Workflow: Image -> Autocaption (Prompt) -> WAN I2V with Upscale and Frame Interpolation and Video Extension
Creates Video Clips with 480p - 720p resolution.
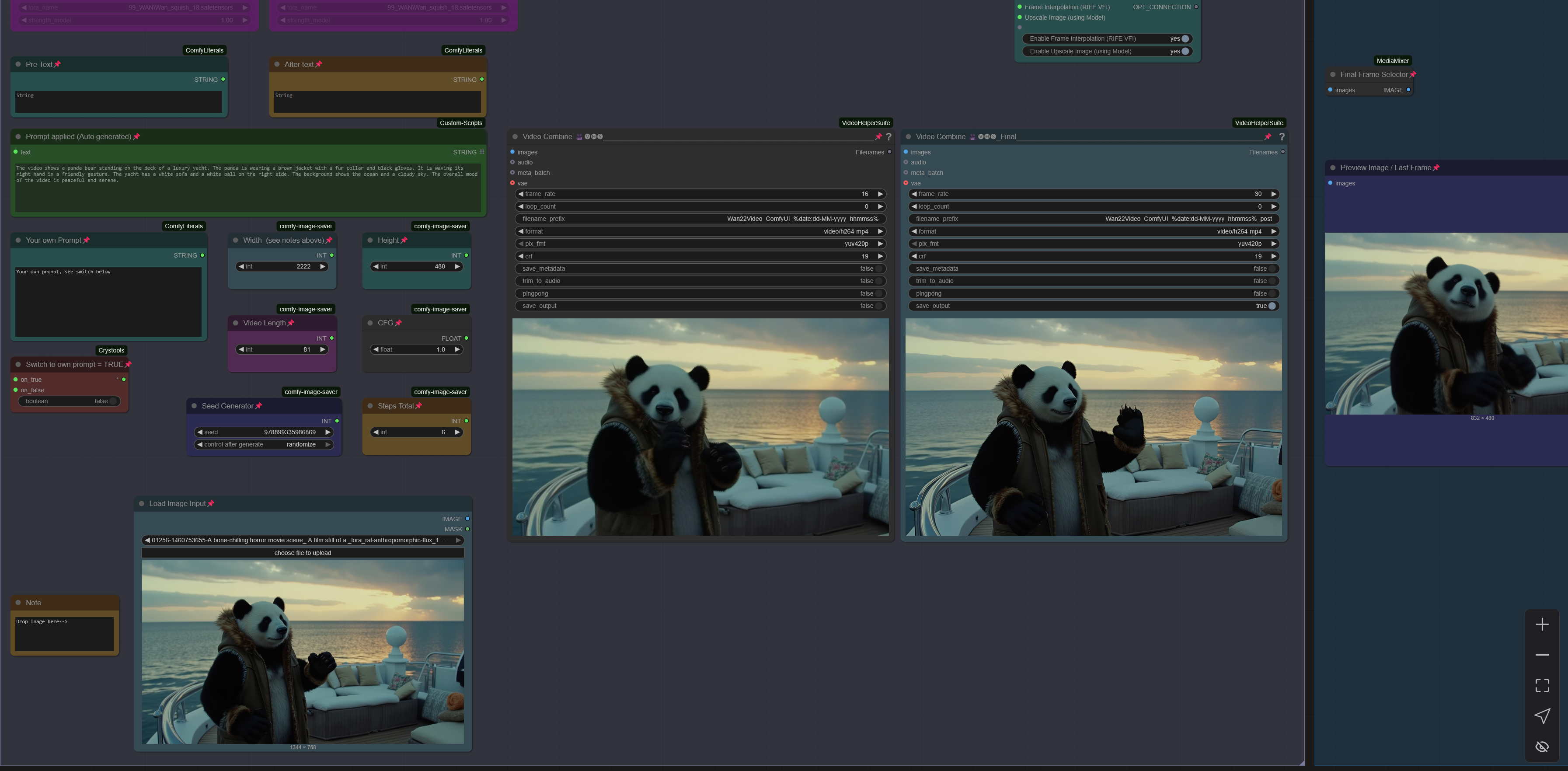
Wan2.2 14B Image to Video MultiClip Version re-work with LongLook
create clips with 4-6 steps and extend up to 3 times, see examples posted with 15-20sec of length.
