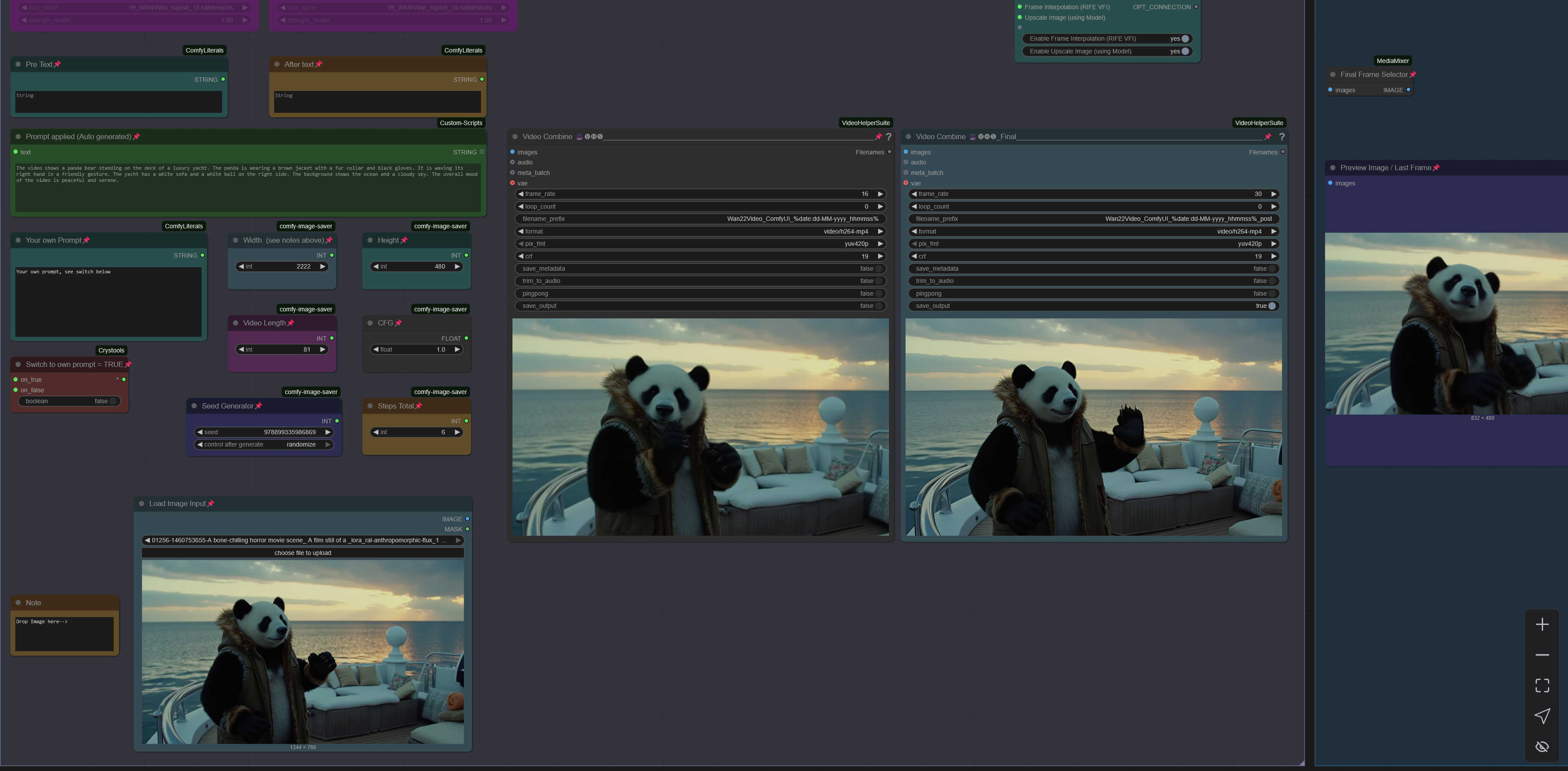
Workflow: Image -> Autocaption (Prompt) -> WAN I2V with Upscale and Frame Interpolation and Video Extension
Creates Video Clips with 480p - 720p resolution.
