WAN-L.O.V.E. is hybrid Wan Low Overhead VRAM Efficiency Image-to-Video Fast (4-step) All-In-One model (full checkpoint: UNET, CLIP and VAE). All you need to encode source images is this model and, optionally, CLIP Vision model for Wan. Use CFG 1 and Euler sampler and beta scheduler and model shift 8-12. Enjoy!
In ComfyUI just use usual default workflow with checkpoint loader, CLIP vision loader and sampler.
Note: If you look for Wan 2.2 14B all-in-one version, then try this checkpoint, the same 1-pass workflow as for Wan 2.1 will work pretty well.
Real 49 frames of 720p video generation with Wan 2.1 14B on i5-11400 with RTX 3050 4Gb and 32 Gb RAM via ComfyUI:
And the easy-peasy one-pass workflow (open this picture in a new tab):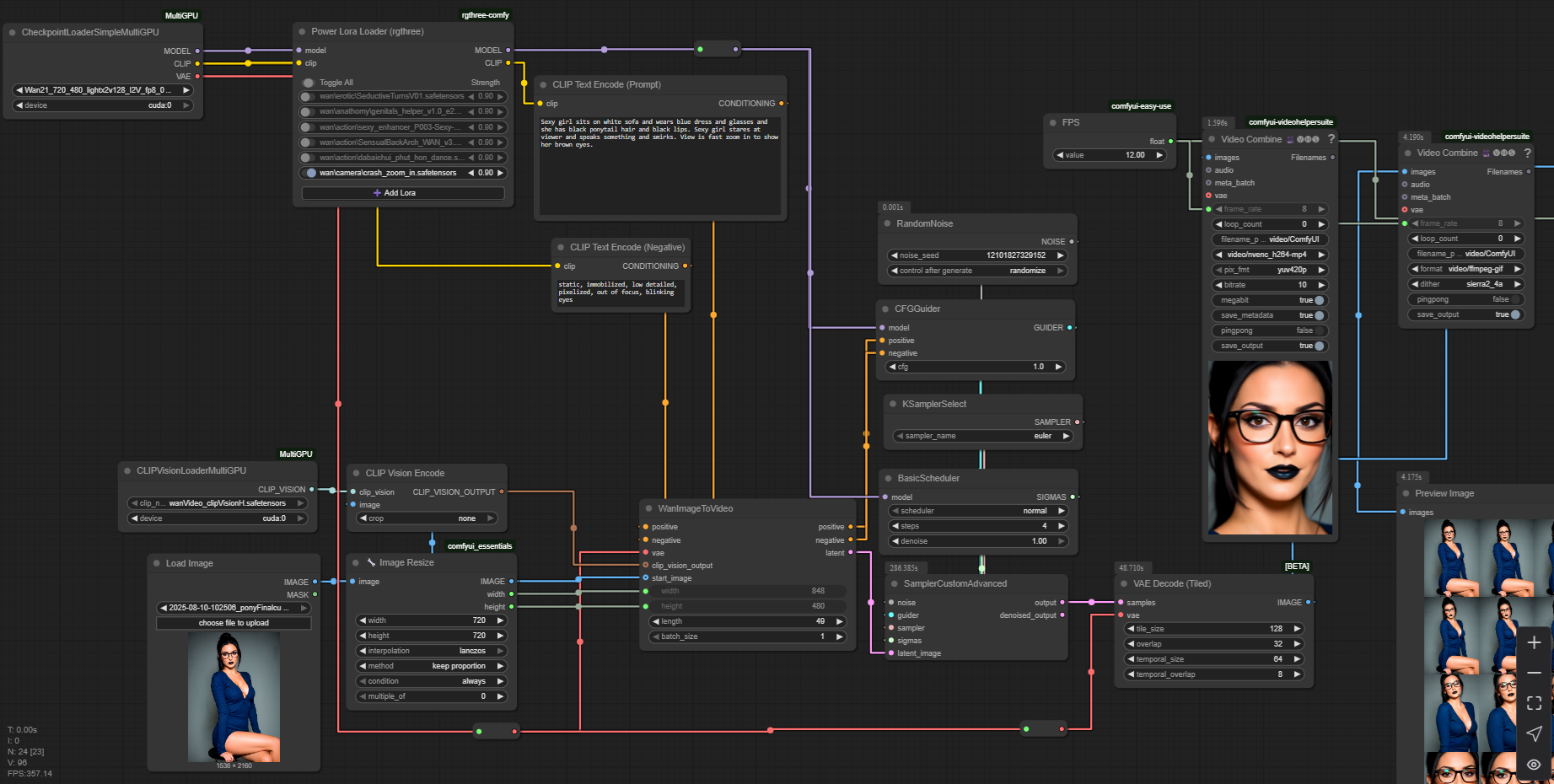
Description
FAQ
Comments (31)
Hey, what exactly did you merge into the 5b model? Seems to work pretty good.