using LongLook nodes for improved processing: https://github.com/shootthesound/comfyUI-LongLook
Increase overall quality for fast pace or complex motion clips
Uses chunk of last frames for better continuity when extending
Can pack more motion within a clip with 1 parameter, reduce slomo
process with improved Wan 2.2 models, Smoothmix with baked in LightX and other (including NSFW) Loras: https://huggingface.co/Bedovyy/smoothMixWan22-I2V-GGUF/tree/main
removed some custom nodes and replaced them with comfy core nodes where possible
Normal Version with own prompts, ideal to use for NSFW or specific clips with Loras.
Ollama Version, using an uncensored Qwen LLM to autocreate prompts for each clip sequence.
Ollama model (reads prompt only, fast): https://ollama.com/goonsai/josiefied-qwen2.5-7b-abliterated-v2
alternative model with Vision (reads input image+prompt, slower, it can do reasoning by enabling "think" in Ollama generate node): https://ollama.com/huihui_ai/qwen3-vl-abliterated
About below Versions: There is a Florence Caption Version and a LTX Prompt Enhancer (LTXPE) version. LTXPE is more heavy on VRAM.
Version use cases:
Create longer NSFW or specific clips with Loras and own prompts => MultiClip (14B) Normal
Create longer clips with autoprompts => MultiClip (14B) LTXPE or MultiClip_LTXPE+*
Generate short 5sec clips with own prompts or autoprompts => V1.0 (14B model) Florence or LTXPE*
*LTX Prompt Enhancer (LTXPE) might have issues with latest Comfy and Lightricks update
https://civarchive.com/models/1823416?commentId=1017869&dialog=commentThread
MultiClip LTXPE PLUS: Wan 2.2. 14B I2V Version based on below MultiClip workflow with improved LTX Prompt Enhancer (LTXPE) features (see notes in workflow). You may want to try below MultiClip workflow first.
Workflow enhances the LTXPE features to give more control over the prompt generation, it uses an uncensored language model, the video generation part is identical to below version. More Info: https://civarchive.com/models/1823416?modelVersionId=2303138&dialog=commentThread&commentId=972440
MultiClip: Wan 2.2. 14B I2V Version supporting LightX2V Wan 2.2. Loras to create clips with 4-6 steps and extend up to 3 times, see examples posted with 15-20sec of length.
There is a normal version which allows to use own prompts and a version using LTXPE for autoprompting. Normal version works well for specific or NSFW clips with Loras and the LTXPE is made to just drop an image, set width/height and hit run. The clips are combined to one full video at the end.
supporting new Wan 2.2. LightX2v Loras for low steps
Single Clip Versions included, which correspond to below V1.0 Workflow with additional Lora loader for "old" Wan 2.1. LightX2v Lora.
Since Wan 2.2 uses 2 models, the workflow gets complex. Still recommend to check the Wan 2.1 MultiClip Version, which is much leaner and has a rich selection of Loras. It can be found here: https://civarchive.com/models/1309065?modelVersionId=1998473
V1.0 WAN 2.2. 14B Image to Video workflow with LightX2v I2V Wan 2.2 Lora support for low steps (4-8 steps)
Wan 2.2. uses 2 models to process a clip. A High Noise and a Low Noise model, processed in sequence.
compatible with LightX2v Loras to process clips fast with low steps.