Wan2.2 14B Image to Video MultiClip Version re-work with LongLook
create clips with 4-6 steps and extend up to 3 times, see examples posted with 15-20sec of length.
using LongLook nodes for improved processing: https://github.com/shootthesound/comfyUI-LongLook
Increase overall quality for fast pace or complex motion clips
Uses chunk of last frames for better continuity when extending
Can pack more motion within a clip with 1 parameter, reduce slomo
process with improved Wan 2.2 models, Smoothmix with baked in LightX and other (including NSFW) Loras: https://huggingface.co/Bedovyy/smoothMixWan22-I2V-GGUF/tree/main
removed some custom nodes and replaced them with comfy core nodes where possible
Normal Version with own prompts, ideal to use for NSFW or specific clips with Loras.
Ollama Version, using an uncensored Qwen LLM to autocreate prompts for each clip sequence.
Ollama model (reads prompt only, fast): https://ollama.com/goonsai/josiefied-qwen2.5-7b-abliterated-v2
alternative model with Vision (reads input image+prompt, slower, it can do reasoning by enabling "think" in Ollama generate node): https://ollama.com/huihui_ai/qwen3-vl-abliterated
About below Versions: There is a Florence Caption Version and a LTX Prompt Enhancer (LTXPE) version. LTXPE is more heavy on VRAM.
Version use cases:
Create longer NSFW or specific clips with Loras and own prompts => MultiClip (14B) Normal
Create longer clips with autoprompts => MultiClip (14B) LTXPE or MultiClip_LTXPE+*
Generate short 5sec clips with own prompts or autoprompts => V1.0 (14B model) Florence or LTXPE*
*LTX Prompt Enhancer (LTXPE) might have issues with latest Comfy and Lightricks update
https://civarchive.com/models/1823416?commentId=1017869&dialog=commentThread
MultiClip LTXPE PLUS: Wan 2.2. 14B I2V Version based on below MultiClip workflow with improved LTX Prompt Enhancer (LTXPE) features (see notes in workflow). You may want to try below MultiClip workflow first.
Workflow enhances the LTXPE features to give more control over the prompt generation, it uses an uncensored language model, the video generation part is identical to below version. More Info: https://civarchive.com/models/1823416?modelVersionId=2303138&dialog=commentThread&commentId=972440
MultiClip: Wan 2.2. 14B I2V Version supporting LightX2V Wan 2.2. Loras to create clips with 4-6 steps and extend up to 3 times, see examples posted with 15-20sec of length.
There is a normal version which allows to use own prompts and a version using LTXPE for autoprompting. Normal version works well for specific or NSFW clips with Loras and the LTXPE is made to just drop an image, set width/height and hit run. The clips are combined to one full video at the end.
supporting new Wan 2.2. LightX2v Loras for low steps
Single Clip Versions included, which correspond to below V1.0 Workflow with additional Lora loader for "old" Wan 2.1. LightX2v Lora.
Since Wan 2.2 uses 2 models, the workflow gets complex. Still recommend to check the Wan 2.1 MultiClip Version, which is much leaner and has a rich selection of Loras. It can be found here: https://civarchive.com/models/1309065?modelVersionId=1998473
V1.0 WAN 2.2. 14B Image to Video workflow with LightX2v I2V Wan 2.2 Lora support for low steps (4-8 steps)
Wan 2.2. uses 2 models to process a clip. A High Noise and a Low Noise model, processed in sequence.
compatible with LightX2v Loras to process clips fast with low steps.
