
WAS Node Suite - ComfyUI - WAS#0263
ComfyUI is an advanced node based UI utilizing Stable Diffusion. It allows you to create customized workflows such as image post processing, or conversions.
Latest Version Download
A node suite for ComfyUI with many new nodes, such as image processing, text processing, and more.
Share Workflows to the workflows wiki. Preferably embedded PNGs with workflows, but JSON is OK too. You can use this tool to add a workflow to a PNG file easily
Important Updates
[Updated 5/29/2023]
ASCIIis deprecated. The new preferred method of text node output isSTRING. This is a change fromASCIIso that it is more clear what data is being passed.The
was_suite_config.jsonwill automatically setuse_legacy_ascii_texttofalse.
Video Nodes - There are two new video nodes,
Write to VideoandCreate Video from Path. These are experimental nodes.
Current Nodes:
BLIP Analyze Image: Get a text caption from a image, or interrogate the image with a question.
Model will download automatically from default URL, but you can point the download to another location/caption model in
was_suite_configModels will be stored in
ComfyUI/models/blip/checkpoints/
SAM Model Loader: Load a SAM Segmentation model
SAM Parameters: Define your SAM parameters for segmentation of a image
SAM Parameters Combine: Combine SAM parameters
SAM Image Mask: SAM image masking
Image Bounds: Bounds a image
Inset Image Bounds: Inset a image bounds
Bounded Image Blend: Blend bounds image
Bounded Image Blend with Mask: Blend a bounds image by mask
Bounded Image Crop: Crop a bounds image
Bounded Image Crop with Mask: Crop a bounds image by mask
Cache Node: Cache Latnet, Tensor Batches (Image), and Conditioning to disk to use later.
CLIPTextEncode (NSP): Parse noodle soups from the NSP pantry, or parse wildcards from a directory containing A1111 style wildacrds.
Wildcards are in the style of