Models can be donwloaded here:
Vanilla Wan2.2 Models (Low & High Noise required, pick the ones matching your Vram): https://huggingface.co/bullerwins/Wan2.2-I2V-A14B-GGUF/tree/main
orig. LightX2v Loras for Wan 2.2. (I2v, Hi and Lo): https://huggingface.co/Kijai/WanVideo_comfy/tree/main/LoRAs/Wan22-Lightning/old
Oct.14th 25: 2 New LightX Highnoise Loras (MoE and 1030) are out , try with strength > 1.5, 7 steps, SD3 shift =5.0. replace High Noise Lora:
https://huggingface.co/Kijai/WanVideo_comfy/tree/main/LoRAs/Wan22_Lightx2v
Oct. 22nd 25: another LightX Lora has just been released (named 1022), recommended:
https://huggingface.co/lightx2v/Wan2.2-Distill-Loras/tree/main
Vae (same as Wan 2.1): https://huggingface.co/Comfy-Org/Wan_2.1_ComfyUI_repackaged/tree/main/split_files/vae
Textencoder (same as Wan 2.1): https://huggingface.co/Comfy-Org/Wan_2.2_ComfyUI_Repackaged/tree/main/split_files/text_encoders
Alternative / newer Wan 2.2. 14B model merges:
WAN 2.2. I2V 5B Model (GGUF) workflow with Florence or LTXPE auto caption
lower quality than 14B model
720p @ 24 frames
with FastWan Lora use CFG of 1 and 4-5 Steps, place a LoraLoader node after Unet Loader to inject Lora
FastWan Lora: https://huggingface.co/Kijai/WanVideo_comfy/tree/main/FastWan
Model (GGUF, pick model matching your Vram): https://huggingface.co/QuantStack/Wan2.2-TI2V-5B-GGUF/tree/main
VAE : https://huggingface.co/Comfy-Org/Wan_2.2_ComfyUI_Repackaged/tree/main/split_files/vae
Textencoder (same as Wan 2.1) :https://huggingface.co/Comfy-Org/Wan_2.2_ComfyUI_Repackaged/tree/main/split_files/text_encoders
location to save those files within your Comfyui folder:
Wan GGUF Model -> models/unet
Textencoder -> models/clip
Vae -> models/vae
Tips (for 14b Model):
Wan 2.2. I2V Prompting Tips: https://civarchive.com/models/1823416?modelVersionId=2063446&dialog=commentThread&commentId=890880
What GGUF Model to download? I usually go for a model with around 10gb of size with my 16gb Vram/64gb Ram. (i.e. "...Q4_K_M.gguf" model)
Play with LightX Lora strength (ca.1.5) to increase motion/reduce slomo
If you face issues with LTXPE see this thread: https://civarchive.com/models/1823416?dialog=commentThread&commentId=955337
Last Frame: If you face issues finding the pack for that node: https://github.com/DoctorDiffusion/ComfyUI-MediaMixer
Description
MultiClip Version for Wan 2.2. 14B I2V, allows to create and extend Clips up to 20 sec.
Normal (own Prompt) Version and LTXPE Version
SingleClip Versions included
FAQ
Comments (41)
I've downloaded more workflows for WAN than I can count and most have been deleted as soon as they've been opened - overcomplicated, requiring tons of nodes I don't have and designed to make my GPU throw itself out of a top floor window.
This video chunking and stitching idea is one I've been looking for a proper workflow for for ages, and though I was a bit apprehensive at first (this workflow has more spaghetti than an Italian restaurant!) once I did the first generation, I was pleasantly surprised how fast and effective it is!
I'm having a bit of trouble getting the LoRAs to have any desired effect between the sequences, but I'm amazed at just how effectively and easily this works.
My only sadness was that I use a really good merged WAN 2.1 model more than I currently use WAN 2.2... but then I noticed that you have a WAN 2.1 version as well!
Bravo maestro! There may have been a bit of a tremolo when I opened the workflow, but after using it, I'm getting nothing but sweet legato high notes!
Yeah it looks like a nightmare on first sight, but when you hit that "toggle link visibility" icon, it appears less italian :). I still love the Wan 2.1. workflow as well, less complex, lot of loras.
Glad you had the patience and it worked for you in the end.
It seems like Single Clip workflows generate much better than Multi Clips workflows. Maybe I'm doing something wrong, but single ones have better prompt adherence and motions too. Thank you as always for your hard work!