Models can be donwloaded here:
Vanilla Wan2.2 Models (Low & High Noise required, pick the ones matching your Vram): https://huggingface.co/bullerwins/Wan2.2-I2V-A14B-GGUF/tree/main
orig. LightX2v Loras for Wan 2.2. (I2v, Hi and Lo): https://huggingface.co/Kijai/WanVideo_comfy/tree/main/LoRAs/Wan22-Lightning/old
Oct.14th 25: 2 New LightX Highnoise Loras (MoE and 1030) are out , try with strength > 1.5, 7 steps, SD3 shift =5.0. replace High Noise Lora:
https://huggingface.co/Kijai/WanVideo_comfy/tree/main/LoRAs/Wan22_Lightx2v
Oct. 22nd 25: another LightX Lora has just been released (named 1022), recommended:
https://huggingface.co/lightx2v/Wan2.2-Distill-Loras/tree/main
Vae (same as Wan 2.1): https://huggingface.co/Comfy-Org/Wan_2.1_ComfyUI_repackaged/tree/main/split_files/vae
Textencoder (same as Wan 2.1): https://huggingface.co/Comfy-Org/Wan_2.2_ComfyUI_Repackaged/tree/main/split_files/text_encoders
Alternative / newer Wan 2.2. 14B model merges:
WAN 2.2. I2V 5B Model (GGUF) workflow with Florence or LTXPE auto caption
lower quality than 14B model
720p @ 24 frames
with FastWan Lora use CFG of 1 and 4-5 Steps, place a LoraLoader node after Unet Loader to inject Lora
FastWan Lora: https://huggingface.co/Kijai/WanVideo_comfy/tree/main/FastWan
Model (GGUF, pick model matching your Vram): https://huggingface.co/QuantStack/Wan2.2-TI2V-5B-GGUF/tree/main
VAE : https://huggingface.co/Comfy-Org/Wan_2.2_ComfyUI_Repackaged/tree/main/split_files/vae
Textencoder (same as Wan 2.1) :https://huggingface.co/Comfy-Org/Wan_2.2_ComfyUI_Repackaged/tree/main/split_files/text_encoders
location to save those files within your Comfyui folder:
Wan GGUF Model -> models/unet
Textencoder -> models/clip
Vae -> models/vae
Tips (for 14b Model):
Wan 2.2. I2V Prompting Tips: https://civarchive.com/models/1823416?modelVersionId=2063446&dialog=commentThread&commentId=890880
What GGUF Model to download? I usually go for a model with around 10gb of size with my 16gb Vram/64gb Ram. (i.e. "...Q4_K_M.gguf" model)
Play with LightX Lora strength (ca.1.5) to increase motion/reduce slomo
If you face issues with LTXPE see this thread: https://civarchive.com/models/1823416?dialog=commentThread&commentId=955337
Last Frame: If you face issues finding the pack for that node: https://github.com/DoctorDiffusion/ComfyUI-MediaMixer
Description
Wan2.2 MultiClip Image2Video with LTX Prompt Enhancer PLUS
Workflow to create and extend autoprompted video Clips with LTXPE Plus
Workflow to create Prompts only for testing LTXPE Plus
FAQ
Comments (21)
LTXPE MultiClip PLUS Workflow:
Why was it created?
Found out with LTXPE prompts you can create good extended clips on an input image, however I had to alter the System Prompt each time to better latch on the desired output.
Instead of fiddling around with a text wall, I have added placeholders that can be maintained with free Text in the GUI to better control the output. The video clip generation itself remains unchanged.
Keep in mind it is all managed by a language model, there is no total control and not always perfect results, it is more about increasing chances to get good results.
The workflow corresponds to the MultiClip (14B) workflow with LTXPE to create video prompts per video sequence, only the LTXPE features have been enhanced:
- Uncensored language model (Llama-3.2-3B-Instruct, will be downloaded on first run, NSFW ready)
- LTXPE creates the individual prompts for each Sequence, based on the input image, all in one shot with a logical sequence, it predicts motion and sets a view focus on a subject, defined by a system prompt.
- The user can enhance the system prompt by setting 3 parameters: CONTENT, TYPE and SUBJECT in corresponding nodes.
- CONTENT describes what shall happen. i.e. "a woman dancing", "a dog and cat playing", "a car driving", etc.