__filename__, which also includes subdirectories like__appearance/haircolour__(if you noodle_key is set to__)You can set a custom wildcards path in
was_suite_config.jsonfile with key:"wildcards_path": "E:\\python\\automatic\\webui3\\stable-diffusion-webui\\extensions\\sd-dynamic-prompts\\wildcards"If no path is set the wildcards dir is located at the root of WAS Node Suite as
/wildcards
Conditioning Input Switch: Switch between two conditioning inputs.
Constant Number
Create Grid Image: Create a image grid from images at a destination with customizable glob pattern. Optional border size and color.
Create Morph Image: Create a GIF/APNG animation from two images, fading between them.
Create Morph Image by Path: Create a GIF/APNG animation from a path to a directory containing images, with optional pattern.
Create Video from Path: Create video from images from a specified path.
CLIPSeg Masking: Mask a image with CLIPSeg and return a raw mask
CLIPSeg Masking Batch: Create a batch image (from image inputs) and batch mask with CLIPSeg
Dictionary to Console: Print a dictionary input to the console
Image Analyze
Black White Levels
RGB Levels
Depends on
matplotlib, will attempt to install on first run
Diffusers Hub Down-Loader: Download a diffusers model from the HuggingFace Hub and load it
Image Batch: Create one batch out of multiple batched tensors.
Image Blank: Create a blank image in any color
Image Blend by Mask: Blend two images by a mask
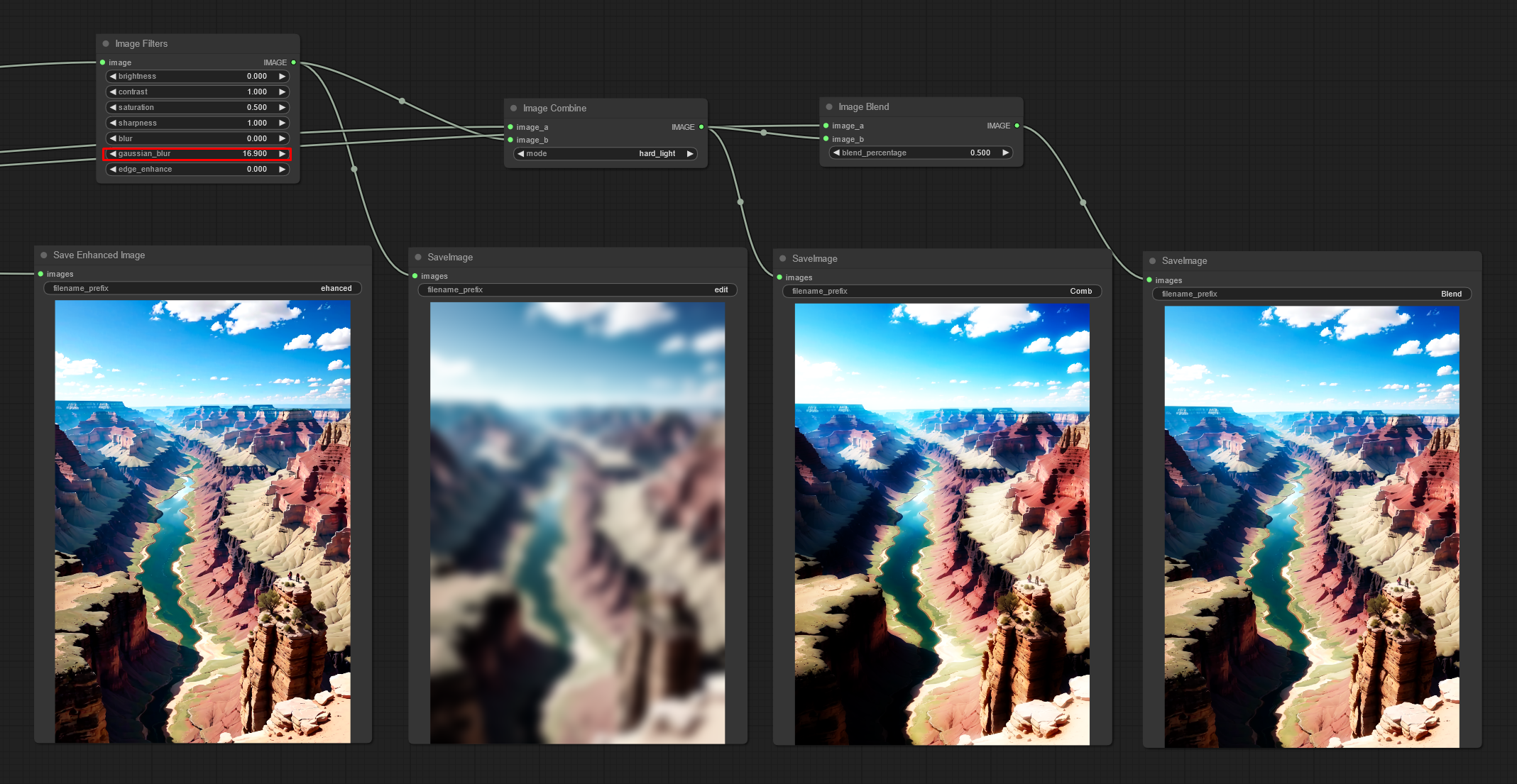
Image Blend: Blend two images by opacity
Image Blending Mode: Blend two images by various blending modes
Image Bloom Filter: Apply a high-pass based bloom filter
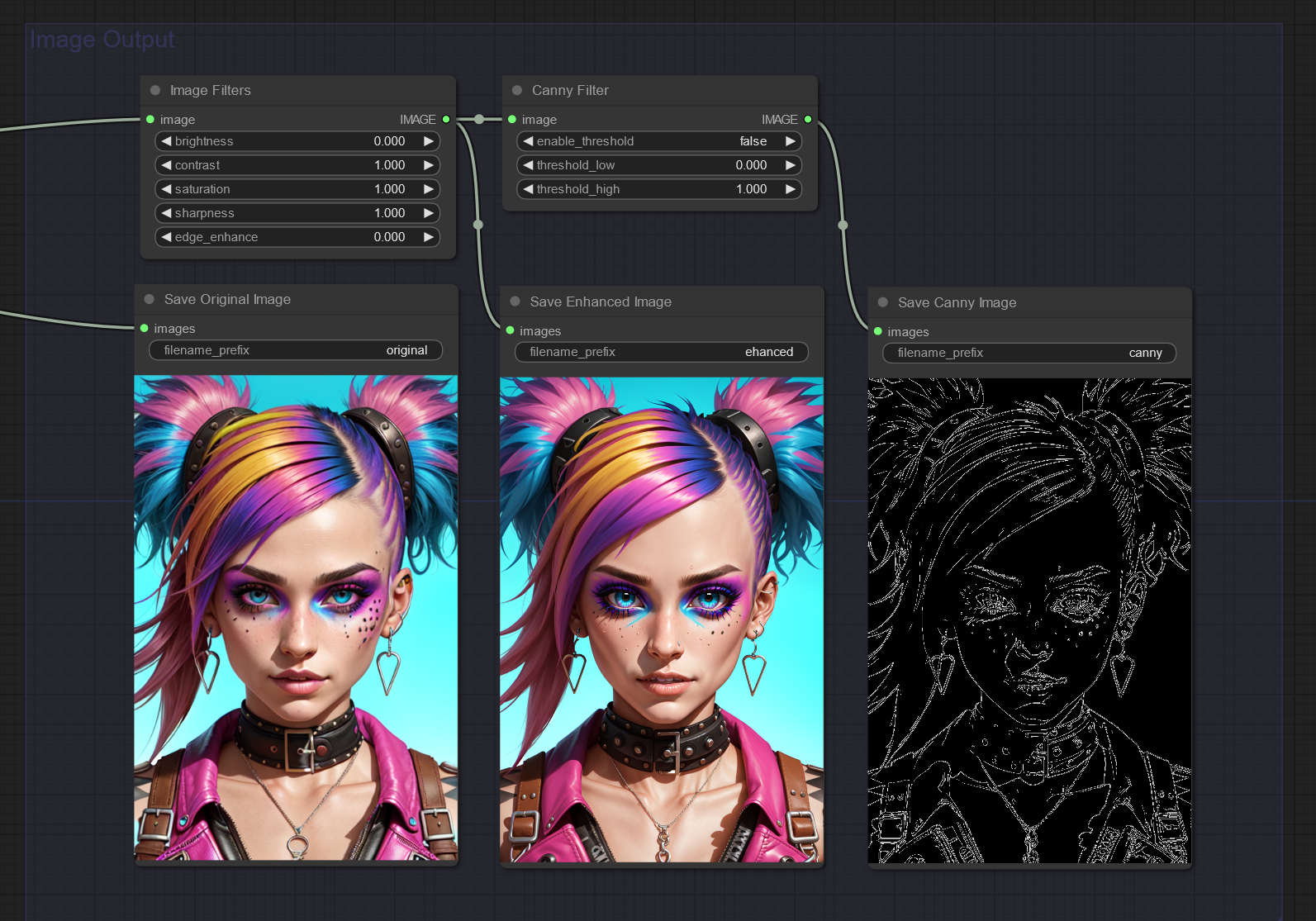
Image Canny Filter: Apply a canny filter to a image
Image Chromatic Aberration: Apply chromatic aberration lens effect to a image like in sci-fi films, movie theaters, and video games
Image Color Palette
Generate a color palette based on the input image.