Technically both are the same. The SingleClip workflow is just a single sequence of the MultiClip workflow. The MultiClip result is prone to the last frame of a sequence is good enough or the lack of consitency between sequences. Like panning away from character in one sequence and panning back in the follow up sequence, will make the character to change.
It depends a bit on luck, but the workflow is fast enough to just run another generation or if one sequence is screwed you can right click the end frame of the previous good sequence and click "send to workflow/new workflow" to continue from there.
Thanks for the buzz again :)
Selection of Wan2.2. NSFW Loras:
(the ones with * I have tested and are working well with the workflow)
* https://civitai.com/models/1295758
* https://civitai.com/models/2078995
https://civitai.com/models/1879839
* https://civitai.com/models/1350447
https://civitai.com/models/1773498
* https://civitai.com/models/1820200
* https://civitai.com/models/1741501
* https://civitai.com/models/1814751
https://civitai.com/models/1331682
https://civitai.com/models/1845306
https://civitai.com/models/1874099
* https://civitai.com/models/1881060
https://civitai.com/models/1849369
* https://civitai.com/models/1874153
https://civitai.com/models/1858645
* https://civitai.com/models/1566648
https://civitai.com/models/1602000
* https://civitai.com/models/1634189
Hello! How do I use these LORAs in your workflow "WAN 2.2 IMAGE to VIDEO with Caption and Postprocessing"
I used version 14B, which works well and doesn't crash, but I don't know how to use your workflow: “Wan2.2_14B_I2V_LTXPE.”
Nor do I know which case to work on in this workflow.
I have some kind of red warning lights.
Thank you very much for your great work!
@ZeUser01207 there is a lora loader somewhere, maybe bypassed, named LoraLoaderModelOnly, there you can inject the High and Low Lora
@tremolo28 Thank you very much, I was not mistaken.
Could you please guide me and tell me where to find the safychecker, because I downloaded everything from your page, but I still feel like there is censorship.
Looks like half of links are dead now...
legendary! could you create a low noise only version or tell us how to proceed, its a very high level workflow
when using the lownoise model only, i think you will get like a Wan 2.1. result, I have same workflow for wan 2.1 as well.
With Wan2.2 workflow you could try to bypass "KSampler (Advanced) High Noise" node in each sequence, not tested, I doubt it will lead to a good result tho.
I've been getting issue saying it is missing nodes saying:
Text Find and Replace(In group node 'workflow>Florence')
workflow>Florence
LTXVPromptEnhancerLoader(In group node 'workflow>LTXPE')
workflow>LTXPE
LTXVPromptEnhancer(In group node 'workflow>LTXPE')
Text Concatenate
I tried updating through comfyui manager. Anyone know the fix to this?
Hi, those nodes are from this repo: https://github.com/WASasquatch/was-node-suite-comfyui
there is a note, that it might have been replaced with this repo: https://github.com/ltdrdata/was-node-suite-comfyui
I see both in comfyui manager.
@tremolo28 Thank you, maybe it was because I was running ComfyUI portable some of these stuff weren't found. Thank you once again
I know that this is a GGUF workflow but I believe the only thing I need to swap to support FP8 is the initial diffusion models (which I've already done). I don't see any other things that I would need to change, but please let me know if that's the case.
My first initial passes after uploading my image have turned out with my models face deformed and blurry. What tips can you provide so that it maintains the facial features of the initial reference image?
That is right, you can just swap the Unet Loader for GGUF with a Load Model node to use a fp8 model.
This is a fantastic workflow shared, and I express my gratitude and admiration for the author. However, when using the LAXPE version of the workflow, I encountered this error: LTXVPromptEnhancerLoader No such file or directory: "D:\\comfyui1\\ComfyUI_windows_portable\\ComfyUI\\models\\LLM\\Llama-3.2-3B-Instruct\\model-00001-of-00002.safetensors"
I can't find the model required for this, and I hope someone can help me.
