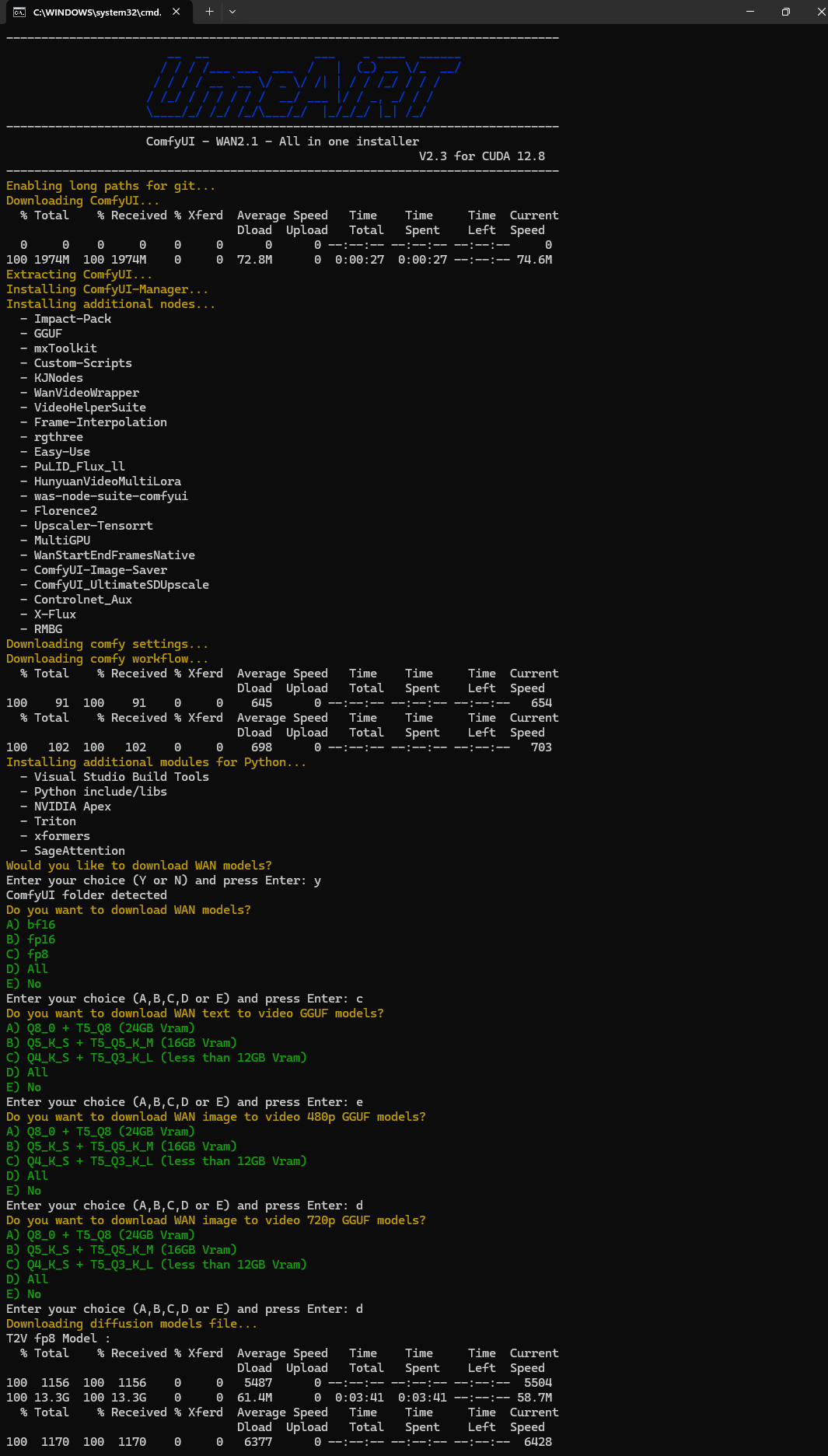
🚀 ComfyUI Auto-Installer — v5 (Python Rewrite)
Version 5 is a full rewrite from the ground up in Python, replacing all the PowerShell scripts from previous versions. It's cross-platform, faster, smarter, and now ships with a TUI manager, Docker images, and GPU-optimized inference out of the box.
If you are upgrading from the PowerShell version (v4.x), a one-command migration preserves all your models, outputs, and custom nodes: irm https://get.umeai.art/migrate.ps1 | iex
⚡ Quick Start (One-Liner)
Windows (PowerShell):
irm https://get.umeai.art/comfyui.ps1 | iexLinux / macOS:
curl -fsSL https://get.umeai.art/comfyui.sh | sh
Only requires Git — everything else (Python, uv, dependencies) is handled automatically.