Depends on
scikit-learn, will attempt to install on first run.
Supports color range of 8-256
Utilizes font in
./res/unless unavailable, then it will utilize internal better then nothing font.
Image Crop Face: Crop a face out of a image
Limitations:
Sometimes no faces are found in badly generated images, or faces at angles
Sometimes face crop is black, this is because the padding is too large and intersected with the image edge. Use a smaller padding size.
face_recognition mode sometimes finds random things as faces. It also requires a [CUDA] GPU.
Only detects one face. This is a design choice to make it's use easy.
Notes:
Detection runs in succession. If nothing is found with the selected detection cascades, it will try the next available cascades file.
Image Crop Location: Crop a image to specified location in top, left, right, and bottom locations relating to the pixel dimensions of the image in X and Y coordinats.
Image Crop Square Location: Crop a location by X/Y center, creating a square crop around that point.
Image Displacement Warp: Warp a image by a displacement map image by a given amplitude.
Image Dragan Photography Filter: Apply a Andrzej Dragan photography style to a image
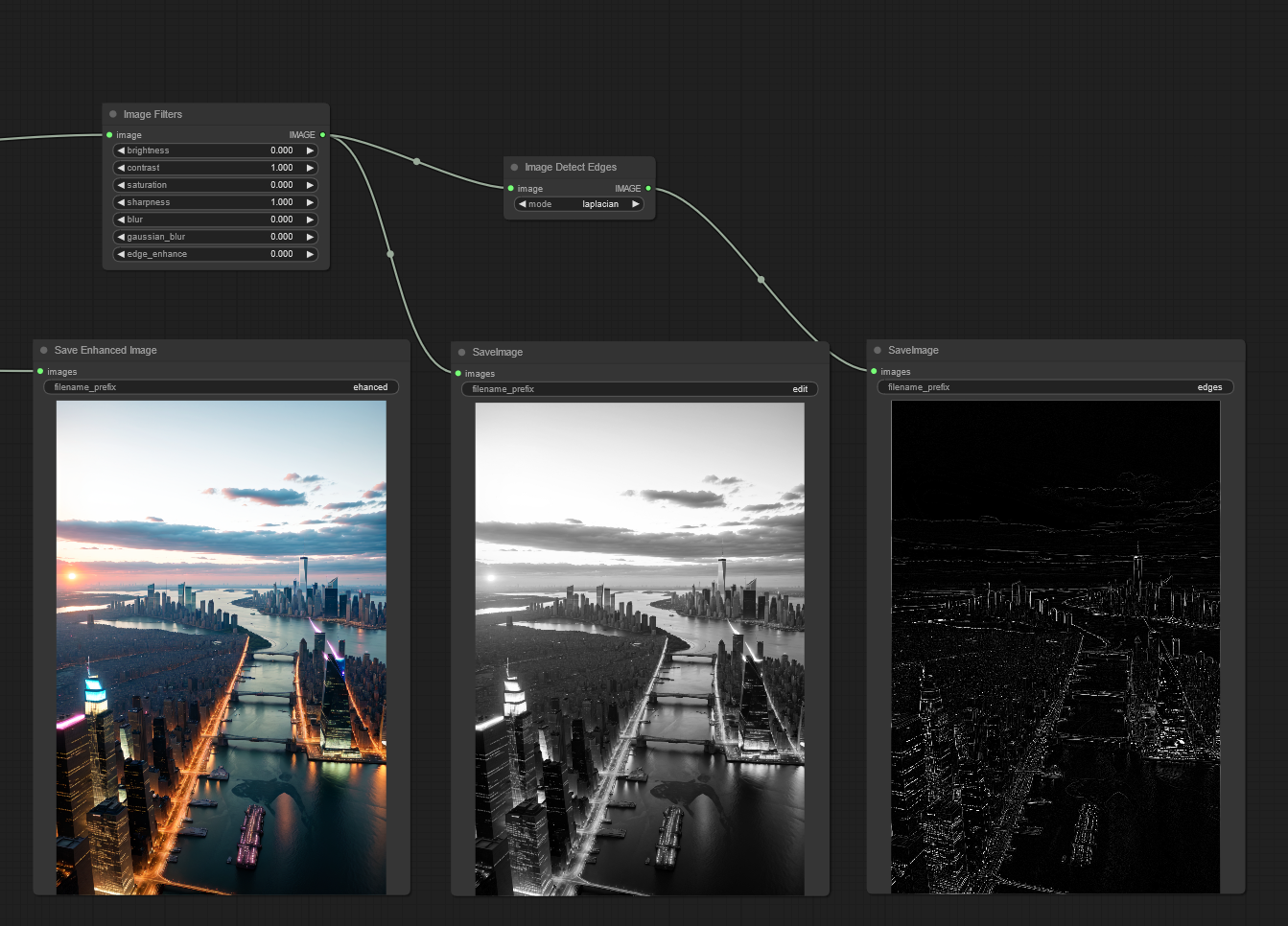
Image Edge Detection Filter: Detect edges in a image
Image Film Grain: Apply film grain to a image
Image Filter Adjustments: Apply various image adjustments to a image
Image Flip: Flip a image horizontal, or vertical
Image Gradient Map: Apply a gradient map to a image
Image Generate Gradient: Generate a gradient map with desired stops and colors
Image High Pass Filter: Apply a high frequency pass to the image returning the details
Image History Loader: Load images from history based on the Load Image Batch node. Can define max history in config file. (requires restart to show last sessions files at this time)
Image Input Switch: Switch between two image inputs
Image Levels Adjustment: Adjust the levels of a image
Image Load: Load a image from any path on the system, or a url starting with
httpImage Median Filter: Apply a median filter to a image, such as to smooth out details in surfaces
Image Mix RGB Channels: Mix together RGB channels into a single iamge
Image Monitor Effects Filter: Apply various monitor effects to a image
Digital Distortion
A digital breakup distortion effect
Signal Distortion
A analog signal distortion effect on vertical bands like a CRT monitor
TV Distortion
A TV scanline and bleed distortion effect
Image Nova Filter: A image that uses a sinus frequency to break apart a image into RGB frequencies
Image Perlin Noise: Generate perlin noise
Image Perlin Power Fractal: Generate a perlin power fractal
Image Paste Face Crop: Paste face crop back on a image at it's original location and size
Features a better blending funciton than GFPGAN/CodeFormer so there shouldn't be visible seams, and coupled with Diffusion Result, looks better than GFPGAN/CodeFormer.