Hi and thanks. The LTXPE model supposed to autodownload on first run. It can also be downloaded here: https://huggingface.co/meta-llama/Llama-3.2-3B-Instruct/tree/main
save all to a folder named "Llama-3.2-3B-Instruct" and place the folder to comfy/models/LLM
@tremolo28 My download request was rejected. TvT. LTXPE wasn't automatically installed on the first run. What's the problem? How can I fix this? The standard version only has a single prompt box, which makes it difficult to freely use it. Is there a way to download this component elsewhere?
@wp88080148827 here is the LTXPE repo: https://github.com/Lightricks/ComfyUI-LTXVideo. or see custom nodes in comfy manager.
@tremolo28 Thank you for your idea of "automatic download". I have solved it now. I deleted the "Llama-3.2-3B-Instruct" folder and re-ran the workflow. Then I found the download link of the model in the command prompt and successfully downloaded it through the browser. Unfortunately, I have to go out now. I will see if I can run the workflow successfully when I come back.
Would love to see a 3ksampler version of this
have actually tested a setup with 3 samplers, but result was not realy any better, instead it added lot of complexity.
Excuse me, I'm confused, which GGUFs should I download to match my 8Go VRAM? The names are unclear
with 8gb of Vram, you can try the the Q3_K_M models.
@tremolo28 Thank you very much kind sir
@kofic28991624 Did you get this to work on a 8GB VRAM?
hi, what GGUF would you recommend for a 3090 and 64 GB of ram system? I greatly appreciated the help
With 24gb of Vram, you can use the biggest model, …Q8.
I get this comment 'Florence2ForConditionalGeneration' object has no attribute '_supports_sdpa' I don't understand why, has this happened to anyone else?
there's no Florence model loader node in your workflow...
@tremolo28 where is Florence model loader?
another user mentioned this regarding above error from LTXPE: "error LTXVPromptEnhancerLoader 'Florence2ForConditionalGeneration' object has no attribute '_supports_sdpa'. I looked it up and i needed to downgrade transformers to version 4.49.0. I've managed to get passed that"
A change of transformers version would work like this:
from your folder ComfyUI_windows_portable\python_embeded:
python.exe -m pip uninstall transformers
python.exe -m pip install transformers==4.49.0
to check installed version, try this:
python.exe -m pip show transformers
I have 4.49 installed and no issue.
Pls let me know if this solved the issue.
@tremolo28 that worked! thanks!
There is a new lightX Lora Version out, it is Text2Video, but it works with the workflow, currently testing it. There will be an Image2Video Lora soon. It is 4 steps and goes by the name "250928"
https://huggingface.co/Kijai/WanVideo_comfy/tree/main/LoRAs/Wan22-Lightning
thats great, I have you keep updating your WF
here is a new I2V lightX Lora by Kijai, it is a High Noise Lora, Low Noise can remain as before: https://huggingface.co/Kijai/WanVideo_comfy/tree/main/LoRAs/Wan22_Lightx2v
try it with a strength >1.5 (7steps total, ModelSamplingSD3 shift = 5.0)
so here is another set of LightX Loras, just popped up (named 1022) :
https://huggingface.co/lightx2v/Wan2.2-Distill-Loras/tree/main
Kijai´s comment: "Tested this enough to confirm it's indeed new and different from the previous release. Works as it is in Comfy, the diff_m keys are not important even if it complains about those."
@tremolo28 ty for updating me, saw that one on reddit, have you tested using grid and various str?
@juliusmartin Tested it with like 10 video clips (strength=1.0, 5-7 steps total) and it seems to be the richest Lora regarding motion.
... and there is another LightX Lora , named 1030: https://huggingface.co/Kijai/WanVideo_comfy/tree/main/LoRAs/Wan22_Lightx2v
tested it with about 10 clips and compared it to version 1022, it is on par or maybe a bit better with stability on colors. You might want to try it with a strength >= 1.5 (6-7steps total, ModelSamplingSD3 shift = 5.0)