I noticed it throws this error though, is that normal?
unet missing: ['text_embedding.0.scale_input', 'text_embedding.2.scale_input', 'time_em
bedding.0.scale_input', 'time_embedding.2.scale_input', 'time_projection.1.scale_input'
, 'blocks.0.self_attn.q.scale_input', 'blocks.0.self_attn.k.scale_input', 'blocks.0.sel
f_attn.v.scale_input', 'blocks.0.self_attn.o.scale_input', 'blocks.0.cross_attn.q.scale
_input', 'blocks.0.cross_attn.k.scale_input', 'blocks.0.cross_attn.v.scale_input', 'blo
cks.0.cross_attn.o.scale_input', 'blocks.0.ffn.0.scale_input', 'blocks.0.ffn.2.scale_in
put', 'blocks.1.self_attn.q.scale_input', 'blocks.1.self_attn.k.scale_input', 'blocks.1
.self_attn.v.scale_input', 'blocks.1.self_attn.o.scale_input', 'blocks.1.cross_attn.q.s
cale_input', 'blocks.1.cross_attn.k.scale_input', 'blocks.1.cross_attn.v.scale_input',
'blocks.1.cross_attn.o.scale_input', 'blocks.1.ffn.0.scale_input', 'blocks.1.ffn.2.scal
e_input', 'blocks.2.self_attn.q.scale_input', 'blocks.2.self_attn.k.scale_input', 'bloc
ks.2.self_attn.v.scale_input', 'blocks.2.self_attn.o.scale_input', 'blocks.2.cross_attn
.q.scale_input', 'blocks.2.cross_attn.k.scale_input', 'blocks.2.cross_attn.v.scale_inpu
t', 'blocks.2.cross_attn.o.scale_input', 'blocks.2.ffn.0.scale_input', 'blocks.2.ffn.2.
scale_input', 'blocks.3.self_attn.q.scale_input', 'blocks.3.self_attn.k.scale_input', '
blocks.3.self_attn.v.scale_input', 'blocks.3.self_attn.o.scale_input', 'blocks.3.cross_
attn.q.scale_input', 'blocks.3.cross_attn.k.scale_input', 'blocks.3.cross_attn.v.scale_
input', 'blocks.3.cross_attn.o.scale_input', 'blocks.3.ffn.0.scale_input', 'blocks.3.ff
n.2.scale_input', 'blocks.4.self_attn.q.scale_input', 'blocks.4.self_attn.k.scale_input
', 'blocks.4.self_attn.v.scale_input', 'blocks.4.self_attn.o.scale_input', 'blocks.4.cr
oss_attn.q.scale_input', 'blocks.4.cross_attn.k.scale_input', 'blocks.4.cross_attn.v.sc
ale_input', 'blocks.4.cross_attn.o.scale_input', 'blocks.4.ffn.0.scale_input', 'blocks.
4.ffn.2.scale_input', 'blocks.5.self_attn.q.scale_input', 'blocks.5.self_attn.k.scale_i
nput', 'blocks.5.self_attn.v.scale_input', 'blocks.5.self_attn.o.scale_input', 'blocks.