Image Paste Crop: Paste a crop (such as from Image Crop Location) at it's original location and size utilizing the
crop_datanode input. This uses a different blending algorithm then Image Paste Face Crop, which may be desired in certain instances.Image Power Noise: Generate power-law noise
frequency: The frequency parameter controls the distribution of the noise across different frequencies. In the context of Fourier analysis, higher frequencies represent fine details or high-frequency components, while lower frequencies represent coarse details or low-frequency components. Adjusting the frequency parameter can result in different textures and levels of detail in the generated noise. The specific range and meaning of the frequency parameter may vary depending on the noise type.
attenuation: The attenuation parameter determines the strength or intensity of the noise. It controls how much the noise values deviate from the mean or central value. Higher values of attenuation lead to more significant variations and a stronger presence of noise, while lower values result in a smoother and less noticeable noise. The specific range and interpretation of the attenuation parameter may vary depending on the noise type.
noise_type: The tyoe of Power-Law noise to generate (white, grey, pink, green, blue)
Image Paste Crop by Location: Paste a crop top a custom location. This uses the same blending algorithm as Image Paste Crop.
Image Pixelate: Turn a image into pixel art! Define the max number of colors, the pixelation mode, the random state, and max iterations, and max those sprites shine.
Image Remove Background (Alpha): Remove the background from a image by threshold and tolerance.
Image Remove Color: Remove a color from a image and replace it with another
Image Resize
Image Rotate: Rotate an image
Image Save: A save image node with format support and path support. (Bug: Doesn't display image
Image Seamless Texture: Create a seamless texture out of a image with optional tiling
Image Select Channel: Select a single channel of an RGB image
Image Select Color: Return the select image only on a black canvas
Image Shadows and Highlights: Adjust the shadows and highlights of an image
Image Size to Number: Get the
widthandheightof an input image to use with Number nodes.Image Stitch: Stitch images together on different sides with optional feathering blending between them.
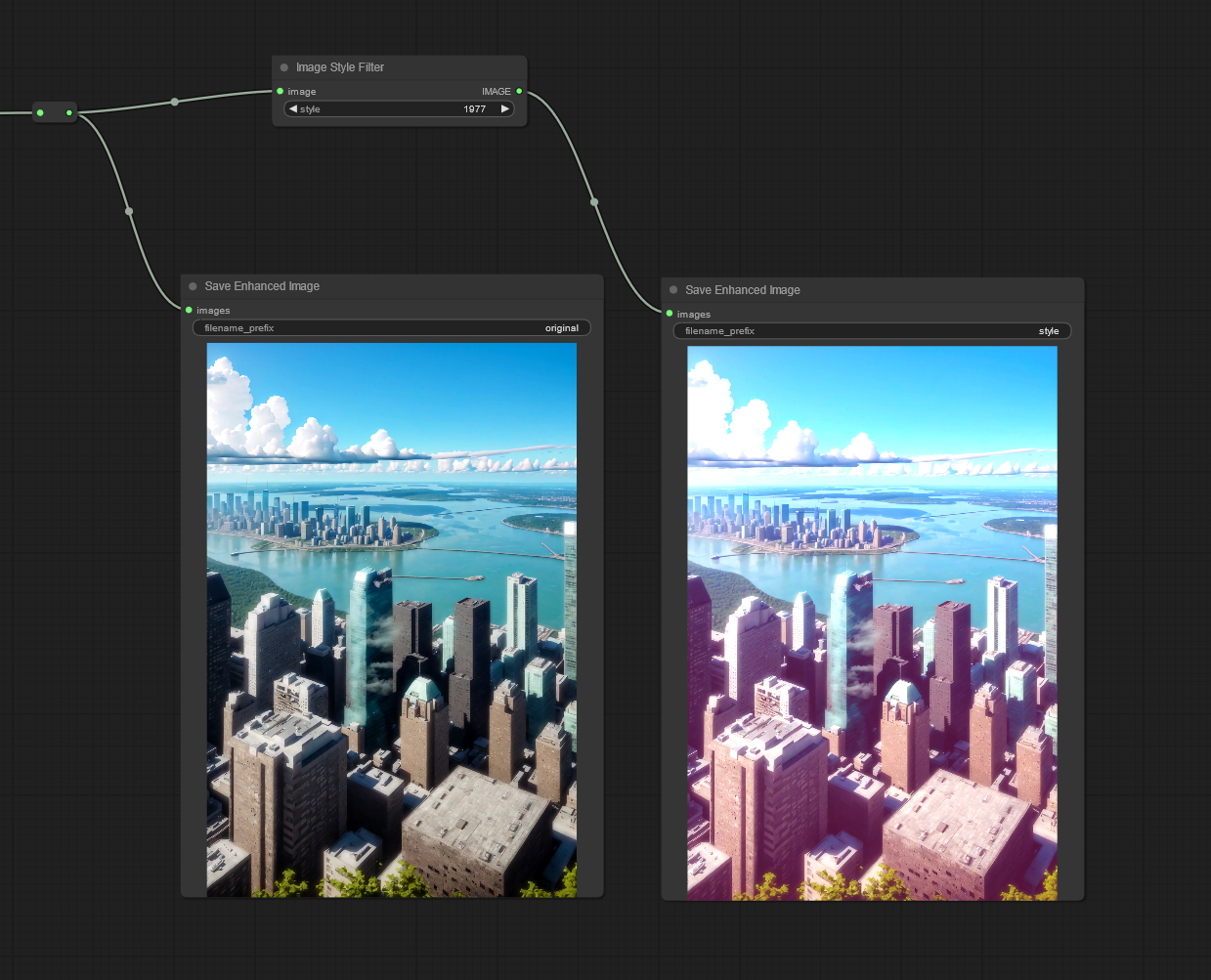
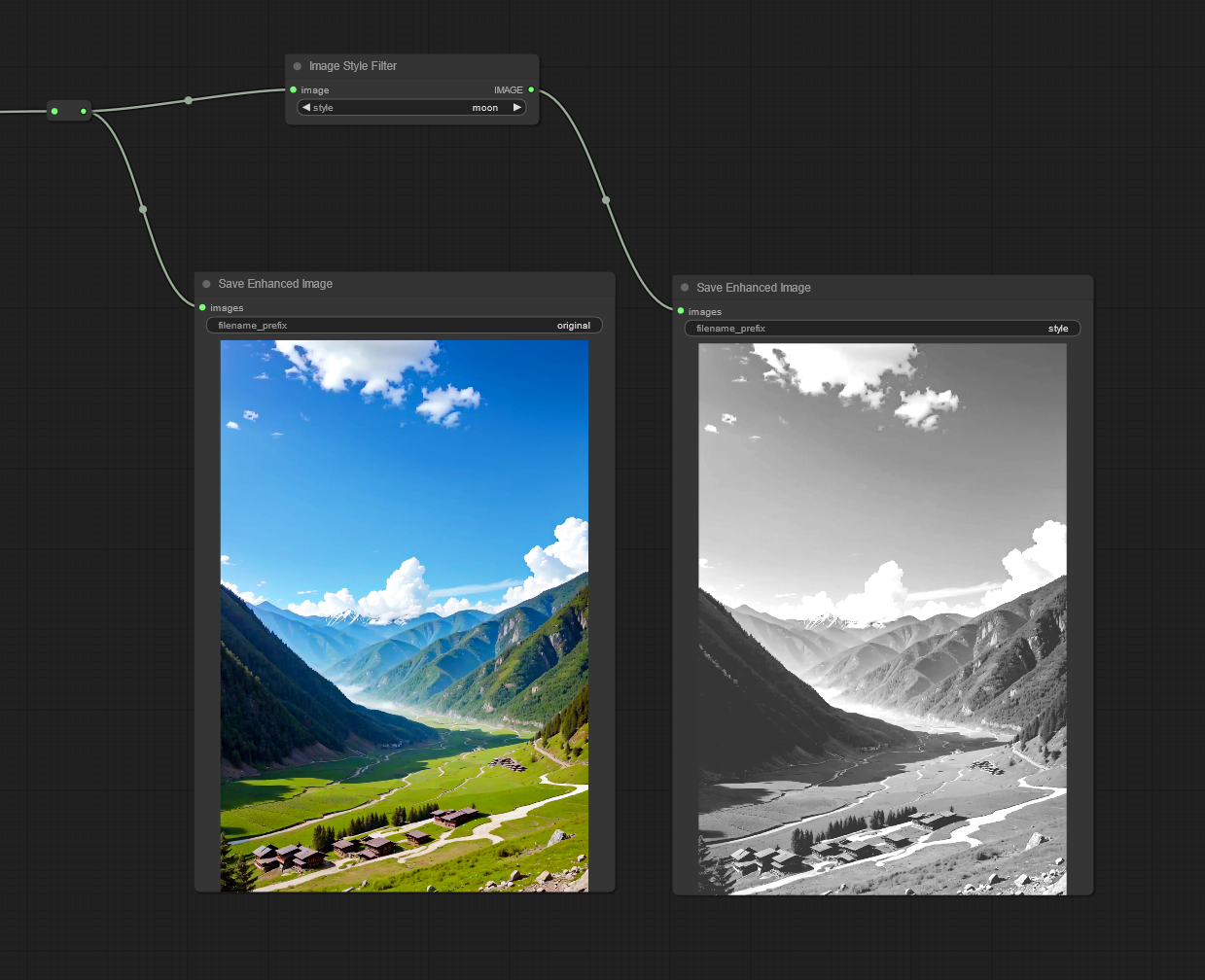
Image Style Filter: Style a image with Pilgram instragram-like filters
Depends on
pilgrammodule
Image Threshold: Return the desired threshold range of a image
Image Tile: Split a image up into a image batch of tiles. Can be used with Tensor Batch to Image to select a individual tile from the batch.
