













Description
2023.11.10 HelloWorld 2.0 Update
Everyone has been waiting for this. After going through various challenges and setbacks, HelloWorld 2.0 can finally be presented in a satisfactory state. The major differences between HelloWorld 2.0 and 1.0 versions are as follows:
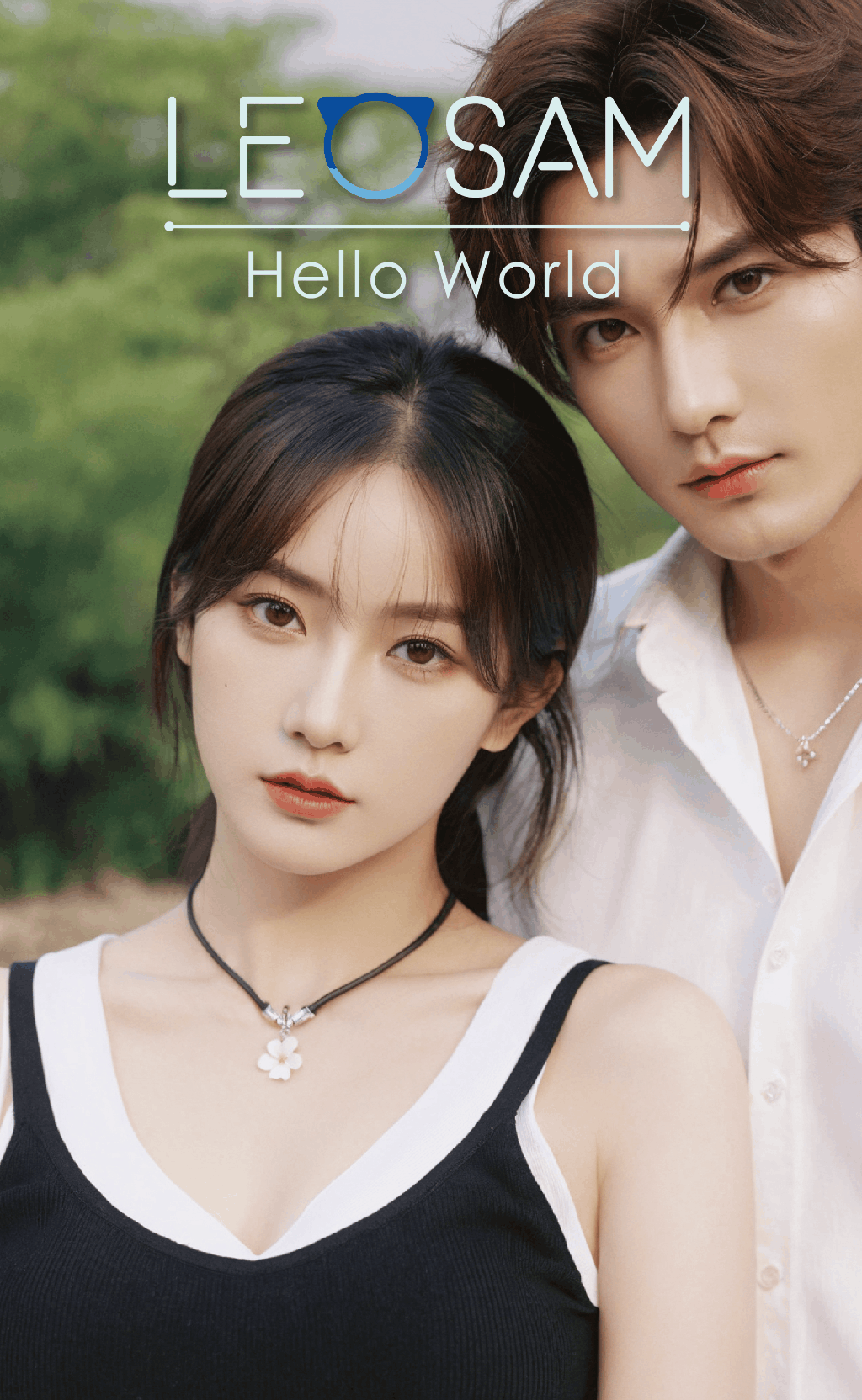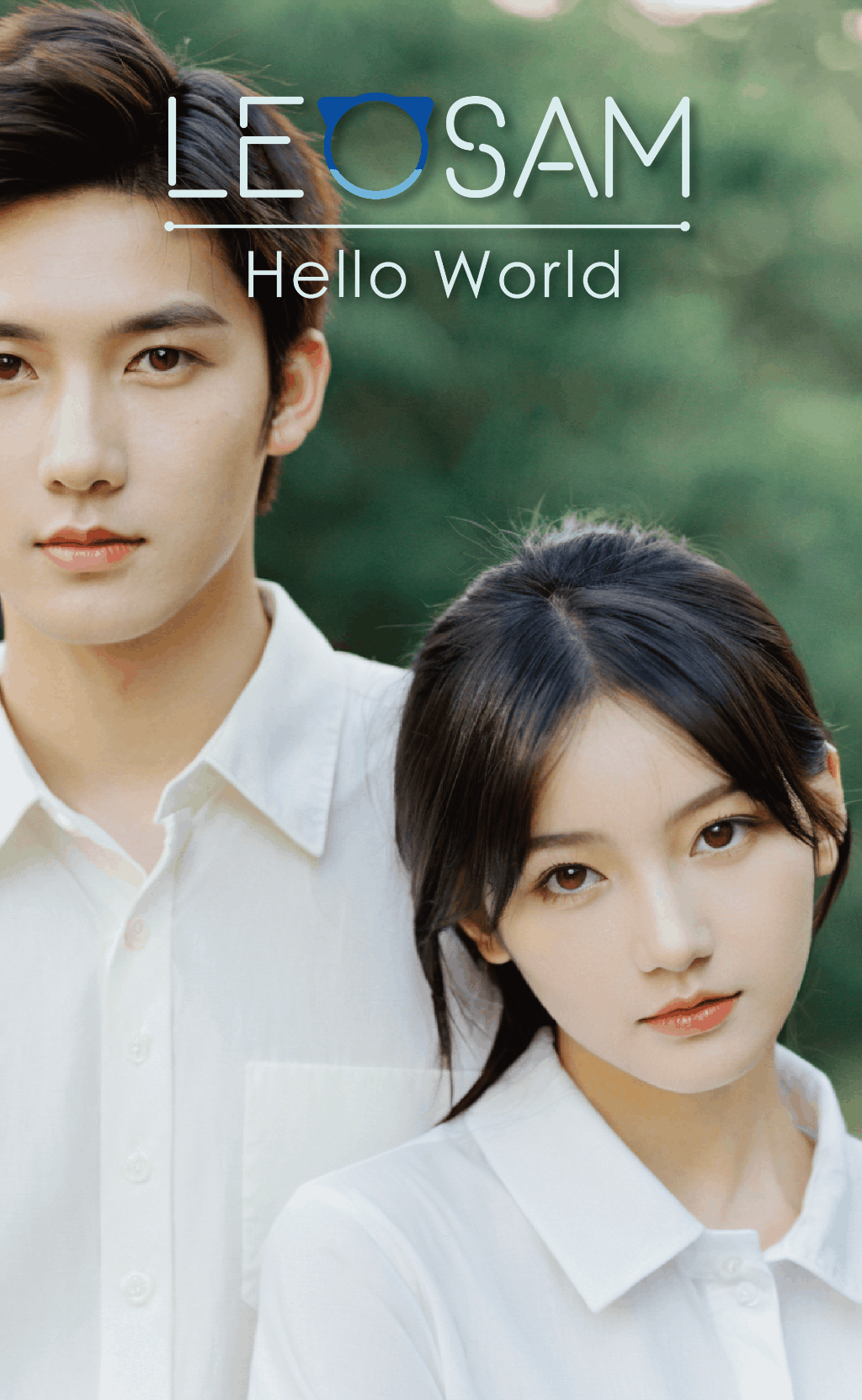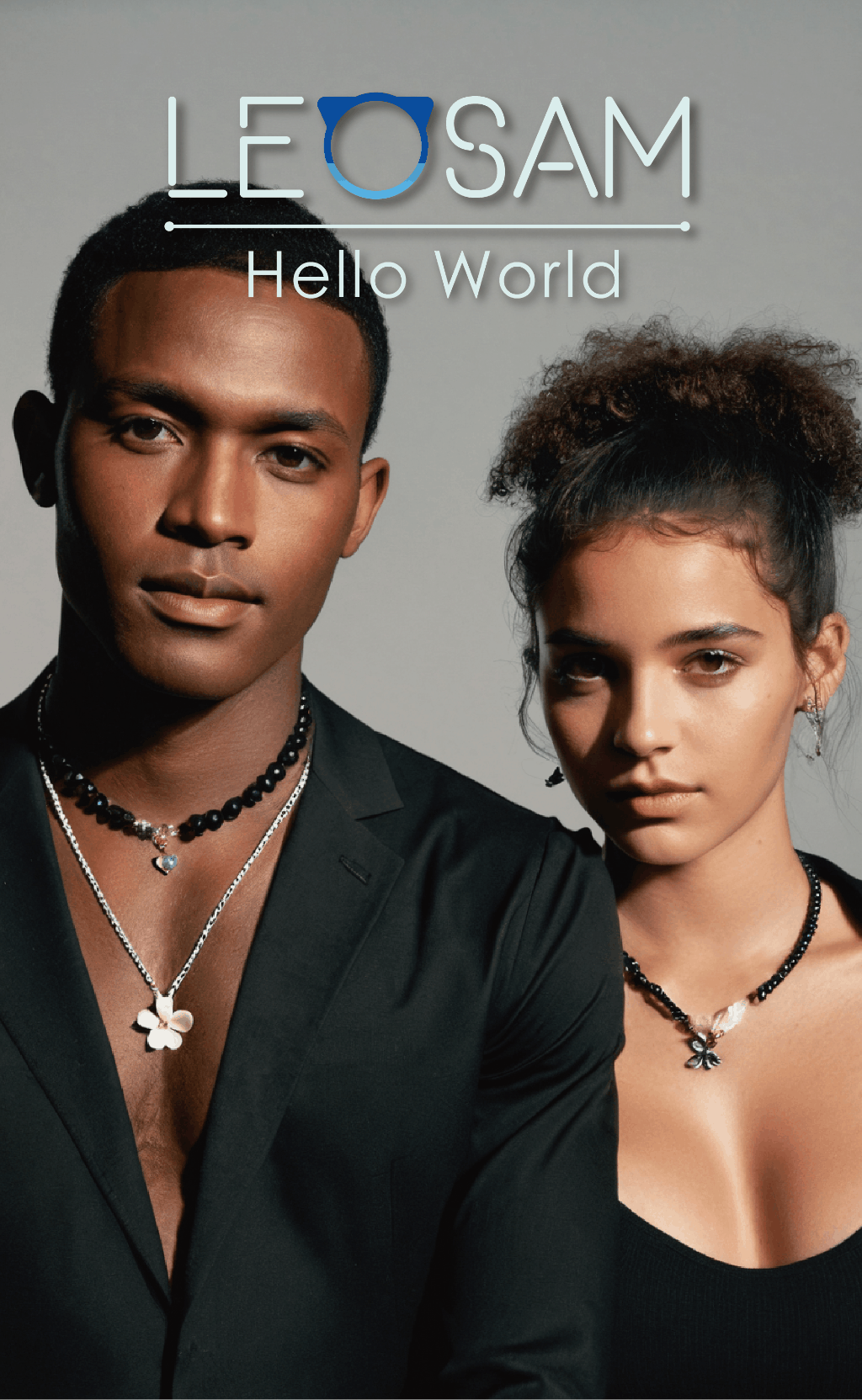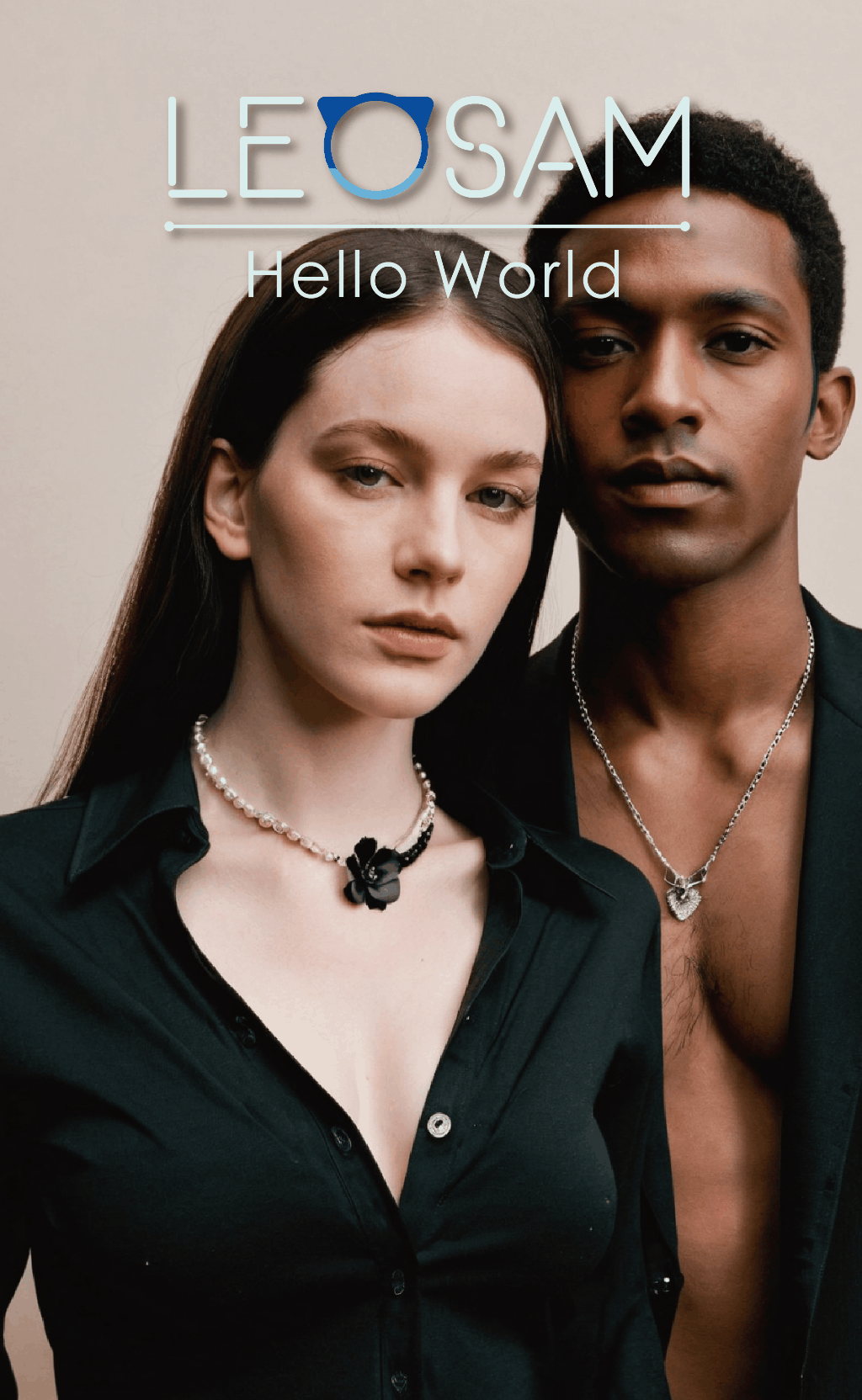
1. HelloWorld 2.0 performs equally well as the 1.0 version with trigger words when no* ***ng trigger words. The trigger word leogirl in version 1.0 was strongly associated with