5.cross_attn.q.scale_input', 'blocks.5.cross_attn.k.scale_input', 'blocks.5.cross_attn.
v.scale_input', 'blocks.5.cross_attn.o.scale_input', 'blocks.5.ffn.0.scale_input', 'blo
cks.5.ffn.2.scale_input', 'blocks.6.self_attn.q.scale_input', 'blocks.6.self_attn.k.sca
le_input', 'blocks.6.self_attn.v.scale_input', 'blocks.6.self_attn.o.scale_input', 'blo
cks.6.cross_attn.q.scale_input', 'blocks.6.cross_attn.k.scale_input', 'blocks.6.cross_a
ttn.v.scale_input', 'blocks.6.cross_attn.o.scale_input', 'blocks.6.ffn.0.scale_input',
'blocks.6.ffn.2.scale_input', 'blocks.7.self_attn.q.scale_input', 'blocks.7.self_attn.k
.scale_input', 'blocks.7.self_attn.v.scale_input', 'blocks.7.self_attn.o.scale_input',
'blocks.7.cross_attn.q.scale_input', 'blocks.7.cross_attn.k.scale_input', 'blocks.7.cro
ss_attn.v.scale_input', 'blocks.7.cross_attn.o.scale_input', 'blocks.7.ffn.0.scale_inpu
t', 'blocks.7.ffn.2.scale_input', 'blocks.8.self_attn.q.scale_input', 'blocks.8.self_at
tn.k.scale_input', 'blocks.8.self_attn.v.scale_input', 'blocks.8.self_attn.o.scale_inpu
t', 'blocks.8.cross_attn.q.scale_input', 'blocks.8.cross_attn.k.scale_input', 'blocks.8
.cross_attn.v.scale_input', 'blocks.8.cross_attn.o.scale_input', 'blocks.8.ffn.0.scale_
input', 'blocks.8.ffn.2.scale_input', 'blocks.9.self_attn.q.scale_input', 'blocks.9.sel
f_attn.k.scale_input', 'blocks.9.self_attn.v.scale_input', 'blocks.9.self_attn.o.scale_
input', 'blocks.9.cross_attn.q.scale_input', 'blocks.9.cross_attn.k.scale_input', 'bloc
ks.9.cross_attn.v.scale_input', 'blocks.9.cross_attn.o.scale_input', 'blocks.9.ffn.0.sc
ale_input', 'blocks.9.ffn.2.scale_input', 'blocks.10.self_attn.q.scale_input', 'blocks.
10.self_attn.k.scale_input', 'blocks.10.self_attn.v.scale_input', 'blocks.10.self_attn.
o.scale_input', 'blocks.10.cross_attn.q.scale_input', 'blocks.10.cross_attn.k.scale_inp
ut', 'blocks.10.cross_attn.v.scale_input', 'blocks.10.cross_attn.o.scale_input', 'block
s.10.ffn.0.scale_input', 'blocks.10.ffn.2.scale_input', 'blocks.11.self_attn.q.scale_in
put', 'blocks.11.self_attn.k.scale_input', 'blocks.11.self_attn.v.scale_input', 'blocks
.11.self_attn.o.scale_input', 'blocks.11.cross_attn.q.scale_input', 'blocks.11.cross_at
tn.k.scale_input', 'blocks.11.cross_attn.v.scale_input', 'blocks.11.cross_attn.o.scale_
input', 'blocks.11.ffn.0.scale_input', 'blocks.11.ffn.2.scale_input', 'blocks.12.self_a
ttn.q.scale_input', 'blocks.12.self_attn.k.scale_input', 'blocks.12.self_attn.v.scale_i
nput', 'blocks.12.self_attn.o.scale_input', 'blocks.12.cross_attn.q.scale_input', 'bloc
ks.12.cross_attn.k.scale_input', 'blocks.12.cross_attn.v.scale_input', 'blocks.12.cross
_attn.o.scale_input', 'blocks.12.ffn.0.scale_input', 'blocks.12.ffn.2.scale_input', 'bl
ocks.13.self_attn.q.scale_input', 'blocks.13.self_attn.k.scale_input', 'blocks.13.self_
