5 - 20, while the general model is 7 - 9). Although we have found through experience that higher CFG brings more details and higher contrast, usually using CFG 9 - 14(important!)can achieve the best results.
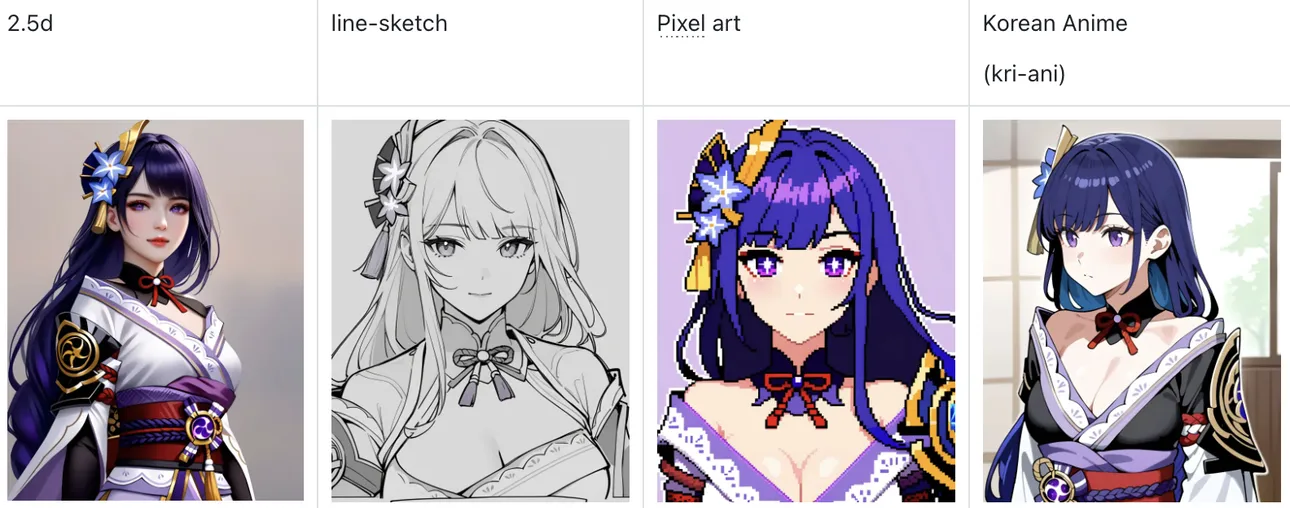
2. Highlights: Coexistence of Multiple Styles
We have carefully selected 13 styles with good orthogonality and commonly used in many scenarios, and their rationality is proven by over 30 million generations by Neta AI users.
Having orthogonal styles means each style is actually different from the others, allowing you to easily combine and createnew mixed styleswithout interference.



Neta Art XL also includes a large collection of artist styles, activated using the "by xxx" tag.
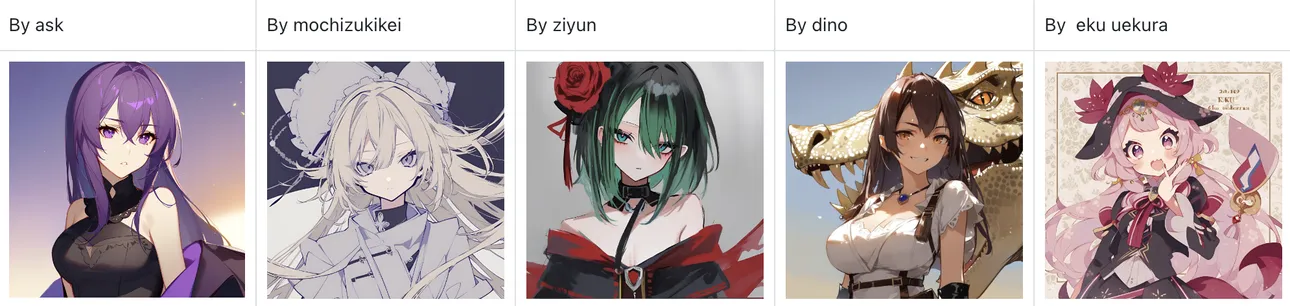
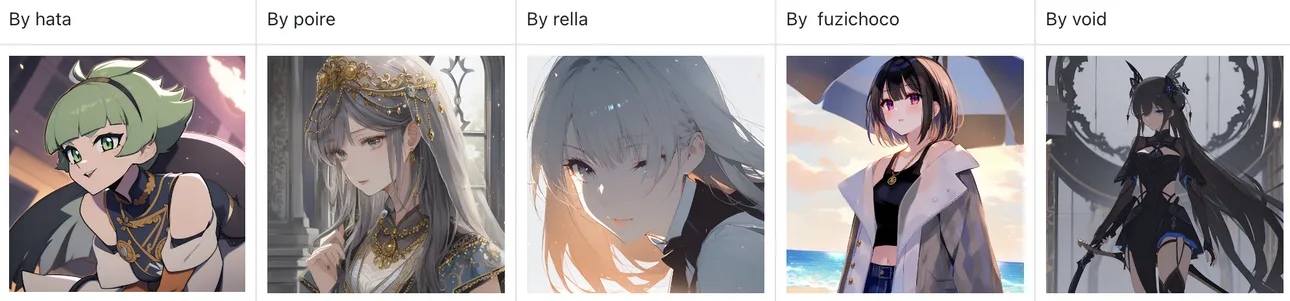
For reference, AIDXL you can find more supported artists
3. For other displays, please refer to the report
https://nieta-art.feishu.cn/wiki/ARWLw99w7ikjaSkoV99cxmsOn5g

4. Terms of Use
- This model is developed by Neta.art Lab
- Collaborators:
- Euge: https://civitai.com/user/Euge_
- Tang Ren Lan: https://space.bilibili.com/8594480
- Chenkin: https://civitai.com/user/Chenkin
- Bo Dai: https://daibo.info/
- Acknowledgements and References:
- https://blog.novelai.net/introducing-novelai-diffusion-anime-v3-6d00d1c118c3
- https://cagliostrolab.net/posts/animagine-xl-v3-release
- https://civitai.com/models/269232/aam-xl-anime-mix
- https://civitai.com/models/124189/anime-illust-diffusion-xl
- https://github.com/deepghs/waifuc
- Model category: Diffusion-based text-to-image generation model
- Usage agreement: This model incorporates 0.05 CLIP and 0.15 UNet input layers from AnimagineXL 3.1, thus following the Fair AI Public License 1.0-SD. If you modify, merge, or further develop this model, you must open source the derived model.
9. Summary and Outlook
Drawbacks:
- Some characters are not well-fitted.
- Style activation is not obvious when prompts are long.
- Some styles appear grayish under low CFG and short prompts. Partial explanations can be found at https://civitai.com/articles/4969
- Future work:
- Prepare a larger training set and more knowledge-based data to improve character, style, and detail handling.
- We welcome others to join the discussion and provide suggestions to contribute to the model's improvement.
Neta Art XL 2.0 is coming soon. Please stay tuned and test our products for free: http://nieta.art
- Bilibili: https://space.bilibili.com/505727005
- Xiaohongshu: https://www.xiaohongshu.com/user/profile/63f2ebf2000000001001e206
- Twitter: https://twitter.com/netaart_ai
- Civitai: https://civitai.com/user/nieta_art