East Asian ethnicity. After removing trigger words, although high-frequency words like 1girl still often generated East Asian figures without specifying ethnicity, you can nowuse nationality, skin color, and other cues to specify ethnicity. For example, triggering effects for words like Chinese, Russian, Iranian, Jamaican, Kenyan, dark-skinned, and pale-skinned are listed below.

You can alsouse names from different countries and genders to obtain characters with different styles, such as Han Meimei (China), Sophie Martin (France), Priya Patel (India), Fatima Al-Hassan (Arab), and Wanjiru Mwangi (Kenya). These are just examples. There are many more cues and ways to play around with. Feel free to explore and share.

2. HelloWorld 2.0 balances image quality/color, offering more diverse style options. When used with leogirl in version 1.0, images often had a strong vintage feel. HelloWorld 2.0 no longer enforces this vintage feel and allows for customization through quality-related cues. Some words that have shown good triggering effects include:
high-end fashion photoshoot,product introduction photo,popular Korean makeup,aegyo sal,Sharp High-Quality Photo,studio light,medium format photo,Mamiya photography,analog film,Medium Portrait with Soft Light,real-life image,refined editorial photograph,raw photo,real photo,Scanned Photo,film still
These words have different color effects as shown below:

3. HelloWorld 2.0's training set has significantly increased the proportion of full-body shots, aiming to improve the results when generating full-body or long-distance portraits. Although there has been improvement compared to version 1.0, there is still a strong suggestionto avoid using adetailer during full-body image generation. For players with sufficient memory (24g), it issuggested to enhance image resolution by 1.5 times, which significantly improves facial details.