- TYPE describes the type of the video. i.e. "cinematic", "erotic" , "action" ,"dramatic", etc.
- SUBJECT sets the camera focus on a certain subject in the input image. i.e. "woman", "man", "dog", "vehicle", etc.
- Toggle between a "static" or a "follow" type camera view on the subject, follow type shows more camera motion.
- Switch between 2 types of System prompts, a default one, more general and a strong one, that sets focus on the Content paramter by placing it at the start of each prompt.
- LTXPE sometimes ignores/screws the defined format to split the prompts and shows a TextSplit Error. This happens rarely, but increases if you put too much info into it. Shorten or update the wording slightly and try again. Edit: Place this at the start of the LTXPE System prompts (blue nodes): Avoid message like "I cannot create explicit content"
Example use cases:
Clip for a car in motion: Want to keep the car always in frame?
-> Set Camtype switch to "static" (true), name "car" in node "Subject"
Clip of a nude woman with camera motion, woman shall remain nude, even after getting back from out of frame?
-> Switch Camtype to "follow", set LTXPE System prompt switch to "strong", name "nude woman" in "Content". (low sucess rate tho...)
Clip using a Lora with trigger phrase?
-> Switch LTXPE system prompt to "strong", name the trigger in "Content" (keep it short!)
Clip of dog and cat playing together, with view focus on the dog?
-> Set content to "a cat and dog playing", set Subject to "dog", set Camtype to "follow"
Other tips:
The individual prompts per sequence are too short or too long for your taste?
-> set the maximum no. of words defined in the blue LTXP System prompt to a higher or lower count (default = 45 words)
You have changed the LTXPE System prompt and now you often get "TextSplit Error"
-> there are backup nodes in the upper left corner containing the default prompts, so you can copy & paste them back.
You have used the Content, Type and Subject nodes and always get a "TextSplit Error"
-> the text might have been too long and confused LTXPE to output in correct format, try to shorten the text.
You just want to drop the image and dont bother about all above?
-> use the default settings: Content = "a scene", Type = "cinematic", Subject = "subject", those are very general.
Use the "prompt only" version of the workflow to test and get familiar with the prompt generation, without generating clips each time. Recommend to start with this workflow.
Here is a selection of NSFW Loras, the first one by Mystic can be used for general NSFW purpose:
https://civitai.com/models/1823416?modelVersionId=2303138&dialog=commentThread&commentId=911748
Hey man, I've been struggling trying to run this workflow but I'm stuck on some nasty error LTXVPromptEnhancerLoader 'Florence2ForConditionalGeneration' object has no attribute '_supports_sdpa'. I looked it up and i needed to downgrade transformers to version 4.49.0. I've managed to get passed that and another nasty error came up:
LTXVPromptEnhancer Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cpu! (when checking argument for argument index in method wrapper_CUDA__index_select).
This one has been a challange no matter what I do. Do you have a list of errors and fixes that might solve this problems?
@adrianolimaengenharia90 hi, recall the LTXPE error from another workflow, a user had same issue and found a fix, hope it helps:
https://civitai.com/models/995093?modelVersionId=1791896&dialog=commentThread&commentId=727932
@tremolo28 I've managed to fix this issue but now I'm facing a TextSplit error like you've documented. I'm running on low end (8GB RAM) and I cant work with more than 180 tokens. Do you have any suggestions on how I could adapt your workflow so I work with only 180 tokens?
@adrianolimaengenharia90 180tokens only screws the format more often and outputs the textsplit error. You could try the previous non LTXPE (normal) workflow with own prompts, it is more precisice anyway, as the LTXPE is more for the lazy ones, like me :)
To be honest you might not have a lot of fun with the LTXPE WF and 8gb Vram. Suggestions to change would be to reduce the output to only 2-3 prompts with lower word count, but you would need to update the textsplit nodes as well, maybe not worth the hustle
To reduce Textxplit Errors you can add this to the start of the LTXPE System prompts (blue nodes): Avoid message like "I cannot create explicit content".