attn.v.scale_input', 'blocks.13.self_attn.o.scale_input', 'blocks.13.cross_attn.q.scale
_input', 'blocks.13.cross_attn.k.scale_input', 'blocks.13.cross_attn.v.scale_input', 'b
locks.13.cross_attn.o.scale_input', 'blocks.13.ffn.0.scale_input', 'blocks.13.ffn.2.sca
le_input', 'blocks.14.self_attn.q.scale_input', 'blocks.14.self_attn.k.scale_input', 'b
locks.14.self_attn.v.scale_input', 'blocks.14.self_attn.o.scale_input', 'blocks.14.cros
s_attn.q.scale_input', 'blocks.14.cross_attn.k.scale_input', 'blocks.14.cross_attn.v.sc
ale_input', 'blocks.14.cross_attn.o.scale_input', 'blocks.14.ffn.0.scale_input', 'block
s.14.ffn.2.scale_input', 'blocks.15.self_attn.q.scale_input', 'blocks.15.self_attn.k.sc
ale_input', 'blocks.15.self_attn.v.scale_input', 'blocks.15.self_attn.o.scale_input', '
blocks.15.cross_attn.q.scale_input', 'blocks.15.cross_attn.k.scale_input', 'blocks.15.c
ross_attn.v.scale_input', 'blocks.15.cross_attn.o.scale_input', 'blocks.15.ffn.0.scale_
input', 'blocks.15.ffn.2.scale_input', 'blocks.16.self_attn.q.scale_input', 'blocks.16.
self_attn.k.scale_input', 'blocks.16.self_attn.v.scale_input', 'blocks.16.self_attn.o.s
cale_input', 'blocks.16.cross_attn.q.scale_input', 'blocks.16.cross_attn.k.scale_input'
, 'blocks.16.cross_attn.v.scale_input', 'blocks.16.cross_attn.o.scale_input', 'blocks.1
6.ffn.0.scale_input', 'blocks.16.ffn.2.scale_input', 'blocks.17.self_attn.q.scale_input
', 'blocks.17.self_attn.k.scale_input', 'blocks.17.self_attn.v.scale_input', 'blocks.17
.self_attn.o.scale_input', 'blocks.17.cross_attn.q.scale_input', 'blocks.17.cross_attn.
k.scale_input', 'blocks.17.cross_attn.v.scale_input', 'blocks.17.cross_attn.o.scale_inp
ut', 'blocks.17.ffn.0.scale_input', 'blocks.17.ffn.2.scale_input', 'blocks.18.self_attn
.q.scale_input', 'blocks.18.self_attn.k.scale_input', 'blocks.18.self_attn.v.scale_inpu
t', 'blocks.18.self_attn.o.scale_input', 'blocks.18.cross_attn.q.scale_input', 'blocks.
18.cross_attn.k.scale_input', 'blocks.18.cross_attn.v.scale_input', 'blocks.18.cross_at
tn.o.scale_input', 'blocks.18.ffn.0.scale_input', 'blocks.18.ffn.2.scale_input', 'block
s.19.self_attn.q.scale_input', 'blocks.19.self_attn.k.scale_input', 'blocks.19.self_att
n.v.scale_input', 'blocks.19.self_attn.o.scale_input', 'blocks.19.cross_attn.q.scale_in
put', 'blocks.19.cross_attn.k.scale_input', 'blocks.19.cross_attn.v.scale_input', 'bloc
ks.19.cross_attn.o.scale_input', 'blocks.19.ffn.0.scale_input', 'blocks.19.ffn.2.scale_
input', 'blocks.20.self_attn.q.scale_input', 'blocks.20.self_attn.k.scale_input', 'bloc
ks.20.self_attn.v.scale_input', 'blocks.20.self_attn.o.scale_input', 'blocks.20.cross_a
ttn.q.scale_input', 'blocks.20.cross_attn.k.scale_input', 'blocks.20.cross_attn.v.scale
_input', 'blocks.20.cross_attn.o.scale_input', 'blocks.20.ffn.0.scale_input', 'blocks.2
0.ffn.2.scale_input', 'blocks.21.self_attn.q.scale_input', 'blocks.21.self_attn.k.scale
