🚀 ComfyUI Auto-Installer — v5 (Python Rewrite)
Version 5 is a full rewrite from the ground up in Python, replacing all the PowerShell scripts from previous versions. It's cross-platform, faster, smarter, and now ships with a TUI manager, Docker images, and GPU-optimized inference out of the box.
If you are upgrading from the PowerShell version (v4.x), a one-command migration preserves all your models, outputs, and custom nodes: irm https://get.umeai.art/migrate.ps1 | iex
⚡ Quick Start (One-Liner)
Windows (PowerShell):
irm https://get.umeai.art/comfyui.ps1 | iexLinux / macOS:
curl -fsSL https://get.umeai.art/comfyui.sh | sh
Only requires Git — everything else (Python, uv, dependencies) is handled automatically.
✨ What's New in v5
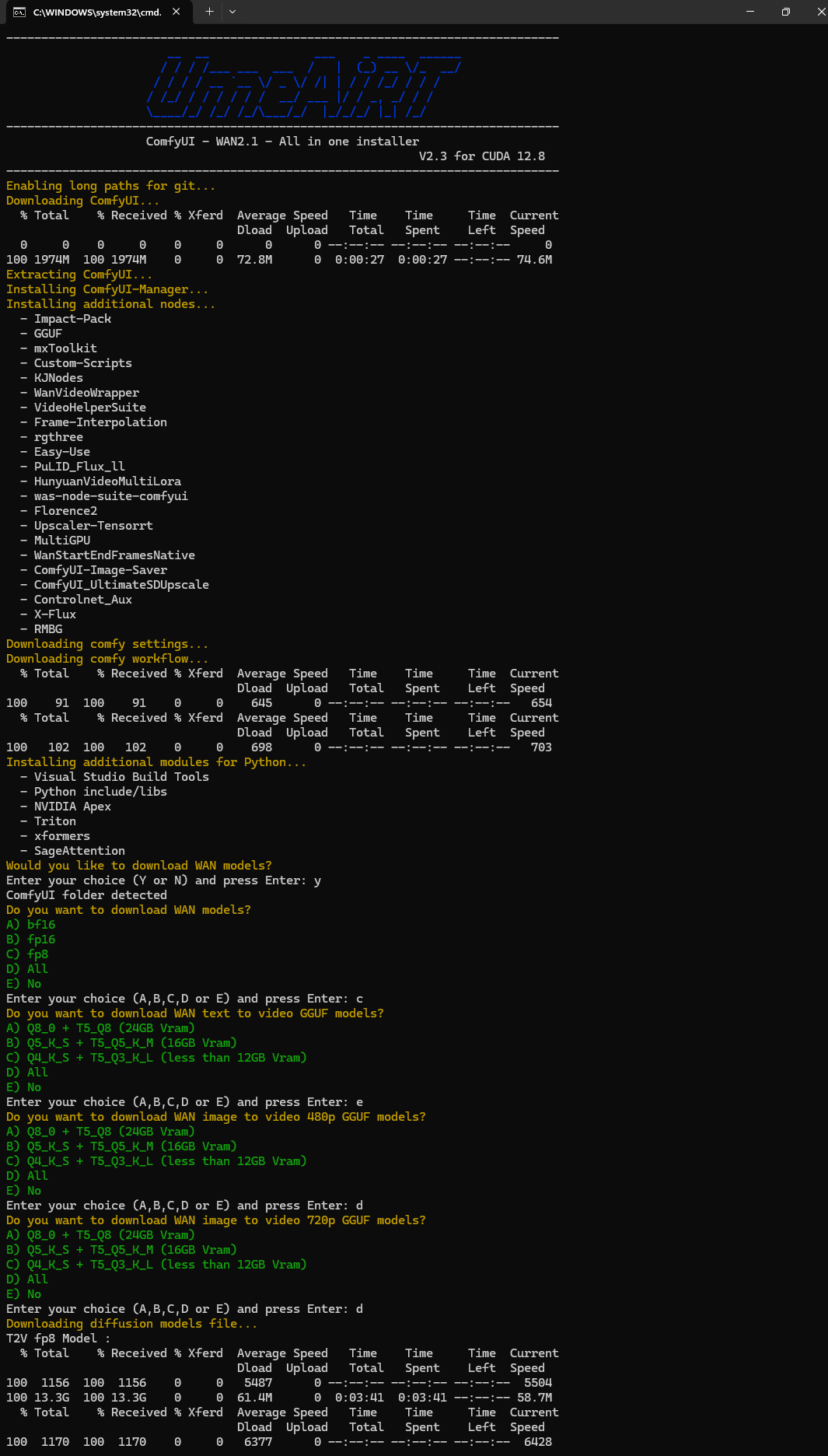
Full Python rewrite — no more PowerShell dependency
Cross-platform — Windows, Linux, macOS, and Docker
TUI Manager — interactive terminal UI to launch, update, download models, and configure settings
VRAM-aware model catalog — 7 model families with quantization recommendations based on your GPU
GPU auto-detection — NVIDIA (CUDA 13.0/12.8), AMD (ROCm/DirectML), Apple Silicon (MPS)
SageAttention 2 + 3 — pre-compiled wheels including RTX 50XX Blackwell support
One-click update — update ComfyUI, all nodes, and dependencies with a single command
Model security scanner — detects malicious pickle code in .ckpt/.pt files
Junction architecture — models and outputs persist independently from ComfyUI updates
Docker ready — 4 image variants including a cloud version with JupyterLab for RunPod
📋 Prerequisites
Git
GPU: NVIDIA (CUDA 12.x+), AMD (Radeon RX 6000+), or Apple Silicon (M1+)
Internet connection
Note: Python is automatically installed via uv if not present. No manual Python setup required.