Image Transpose
Image fDOF Filter: Apply a fake depth of field effect to an image
Image to Latent Mask: Convert a image into a latent mask
Image to Noise: Convert a image into noise, useful for init blending or init input to theme a diffusion.
Image to Seed: Convert a image to a reproducible seed
Image Voronoi Noise Filter
A custom implementation of the worley voronoi noise diagram
Input Switch (Disable until
*wildcard fix)KSampler (WAS): A sampler that accepts a seed as a node inpu
Load Cache: Load cached Latent, Tensor Batch (image), and Conditioning files.
Load Text File
Now supports outputting a dictionary named after the file, or custom input.
The dictionary contains a list of all lines in the file.
Load Batch Images
Increment images in a folder, or fetch a single image out of a batch.
Will reset it's place if the path, or pattern is changed.
pattern is a glob that allows you to do things like
**/*to get all files in the directory and subdirectory or things like*.jpgto select only JPEG images in the directory specified.
Mask to Image: Convert
MASKtoIMAGEMask Batch to Mask: Return a single mask from a batch of masks
Mask Invert: Invert a mask.
Mask Add: Add masks together.
Mask Subtract: Subtract from a mask by another.
Mask Dominant Region: Return the dominant region in a mask (the largest area)
Mask Minority Region: Return the smallest region in a mask (the smallest area)
Mask Arbitrary Region: Return a region that most closely matches the size input (size is not a direct representation of pixels, but approximate)
Mask Smooth Region: Smooth the boundaries of a mask
Mask Erode Region: Erode the boundaries of a mask
Mask Dilate Region: Dilate the boundaries of a mask
Mask Fill Region: Fill holes within the masks regions
Mask Ceiling Region": Return only white pixels within a offset range.
Mask Floor Region: Return the lower most pixel values as white (255)
Mask Threshold Region: Apply a thresholded image between a black value and white value
Mask Gaussian Region: Apply a Gaussian blur to the mask
Masks Combine Masks: Combine 2 or more masks into one mask.
Masks Combine Batch: Combine batched masks into one mask.
ComfyUI Loaders: A set of ComfyUI loaders that also output a string that contains the name of the model being loaded.
Latent Noise Injection: Inject latent noise into a latent image
Latent Size to Number: Latent sizes in tensor width/height
Latent Upscale by Factor: Upscale a latent image by a factor
Latent Input Switch: Switch between two latent inputs
Logic Boolean: A simple
1or0output to use with logicMiDaS Depth Approximation: Produce a depth approximation of a single image input
MiDaS Mask Image: Mask a input image using MiDaS with a desired color
Number Operation
Number to Seed
Number to Float
Number Input Switch: Switch between two number inputs
Number Input Condition: Compare between two inputs or against the A input
Number to Int
Number to String
Number to Text
Random Number
Save Text File: Save a text string to a file
Seed: Return a seed
Tensor Batch to Image: Select a single image out of a latent batch for post processing with filters
Text Add Tokens: Add custom tokens to parse in filenames or other text.
Text Add Token by Input: Add custom token by inputs representing single single line name and value of the token
Text Compare: Compare two strings. Returns a boolean if they are the same, a score of similarity, and the similarity or difference text.
Text Concatenate: Merge two strings
Text Dictionary Update: Merge two dictionaries
Text File History: Show previously opened text files (requires restart to show last sessions files at this time)
Text Find and Replace: Find and replace a substring in a string
Text Find and Replace by Dictionary: Replace substrings in a ASCII text input with a dictionary.
The dictionary keys are used as the key to replace, and the list of lines it contains chosen at random based on the seed.
Text Input Switch: Switch between two text inputs
Text List: Create a list of text strings
Text Concatenate: Merge lists of strings
Text Multiline: Write a multiline text string
Text Parse A1111 Embeddings: Convert embeddings filenames in your prompts to
embedding:[filename]]format based on your/ComfyUI/models/embeddings/files.Text Parse Noodle Soup Prompts: Parse NSP in a text input
Text Parse Tokens: Parse custom tokens in text.
Text Random Line: Select a random line from a text input string
Text String: Write a single line text string value
Text to Conditioning: Convert a text string to conditioning.
True Random.org Number Generator: Generate a truly random number online from atmospheric noise with Random.org
Write to Morph GIF: Write a new frame to an existing GIF (or create new one) with interpolation between frames.
Write to Video: Write a frame as you generate to a video (Best used with FFV1 for lossless images)
Extra Nodes
CLIPTextEncode (BlenderNeko Advanced + NSP): Only available if you have BlenderNeko's Advanced CLIP Text Encode. Allows for NSP and Wildcard use with their advanced CLIPTextEncode.
Video Nodes
Codecs
You can use codecs that are available to your ffmpeg binaries by adding their fourcc ID (in one string), and appropriate container extension to the was_suite_config.json
Example H264 Codecs (Defaults)
"ffmpeg_extra_codecs": {
"avc1": ".mp4",
"h264": ".mkv"
}
Notes
For now I am only supporting Windows installations for video nodes.