_input', 'blocks.21.self_attn.v.scale_input', 'blocks.21.self_attn.o.scale_input', 'blo
cks.21.cross_attn.q.scale_input', 'blocks.21.cross_attn.k.scale_input', 'blocks.21.cros
s_attn.v.scale_input', 'blocks.21.cross_attn.o.scale_input', 'blocks.21.ffn.0.scale_inp
ut', 'blocks.21.ffn.2.scale_input', 'blocks.22.self_attn.q.scale_input', 'blocks.22.sel
f_attn.k.scale_input', 'blocks.22.self_attn.v.scale_input', 'blocks.22.self_attn.o.scal
e_input', 'blocks.22.cross_attn.q.scale_input', 'blocks.22.cross_attn.k.scale_input', '
blocks.22.cross_attn.v.scale_input', 'blocks.22.cross_attn.o.scale_input', 'blocks.22.f
fn.0.scale_input', 'blocks.22.ffn.2.scale_input', 'blocks.23.self_attn.q.scale_input',
'blocks.23.self_attn.k.scale_input', 'blocks.23.self_attn.v.scale_input', 'blocks.23.se
lf_attn.o.scale_input', 'blocks.23.cross_attn.q.scale_input', 'blocks.23.cross_attn.k.s
cale_input', 'blocks.23.cross_attn.v.scale_input', 'blocks.23.cross_attn.o.scale_input'
, 'blocks.23.ffn.0.scale_input', 'blocks.23.ffn.2.scale_input', 'blocks.24.self_attn.q.
scale_input', 'blocks.24.self_attn.k.scale_input', 'blocks.24.self_attn.v.scale_input',
'blocks.24.self_attn.o.scale_input', 'blocks.24.cross_attn.q.scale_input', 'blocks.24.
cross_attn.k.scale_input', 'blocks.24.cross_attn.v.scale_input', 'blocks.24.cross_attn.
o.scale_input', 'blocks.24.ffn.0.scale_input', 'blocks.24.ffn.2.scale_input', 'blocks.2
5.self_attn.q.scale_input', 'blocks.25.self_attn.k.scale_input', 'blocks.25.self_attn.v
.scale_input', 'blocks.25.self_attn.o.scale_input', 'blocks.25.cross_attn.q.scale_input
', 'blocks.25.cross_attn.k.scale_input', 'blocks.25.cross_attn.v.scale_input', 'blocks.
25.cross_attn.o.scale_input', 'blocks.25.ffn.0.scale_input', 'blocks.25.ffn.2.scale_inp
ut', 'blocks.26.self_attn.q.scale_input', 'blocks.26.self_attn.k.scale_input', 'blocks.
26.self_attn.v.scale_input', 'blocks.26.self_attn.o.scale_input', 'blocks.26.cross_attn
.q.scale_input', 'blocks.26.cross_attn.k.scale_input', 'blocks.26.cross_attn.v.scale_in
put', 'blocks.26.cross_attn.o.scale_input', 'blocks.26.ffn.0.scale_input', 'blocks.26.f
fn.2.scale_input', 'blocks.27.self_attn.q.scale_input', 'blocks.27.self_attn.k.scale_in
put', 'blocks.27.self_attn.v.scale_input', 'blocks.27.self_attn.o.scale_input', 'blocks
.27.cross_attn.q.scale_input', 'blocks.27.cross_attn.k.scale_input', 'blocks.27.cross_a
ttn.v.scale_input', 'blocks.27.cross_attn.o.scale_input', 'blocks.27.ffn.0.scale_input'
, 'blocks.27.ffn.2.scale_input', 'blocks.28.self_attn.q.scale_input', 'blocks.28.self_a
ttn.k.scale_input', 'blocks.28.self_attn.v.scale_input', 'blocks.28.self_attn.o.scale_i
nput', 'blocks.28.cross_attn.q.scale_input', 'blocks.28.cross_attn.k.scale_input', 'blo
cks.28.cross_attn.v.scale_input', 'blocks.28.cross_attn.o.scale_input', 'blocks.28.ffn.