During the development of this version, improvements and experiments were made in various aspects. While some improvements may not be obvious, the main enhancements are listed for reference:
1. The training materials were further refined, with a total of 500 training sets + 1500 regular sets. The proportion of full-body shots, male portraits, high-quality images, and images of different ethnicities has been increased.
2. The word library used for trigger words originally contained about 110,000 phrases, but many errors, garbled text, and duplicate phrases were present. By utilizing GPT4 for batch modifications and multiple rounds of testing with manual addition and removal of tags, the word library was reduced to about 40,000 phrases. It also added a large number of phrases related to photography, portraits, and China.
3. Extensive comparison tests were conducted, including a. different training effects between training the SDXL large model with dreambooth under the same training set and training SDXL lora first before merging into the large model; b. differences in training effects under different optimization methods such as adafactor, adamW8bit, prodigy, different LR schedulers, learning rates, and batch sizes; c. differences in training effects with and without different data augmentation methods; d. training effects with different SDXL base models.
4. The training set underwent batch image processing before binning, compressing and cropping images into the following 7 target resolution groups to improve training effects under large batch sizes (although improvements were limited): (768, 1360), (832, 1248), (8**, 1184), (1024, 1024), (1184, 8**), (1248, 832), (1360, 768).
These are the main updates in HelloWorld 2.0. While this version encountered many challenges during the update process, the upside is the insight gained into training the SDXL large model, making future updates smoother.
The new version has made progress compared to 1.0, but there are still areas for improvement.Feedback and suggestions are welcomed for continuous improvement, as they are crucial for the model's progress! Thank you for your long-standing support!
-------------
Welcome to the SDXL large model HelloWorld new world! After two weeks of trial and error and debugging, I am finally able to release this version that I am quite satisfied with! I believe HelloWorld new world can greatly improve the portrait capabilities of SDXL.
Compared to SD1.5, the SDXL model has made a qualitative leap in semantic understanding of trigger words and image information. This brings four differences in usage from the traditional SD1.5 model:
1. HelloWorld supports direct output of 1024*1024 resolution images without the need for high-resolution enlargement. Currently, it surpasses the SD1.5 version in quality for close-up portraits, but flaws still exist in distant portraits. Therefore, it is recommended to use the ADetailer function in lib online image generation to correct distant facial issues.
2. Unlike the SD1.5 large model, which usually does not include trigger words,make sure to use the trigger word leogirl when using Hello World to ensure the SDXL model triggers the training set effects more stably.
3. You can now use simpler cue words for image output, and it is also recommended to trynatural language prompts, as they lead to better results when producing realistic AI photos. You can combine usage with large language models like chatGPT, enabling GPT to compose fluent descriptions from scattered label-style cues or to describe desired scenes in English.
4. SDXL greatly expands the scope of stable diffusion in virtual photography, with the large amount of information in the base model supporting the output of many movie poster-level AI images. I will showcase some sample images in the sharing area. I hope that while continuing the tradition of generating beautiful images with SD1.5, you can also explore and experiment with SDXL's application in more virtual photography domains. Moreover, liblib is currently hosting a virtual photography competition. I can confidently say that in the field of lighting and shadows, the SDXL model deals a heavy blow to the SD1.5 model, therefore, I encourage all drawing enthusiasts to actively participate using this model!
The making of HelloWorld new world encountered many challenges and received help from many experts. In-depth collaboration and communication with the author of XXMix, YeyaoXiao, were a crucial step for the model's success. Dragon expert's development of the DB training script based on Kohya's training package significantly reduced my testing time. I also gained valuable insights through exchanges with xiaolxl, the author of the national wind 4 model. I am grateful for all the help!
There are still many areas for improvement in HelloWorld. I welcome your feedback and suggestions in the comment section, as they are essential for the model's future improvement! The model is now available for download, and the 2.0 version is currently in intense production, so stay tuned!
In conclusion, welcome to Hello World new world, and I wish you a pleasant journey in the virtual universe created by SDXL!!
🤝Lastly, a little advertisement: If you have model customization or other collaboration needs, please contact me via WeChat: 13439222668. Please briefly state your purpose as time is valuable and no chitchat, thank you for your understanding!