I do not have access to Mac or a stand-alone linux distro. If you get them working and want to PR a patch/directions, feel free.
Video nodes require FFMPEG. You should download the proper FFMPEG binaries for you system and set the FFMPEG path in the config file.
Additionally, if you want to use H264 codec need to download OpenH264 1.8.0 and place it in the root of ComfyUI (Example:
C:\ComfyUI_windows_portable).FFV1 will complain about invalid container. You can ignore this. The resulting MKV file is readable. I have not figured out what this issue is about. Documentaion tells me to use MKV, but it's telling me it's unsupported.
If you know how to resolve this, I'd love a PR
Write to Videonode should use a lossless video codec or when it copies frames, and reapplies compression, it will start expontentially ruining the starting frames run to run.
Text Tokens
Text tokens can be used in the Save Text File and Save Image nodes. You can also add your own custom tokens with the Text Add Tokens node.
The token name can be anything excluding the : character to define your token. It can also be simple Regular Expressions.
Built-in Tokens
[time]
The current system microtime
[time(
format_code)]The current system time in human readable format. Utilizing datetime formatting
Example:
[hostname]_[time]__[time(%Y-%m-%d__%I-%M%p)]would output: SKYNET-MASTER_1680897261__2023-04-07__07-54PM
[hostname]
The hostname of the system executing ComfyUI
[user]
The user that is executing ComfyUI
Other Features
Import AUTOMATIC1111 WebUI Styles
When using the latest builds of WAS Node Suite a was_suite_config.json file will be generated (if it doesn't exist). In this file you can setup a A1111 styles import.
Run ComfyUI to generate the new
/custom-nodes/was-node-suite-comfyui/was_Suite_config.jsonfile.Open the
was_suite_config.jsonfile with a text editor.Replace the
webui_stylesvalue fromNoneto the path of your A1111 styles file called styles.csv. Be sure to use double backslashes for Windows paths.Example
C:\\python\\stable-diffusion-webui\\styles.csv
Restart ComfyUI
Select a style with the
Prompt Styles Node.The first ASCII output is your positive prompt, and the second ASCII output is your negative prompt.
You can set webui_styles_persistent_update to true to update the WAS Node Suite styles from WebUI every start of ComfyUI
Recommended Installation:
If you're running on Linux, or non-admin account on windows you'll want to ensure /ComfyUI/custom_nodes, was-node-suite-comfyui, and WAS_Node_Suite.py has write permissions.
Navigate to your
/ComfyUI/custom_nodes/folderRun
git clone https://github.com/WASasquatch/was-node-suite-comfyui/Navigate to your
was-node-suite-comfyuifolderPortable/venv:
Run
path/to/ComfUI/python_embeded/python.exe -m pip install -r requirements.txt
With system python
Run
pip install -r requirements.txt
Start ComfyUI
WAS Suite should uninstall legacy nodes automatically for you.
Tools will be located in the WAS Suite menu.
Alternate Installation:
If you're running on Linux, or non-admin account on windows you'll want to ensure /ComfyUI/custom_nodes, and WAS_Node_Suite.py has write permissions.
Download
WAS_Node_Suite.pyMove the file to your
/ComfyUI/custom_nodes/folderWAS Node Suite will attempt install dependencies on it's own, but you may need to manually do so. The dependencies required are in the
requirements.txton this repo. See installation steps above.Start, or Restart ComfyUI
WAS Suite should uninstall legacy nodes automatically for you.
Tools will be located in the WAS Suite menu.
This method will not install the resources required for Image Crop Face node, and you'll have to download the ./res/ folder yourself.
Installing on Colab
Create a new cell and add the following code, then run the cell. You may need to edit the path to your custom_nodes folder. You can also use the colab hosted here
!git clone https://github.com/WASasquatch/was-node-suite-comfyui /content/ComfyUI/custom_nodes/was-node-suite-comfyuiRestart Colab Runtime (don't disconnect)
Tools will be located in the WAS Suite menu.
Github Repository: https://github.com/WASasquatch/was-node-suite-comfyui
❤ Hearts and 🖼️ Reviews let me know you want moarr! :3
Description
Changes name of file 'Canny_Filter_WAS.py' to 'Image_Canny_Filter_WAS.py` be sure to remove the old version.
Fixes the edge enhancement to be a range of 0 to 1 where 0 is no effect.
Adds Image Blank - Create blank images in any RGB color
Adds the Nova Filter - The nova filter uses some trig to break up a image into different RGB color components, which can be used with other nodes to create image style effects.
Adds Film Grain - Add film grain to images with highlighting and super sampling (for better quality noise)
Adds Image Flip - Flip horizontal or vertical
Adds Image Rotate - Rotate images
FAQ
Comments (23)
Can you go to github and be a contributor to comfyui directly? I think the seed node is one of the most requested things. It should be standard. And the samplers should have an option to receive input from a seed node or not.
I think having multiple samplers in one "pass" is one of the biggest advantages over other UIs like automatic.
Great work.
Multiple samplers is also why I stopped using automatic. ComfyUI let's you do amazing things. For instance, I don't even know if you can do area composition in automatic at all.
@Meyrink Yeah you can do sort of an area composition with automatic with an extension called latent couple, but its more like the latent composite of comfyUI and you get alot of bleeding of prompt text.