0.scale_input', 'blocks.28.ffn.2.scale_input', 'blocks.29.self_attn.q.scale_input', 'bl
ocks.29.self_attn.k.scale_input', 'blocks.29.self_attn.v.scale_input', 'blocks.29.self_
attn.o.scale_input', 'blocks.29.cross_attn.q.scale_input', 'blocks.29.cross_attn.k.scal
e_input', 'blocks.29.cross_attn.v.scale_input', 'blocks.29.cross_attn.o.scale_input', '
blocks.29.ffn.0.scale_input', 'blocks.29.ffn.2.scale_input', 'head.head.scale_input']
Kijai's scaled fp8 5B Unet, rank 64 Turbo 5B LoRA, rank 128 FastWAN 5B LoRA, and some kind of merging magic 😬
Seems that these messages come from Kijai's repacked Unet and mean nothing for generation process.
@mistporyvaev cheers, great job! it seems to be faster and consume less resources that Kijai's turbo model. would be cool to see an NSFW merge of this as well, but with the lack of 5b loras for general anatomy I'm guessing that wouldn't be possible?
@TheNecr0mancer yep 😐
@mistporyvaev reupload the actual workflow p l e a s e
@testerweed695 for which version?
This is amazing! I've been searching for low-VRAM (8gb) Wan2.2-I2V-A14B models and workflows, and this one is my top pick so far. It’s fast and produces excellent results, surpassing the same 4 steps GGUF Q5_K_S (high/low-noise) in quality for my needs.
Thank you 🤩
RAM overflow happens on loading model with 32 Gb RAM.
Because you forgot to set swap file size at ~100Gb
@mistporyvaev I hate swap files.
@yano2mch sometimes there is no other way
@mistporyvaev True. I prefer having enough RAM that i can just disable it entirely. I thought 32GB was enough at one time. But just swapping between big applications and them not doing much (for which SWAP works great for) is no longer the case. You really need just a lot more resources.
Version 5B, have an NSFW filter? Can I generate sexually explicit images and videos?
5B version is standard 5B model without any content modifications. To generate something special you should just apply any suitable LoRA.
Look LoRAs with this search:
help me please i looking for this checkpoint wanLOVELowVRAMImageTo_i2vWan21.safetensors
and this lora
allononensfw
please
checkpoint is here, it's version is Wan 2.1 https://civitai.com/api/download/models/2129615?type=Model&format=SafeTensor&size=full&fp=fp8
all-in-one nsfw LoRA is here, it's version is Wan 2.2, so it WILL NOT work with checkpoint above
https://huggingface.co/boboperiod/allinone_nsfw/tree/main?not-for-all-audiences=true
i wish i had 64gb rams so it doesnt take like 4minutes just to load things
I hope your swap file is placed on fast ssd.
Few months ago upgraded to 128Gb; Extracting a lot of images to optimize and work on a ramdrive feels a lot better/faster than constant real disk access (ignoring caching, or running a game like skyrim all from the ramdrive...).
great model. does anyone has workflow using this model for long video (30-60s)?
How can a 21GB model (WAN 2.1 14B) run on a 4GB VRAM card?
Calculations are performed on the graphics card, and 4GB is sufficient. The model itself resides in regular RAM; only the necessary portions of data are transferred to VRAM. This reduces performance, but by using lightning LoRA, acceptable execution times can be achieved. All adequate software, such as ComfyUI, works this way; it doesn't attempt to load the entire model into VRAM if there isn't enough.
@mistporyvaev How does that work? I have an AMD GPU, and I always get OOM errors when I try to make videos at more than 240p resolution. Could you tell me if I need to do something specific, or if there’s anything else I can do?
@xmasherxpro how many VRAM do you have? At which stage of generation the OOM happens?
if i let it rain on a person, it is all yellow.. what happens
yellow rain maybe? ☔
I'm new to working with WAN, and with comfyUI in general. I spent two days setting up and solving startup problems. MY BRAIN ALMOST EXPLODED!!! And I still don't understand how this is supposed to work. I upload an image, write a prompt, but in the end the character does anything but what I wrote.
(Google translate)
Try to use greater value of model shift.
after trying a lot of different low vram models, this takes the gold, seriously i cant believe how good the outputs are getting without even using a gazillion descriptions in the prompt, kudos to you OP, amazing work.