🎨 Model Catalog (7 Families)
Interactive model downloader with VRAM-based recommendations (★ markers) and SHA-256 integrity checks. Each bundle offers multiple quantization variants (fp16, fp8, GGUF Q3→Q8). Downloads are accelerated via aria2c with HuggingFace + ModelScope fallback:
FLUX (Image): Dev, Fill
Z-IMAGE (Image): Turbo
WAN 2.1 (Video): T2V, I2V 480p
WAN 2.2 (Video): I2V, Fun Inpaint, Fun Camera
HiDream (Image): Dev
QWEN (Image Edit): Image Edit
LTX-2 (Video + Audio): Dev
🧩 34 Custom Nodes Included
Additive manifest — never removes user-installed nodes.
Core (always installed): ComfyUI-Manager
UmeAiRT Tier: ComfyUI-UmeAiRT-Sync, ComfyUI-UmeAiRT-Toolkit, ComfyUI-Crystools, ComfyUI-nunchaku
Full Tier (all of the above +): ComfyUI-Impact-Pack, ComfyUI-Impact-Subpack, ComfyUI-GGUF, ComfyUI-mxToolkit, ComfyUI-Custom-Scripts, ComfyUI-KJNodes, ComfyUI-WanVideoWrapper, ComfyUI-VideoHelperSuite, ComfyUI-Frame-Interpolation, rgthree-comfy, ComfyUI-Easy-Use, ComfyUI-HunyuanVideoMultiLora, ComfyUI-Florence2, ComfyUI-MultiGPU, ComfyUI-WanStartEndFramesNative, ComfyUI-Image-Saver, ComfyUI_UltimateSDUpscale, comfyui_controlnet_aux, x-flux-comfyui, ComfyUI-Detail-Daemon, wlsh_nodes, ComfyUI_essentials, ComfyUI-wanBlockswap, Derfuu_ComfyUI_ModdedNodes, ComfyUI_LayerStyle, ComfyUI-Upscaler-Tensorrt, comfyui-vrgamedevgirl, comfyui-int-and-float, was-node-suite-comfyui
⚙️ GPU Optimizations (Auto-Installed)
PyTorch 2.10: CUDA 13.0/12.8, ROCm 7.1, DirectML, MPS
xformers: Memory-efficient attention
Triton: triton-windows / triton (Linux)
SageAttention 2: Unified ABI3 wheels (Windows), per-arch SM80–SM100 (Linux)
SageAttention 3: RTX 50XX Blackwell native (Windows + Linux)
FlashAttention: Linux + NVIDIA only
Nunchaku & InsightFace: Pre-compiled wheels
Additional Python packages auto-installed: facexlib, onnxruntime-gpu, nvidia-ml-py, cupy-cuda13x, imageio-ffmpeg, hf_xet, cython, rotary_embedding_torch, blend_modes, segment_anything, gguf, and more.