✨ What's New in v5
Full Python rewrite — no more PowerShell dependency
Cross-platform — Windows, Linux, macOS, and Docker
TUI Manager — interactive terminal UI to launch, update, download models, and configure settings
VRAM-aware model catalog — 7 model families with quantization recommendations based on your GPU
GPU auto-detection — NVIDIA (CUDA 13.0/12.8), AMD (ROCm/DirectML), Apple Silicon (MPS)
SageAttention 2 + 3 — pre-compiled wheels including RTX 50XX Blackwell support
One-click update — update ComfyUI, all nodes, and dependencies with a single command
Model security scanner — detects malicious pickle code in .ckpt/.pt files
Junction architecture — models and outputs persist independently from ComfyUI updates
Docker ready — 4 image variants including a cloud version with JupyterLab for RunPod
📋 Prerequisites
Git
GPU: NVIDIA (CUDA 12.x+), AMD (Radeon RX 6000+), or Apple Silicon (M1+)
Internet connection
Note: Python is automatically installed via uv if not present. No manual Python setup required.
🎨 Model Catalog (7 Families)
Interactive model downloader with VRAM-based recommendations (★ markers) and SHA-256 integrity checks. Each bundle offers multiple quantization variants (fp16, fp8, GGUF Q3→Q8). Downloads are accelerated via aria2c with HuggingFace + ModelScope fallback:
FLUX (Image): Dev, Fill
Z-IMAGE (Image): Turbo
WAN 2.1 (Video): T2V, I2V 480p
WAN 2.2 (Video): I2V, Fun Inpaint, Fun Camera
HiDream (Image): Dev
QWEN (Image Edit): Image Edit
LTX-2 (Video + Audio): Dev
🧩 34 Custom Nodes Included
Additive manifest — never removes user-installed nodes.
Core (always installed): ComfyUI-Manager
UmeAiRT Tier: ComfyUI-UmeAiRT-Sync, ComfyUI-UmeAiRT-Toolkit, ComfyUI-Crystools, ComfyUI-nunchaku
Full Tier (all of the above +): ComfyUI-Impact-Pack, ComfyUI-Impact-Subpack, ComfyUI-GGUF, ComfyUI-mxToolkit, ComfyUI-Custom-Scripts, ComfyUI-KJNodes, ComfyUI-WanVideoWrapper, ComfyUI-VideoHelperSuite, ComfyUI-Frame-Interpolation, rgthree-comfy, ComfyUI-Easy-Use, ComfyUI-HunyuanVideoMultiLora, ComfyUI-Florence2, ComfyUI-MultiGPU, ComfyUI-WanStartEndFramesNative, ComfyUI-Image-Saver, ComfyUI_UltimateSDUpscale, comfyui_controlnet_aux, x-flux-comfyui, ComfyUI-Detail-Daemon, wlsh_nodes, ComfyUI_essentials, ComfyUI-wanBlockswap, Derfuu_ComfyUI_ModdedNodes, ComfyUI_LayerStyle, ComfyUI-Upscaler-Tensorrt, comfyui-vrgamedevgirl, comfyui-int-and-float, was-node-suite-comfyui
⚙️ GPU Optimizations (Auto-Installed)
PyTorch 2.10: CUDA 13.0/12.8, ROCm 7.1, DirectML, MPS
xformers: Memory-efficient attention
Triton: triton-windows / triton (Linux)
SageAttention 2: Unified ABI3 wheels (Windows), per-arch SM80–SM100 (Linux)
SageAttention 3: RTX 50XX Blackwell native (Windows + Linux)
FlashAttention: Linux + NVIDIA only
Nunchaku & InsightFace: Pre-compiled wheels
Additional Python packages auto-installed: facexlib, onnxruntime-gpu, nvidia-ml-py, cupy-cuda13x, imageio-ffmpeg, hf_xet, cython, rotary_embedding_torch, blend_modes, segment_anything, gguf, and more.
🐳 Docker Support
Requires Docker and an NVIDIA GPU: docker run --gpus all -p 8188:8188 -v comfyui-data:/data registry.gitlab.com/umeairt-studio/comfyui-auto_installer-python:latest
latest: ~4 GB — Ready to go with pre-installed PyTorch
latest-cloud: ~4.5 GB — + JupyterLab for RunPod / cloud
latest-lite: ~2 GB — Minimal (installs PyTorch on first run)
latest-lite-cloud: ~2 GB — Lite + JupyterLab
🔒 Security
No external script execution — all logic is internalized
Secure subprocess calls — no shell=True
HTTPS only — all URLs validated
SHA-256 integrity checks on all model downloads
Pickle model scanner — detects malicious code in .ckpt/.pt files
Zip-slip prevention on archive extraction
CI runs Bandit + pip-audit on every push
📂 Post-Installation
Three launcher scripts are generated:
UmeAiRT-Start-ComfyUI: Launch (Performance mode + SageAttention)
UmeAiRT-Start-ComfyUI_LowVRAM: Launch with --lowvram --fp8 for ≤8 GB VRAM
UmeAiRT-Manager: TUI manager (update, download, reinstall, settings)
🔗 Links
Source code: GitLab (https://gitlab.com/UmeAiRT-Studio/ComfyUI-Auto_installer-Python)
Mirror: Codeberg (https://codeberg.org/UmeAiRT)
Ecosystem: UmeAiRT Studio (https://umeai.art)
Description
Fix for APEX,
ComfyUI updated to 0.3.31,
New FLUX workflow and custom nodes included.