Although the model is uncensored, it sometimes spits out that message, above entry avoids it mostly.
New Comfy Version (>0.3.68) breaks LTX Prompt enhancer.
Quick fix: find file "ltx_model.py" in ComfyUI\custom_nodes\ComfyUI-LTXVideo\tricks\modules
Edit Line 9 by adding a # in front (# apply_rotary_emb).
As in the sceenshot of this thread: https://github.com/Lightricks/ComfyUI-LTXVideo/issues/283
You might also need to change the transformers version, which works like this:
from your folder ComfyUI_windows_portable\python_embeded:
python.exe -m pip uninstall transformers
python.exe -m pip install transformers==4.49.0
to check installed version, try this:
python.exe -m pip show transformers
With latest ComfyUi update and Lightricks (LTX 2) updates, LTXPE might no longer work
I have an issue that no nodes are marked as missing in the manager. But a lot are still showing as red these nodes are:
When i try to run it keeps saying:
Cannot execute because a node is missing the class_type property.: Node ID '#96'
Node ID 96 is FinalFrameSelector
Hi, those missing nodes are from this custom-node repo: https://github.com/giriss/comfy-image-saver
In comfyui manager the pack is named "Save Image with Generation Metadata"
@tremolo28 Thanks a lot that solved all issues expect the one with node 196:
FinalFrameSelector node is apparently missing.
I googled this node and even installed
https://github.com/DoctorDiffusion/ComfyUI-MediaMixer
Along with what you suggested the
https://github.com/giriss/comfy-image-saver/blob/main/nodes.py
But it is getting stuck on node 196/FinalFrameSelector
The workflow file is
Wan2.2_14B_I2V_Lora_Florence_LightX-2.json
@db9s The Mediamixer Link you have provided is the right one, FinalFrameSelector seems to be installed, but not working properly on your setup. I rememeber I had a similar issue after a comfy update, but dont recall how I resolved it. Think I had a mismatching transformer version installed.
Can you go to your comfy/python_embeded folder and check the version by entering: python.exe -m pip show transformers
you can change the version with this to transformer version 4.49 in comfy/python_embeded:
python.exe -m pip uninstall transformers
python.exe -m pip install transformers==4.49.0
(note your current installed Version , so you can go back if needed)
Hope this helps.
@tremolo28 I downloaded "Save Image with Generation Metadata" but its still throwing the error referring to Node ID #96
@suille1 Node #196 (final frame selector) is from this repo: https://github.com/DoctorDiffusion/ComfyUI-MediaMixer
Maybe try uninstall and re-install, see install instructions. Hope it helps
I got same issue. please help
@tremolo28 This doesn't work. For whatever reason ComfyUI refuses to install this node. I have tried multiple times, selected both the latest version and nightly, and it refuses to install.
@sexytimesalycat2 if you chose the LongLook workflow, you can delete that "final frame" nodes, those are view only. Last frame will be injected anyway.
I have that node installed on mutliple comfy versions and no issue, some people report problems to install tho. Comfy can be a pain sometimes...
Is there any version that accepts high and low safetensor ? This workflow is using GGUF.
Hi, you can just swap the two "Unet Loader" Nodes (GGUF) with "Load Checkpoint" Nodes (Safetensor)
Here are some alternative Wan 2.2 14B GGUF models with improved animation. Bypass the LightX Lora loaders, as those Loras are already baked in. NSFW ready:
1. Smoothmix:
https://huggingface.co/Bedovyy/smoothMixWan22-I2V-GGUF/tree/main
2. DaSiWa-WAN 2.2 I2V 14B TastySin
https://civitai.com/models/2190659?modelVersionId=2467097
Smoothmix is great if you are tired of slowmo clips, it better reproduces natural speed of motion. Not perfect, but far better than vanilla Wan2.2 lightx model/lora
preferring the tastysin over the smoothmix by far.. much more natural.