🐳 Docker Support
Requires Docker and an NVIDIA GPU: docker run --gpus all -p 8188:8188 -v comfyui-data:/data registry.gitlab.com/umeairt-studio/comfyui-auto_installer-python:latest
latest: ~4 GB — Ready to go with pre-installed PyTorch
latest-cloud: ~4.5 GB — + JupyterLab for RunPod / cloud
latest-lite: ~2 GB — Minimal (installs PyTorch on first run)
latest-lite-cloud: ~2 GB — Lite + JupyterLab
🔒 Security
No external script execution — all logic is internalized
Secure subprocess calls — no shell=True
HTTPS only — all URLs validated
SHA-256 integrity checks on all model downloads
Pickle model scanner — detects malicious code in .ckpt/.pt files
Zip-slip prevention on archive extraction
CI runs Bandit + pip-audit on every push
📂 Post-Installation
Three launcher scripts are generated:
UmeAiRT-Start-ComfyUI: Launch (Performance mode + SageAttention)
UmeAiRT-Start-ComfyUI_LowVRAM: Launch with --lowvram --fp8 for ≤8 GB VRAM
UmeAiRT-Manager: TUI manager (update, download, reinstall, settings)
🔗 Links
Source code: GitLab (https://gitlab.com/UmeAiRT-Studio/ComfyUI-Auto_installer-Python)
Mirror: Codeberg (https://codeberg.org/UmeAiRT)
Ecosystem: UmeAiRT Studio (https://umeai.art)
Description
ComfyUI updated to 0.3.33,
now the different models are stored in sub-folders,
xformers fix for 50XX graphic card,
links fix for some models,
HiDream model and workflow included.
FAQ
Comments (10)
I'm trying to update your portable ComfyUI through the manager and I have version 0.3.30 now, I also tried to run the batch file on abde, there's a message like this and nothing KeyError: 'refs/remotes/origin/master'. It's also version 0.3.30, but as I understand it, version 0.3.33 is needed now?
Thanks for this, the results are great! I am running into some issues, 81 frame renders with low-res dimensions are taking as long as 5 hrs on my 4080 super. Would anyone have any tips?
Yes- when RAM thrashing occurs, your renders can take any length of time. 81 frames is too much- you need to limit yourself to no more than 61. I talk as someone who also has 16GB of VRAM, and understands the underlying issue.
This is the problem- the temporary output data, namely the frames of video you are rendering, need to remain in VRAM. But ComfyUI, being an utterly amateur project, has no conception of Computer Science based memory management. It treats all memory loads as equal, and therefore models which should be imported from system RAM as needs in blocks, fight for VRAM with your output data. In my experience, 61 frames of 640x480 (or the equivalent number of pixels) take 16GB of VRAM to the very limit. When this limit is crossed, linear render time becomes worse than exponential, as Comfy swaps out your output data with RAM, sometimes at a byte level- literally insane.
You will read again and again here that models should remain in VRAM. This is utterly wrong. Models should stream in block by block (this may add a few seconds per iteration, but when iterations are at 20 secs or worse, this overhead is nothing).
What you are looking for is linear time. Render 10 frames (at a given setting). Notice the time per frame. Then increase your frame amount, ensuring the time per frame stays the same. When the time goes crazy, you are at the very limit of what the memory management in a given workflow can achieve. You will need a better workflow to go to more frames,
if i use --use-sage-attention in command line, do I need to select 'auto' in sage attention node?
i get black generations if I select auto.
i have to select either fp16cuda or fp16triton to get results. fp8cuda gives black screen as well.
When ComyUI launches with Sageattention, it is working 'under the hood' when it can. The node options attempt to activate SA when ComfyUI hasn't been launched with it. In my experience, I just launch using SA, and leave the node settings alone.
There is no magic 'super' SA mode. Run a workflow with and without Comfy launching SA, and check a given render time. I have seen at best a doubling, but more commonly a 3 min render becomes 2.
The support of 'faster maths' methods is problematic because of the different Nvidia architectures, BUT also because of a potential major impact on render accuracy (a fact Nvidia loves to ignore). 16-bits are great. 8-bits need very careful use. Nvidia pushes 4-bits now, which isn't even properly implemented in Blackwell (better accumulation of 4-bit maths is needed), and requires first rate understanding of numerical analysis to design decent algorithms- currently beyond the skill level of the enthusiastic amateurs working in this field.
TLDR: there is no current magic wand. SA will give a boost in many situations, but there is no magic setting to make it suddenly much more effective!
For me:
Turn off pytorch and keep on sageattention in the workflow ^^
Amazing work as always!, the previous version broke on me, I installed the new version and its working great, thanks alot for keeping this up to date, I really appreaciate it!
Thank you for your hardwork!!
I'm enjoying it <3
PSA: use chatgpt to fix ur problems incase u get errors ^^
Agree with using ChatGPT for issue solving. It can help you diagnose issues if you dump errors into it. Usually doesn't give you a perfect solution but it will help you narrow down what the issue is.
Sage Not working. Can you specify exact cuda version?