FAQ
Comments (27)
น่าสนใจ
Can I use new installer to update my previous installation without damaging it?
No, this script is not designed to update an existing installation. You can use it to install an new updated comfyui and then copy your data.
@UmeAiRT Additionally added nodes, models and usr folders will be enough?
@UmeAiRT I also installed this but i already have a portable version of ComfyUI. How can i uninstall it or move it to another drive (he put my installation in system32 folder)?
@Cejix If it goes into system32, it means that you are running the script "as administrator" which makes Windows place itself there. And for your question there is no "uninstallation" for a portable version, if you delete the folder nothing remains.
@UmeAiRT Thanks for your answer. So how can i managed a custom directory for the installation when i run the script ?
Im on a 5090 and I get this error:
RuntimeError: CUDA error: no kernel image is available for execution on the device CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect. For debugging consider passing CUDA_LAUNCH_BLOCKING=1 Compile with TORCH_USE_CUDA_DSA to enable device-side assertions.
This is with Sageattention BTW
I came here to post this exact same error :) I'm also on a 5090
CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1
Compile with TORCH_USE_CUDA_DSA to enable device-side assertions.
, using pytorch attention instead.
If I run with SageAttention it works, but it seems slow.
Hope you can help - THANK YOU :)
I must admit that since I don't have any 50XX graphics cards, I rely on other users' tests to find out what works with them. There is a good chance that this comes from my compilation of xformer which is not very stable on 50XX, it seemed to work with my beta testers but it is complicated to do more testing without any hardware of the type.
Getting the same error on a 5080. CUDA error: no kernel image is available for execution on the device..
I think the Author is correct. I was getting this error as being from _C_flashattention.pyd which is in the compilation of xformers. I was able to get an extended error using the default run_nvidia_gpu.bat with torch compile and tea cache on.
```
CUDA error: no kernel image is available for execution on the device
CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1 Compile with TORCH_USE_CUDA_DSA to enable device-side assertions.
Exception raised from c10_cuda_check_implementation at C:\actions-runner\_work\pytorch\pytorch\pytorch\c10\cuda\CUDAException.cpp:43 (most recent call first):
00007FFC146A2C2400007FFC146A2B80 c10.dll!c10::Error::Error [<unknown file> @ <unknown line number>]
00007FFC146A170A00007FFC146A16B0 c10.dll!c10::detail::torchCheckFail [<unknown file> @ <unknown line number>]
00007FFC3F5C6BBF00007FFC3F5C68B0 c10_cuda.dll!c10::cuda::c10_cuda_check_implementation [<unknown file> @ <unknown line number>]
00007FF9F17B7CBE00007FF9F172D290 \_C\_flashattention.pyd!PyInit__C_flashattention [<unknown file> @ <unknown line number>]
```
Uninstalling xformers and installing it again with python.exe -m pip install -U xformers --index-url https://download.pytorch.org/whl/cu128 got it working for me
@Fuzzydemon Oh that's awesome. I'll give it a shot. I had just removed xformers from the python libs (which I think broke upscaling) but I was able to do the basic stuff.
Reinstalling xformers as Fuzzydemon said worked for me as well.
I changed the installation of xformers with this solution in the new version, if someone could check if this fixes the problem
@UmeAiRT I'll try it _ no work
A clean install with version 2.4 worked well for me on a 5090. I tested both GGUF I2V and TXT2IMG without any errors. Some models, like clip_vision_h, initially failed to download and appeared as 1KB files in the folder. I downloaded those manually, and everything is running smoothly now.
Im new to all this - how do I load workflows? Im not sure what to start reading to figure this out
There are thousands of videos on YouTube, that's how I learned.
Also saying please and thank you might help you ;)
@skpManiac While I believe in being polite - that answer will not get a "thank you" lol - I did a google search and had a hard time. I ended up figuring it out on my own.
Is v2.3 needed because there was an issue with APEX in v2.2? Can I self-fix this issue in v2.2 or how should I check?
It's only a fix for using PuLID workflow and yes you can just fix the 2.2 by fixing the built-in apex installation
RTX 5090 gives various errors...
I started a new topic so I can keep track of what I try to fix it ;) I know you're aware of the issue (as seen on other posts)I tried to fix it by firstly changing the security level, then running this PIP (which I use to fix Forge, so thought it may work)
torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/test/cu128 --force-reinstall
I can make videos if I run the sageattention.bat but I am totally unable to upscale. I've re-installed teacahce etc, but still get this error:
CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1
Compile with TORCH_USE_CUDA_DSA to enable device-side assertions.
, using pytorch attention instead.
If it helps, you can have remote access to my PC for a few hours after next week. :)
I checked your auto installer. Have to test more, but for starters comfyui manager button didn't show up even though the folder was in the custom nodes, so i had to reinstall it. In any case, amazing job here, this worked great and should be a must for comfyui newcomers.
EDIT: Let me add, this tool is mindblowing. Not only does it install everything that you need, but also comes preloaded with some absolutely mindblowing workflows for WAN and FLUX, something that i wasn't expecting. If you're new to comfyui or your installation is a mess with errors or other issues, make yourself a favour and make a clean install with this tool, you won't regret it.