I did some tests trying to recreate some of the stuff I was doing in comfy, but they both function so differently that its nearly impossible.
In Auto you have to assign weights to the areas you specify where in comfy you can only do that if you set up all areas, including the background.
Although I wish Comfy had a similar tool like automatic has. There is an overlay python program that calculates the areas with grids to use in the latent couple extension. With this https://github.com/Zuntan03/LatentCoupleHelper
But since comfy is pretty new, I suspect there will be alot of changes and quality of life additions.
Automatic is more of a oneshot UI where you have to send you image around to do certain things, whereas in comfy you can set everything up form the beginning and just click a button and it goes through all the steps.
Hell, you can even make an img2img chain manipulating your picture with multiple different models. In automatic you would have to change the model manually every time for every picture for every step.
@ctdde And the models load really fast when setting up a job utilizing multiple models, and AI models, etc.
I have been watching the repo and seeing how it matures. I have some concerns. I don't understand the web and server side well, and it looks like the project is mainly abandoned by 2 years, while still lacking a lot of functionality, requests, and even some bug-level issues (like groups being draggable by anywhere instead of a header or some sort of triggering mechanism like holding a key down.
Would it be possible to host these on huggingface so I can use them with google colab?
Bug find : If batch_size>1,It will raise exception.
Great Work!!!
Ah, yes, most all these are for post processing, which expects a single image. I could add batching, but depending on what people are doing, like adding film grain, or nova, etc, it would take ages to do all the images if they had a batch of 6-12.
Biggest issue is any operation requiring PIL/CV2 requires converting the tensors to images in a loop, but then there isn't a way that I am aware of to cat the tensors back together without knowing how many, and manually writing it.
@WAS maybe convert batch to single images? Like pick one you want from batch? Be more work but could then use batches
@WAS yeal, Such as Game-Concept-Art need batching 6-10 for a Color-Script-Contronet output :)
@gamert I tried doing some batching on the heavy nodes and to test and it really isn't worth it from an end user perspective with single threaded operations like image editing. I think it's best to have a batch to image so you can select a image from a batch and run it through a post processing nodes setup.
@WAS Last night I had the same idea as your "converting the tensors to images in a loop", then vice versa . May be Itis the cheapest implemention. :)
@gamert I made a request to not use tuple outputs since they can't be modified, added to, removed, etc and not suited for something like passing data to manipulate.
@gamert I've added a node which you can use to select images out of a batch to do processing on. I have also add a Load Image Batch node.
@WAS aha, Great~ Thank you:)
@WAS is there a guide for the load image batch because im only ghetting single images with it
@Ragamuffin20 No guide. But did you change it to increment and not Single Image mode?
hi it is me , on my last update on my tool i was able to create text image , i wanted to use your canny filter with it so i can use the output on control net but all vea tools wont accept the canny output and gives weird error may i ask that you check it , i wanted to add reference to your tool as a requirement for that usecase
Yeah I'll check it. Probably forgot to change it's mode or something.
Can you post the error you got?
@WAS Traceback (most recent call last):
File "F:\ComfyUI_windows_portable\ComfyUI\execution.py", line 174, in execute
executed += recursive_execute(self.server, prompt, self.outputs, x, extra_data)
File "F:\ComfyUI_windows_portable\ComfyUI\execution.py", line 54, in recursive_execute
executed += recursive_execute(server, prompt, outputs, input_unique_id, extra_data)
File "F:\ComfyUI_windows_portable\ComfyUI\execution.py", line 54, in recursive_execute
executed += recursive_execute(server, prompt, outputs, input_unique_id, extra_data)
File "F:\ComfyUI_windows_portable\ComfyUI\execution.py", line 63, in recursive_execute
outputs[unique_id] = getattr(obj, obj.FUNCTION)(**input_data_all)
File "F:\ComfyUI_windows_portable\ComfyUI\nodes.py", line 683, in sample
return common_ksampler(model, seed, steps, cfg, sampler_name, scheduler, positive, negative, latent_image, denoise=denoise)
File "F:\ComfyUI_windows_portable\ComfyUI\nodes.py", line 652, in common_ksampler
samples = sampler.sample(noise, positive_copy, negative_copy, cfg=cfg, latent_image=latent_image, start_step=start_step, last_step=last_step, force_full_denoise=force_full_denoise, denoise_mask=noise_mask)
File "F:\ComfyUI_windows_portable\ComfyUI\comfy\samplers.py", line 443, in sample
samples = uni_pc.sample_unipc(self.model_wrap, noise, latent_image, sigmas, sampling_function=sampling_function, max_denoise=max_denoise, extra_args=extra_args, noise_mask=denoise_mask)
File "F:\ComfyUI_windows_portable\ComfyUI\comfy\extra_samplers\uni_pc.py", line 880, in sample_unipc
x = uni_pc.sample(img, timesteps=timesteps, skip_type="time_uniform", method="multistep", order=order, lower_order_final=True)
File "F:\ComfyUI_windows_portable\ComfyUI\comfy\extra_samplers\uni_pc.py", line 731, in sample
model_prev_list = [self.model_fn(x, vec_t)]
File "F:\ComfyUI_windows_portable\ComfyUI\comfy\extra_samplers\uni_pc.py", line 422, in model_fn
return self.data_prediction_fn(x, t)
File "F:\ComfyUI_windows_portable\ComfyUI\comfy\extra_samplers\uni_pc.py", line 404, in data_prediction_fn
noise = self.noise_prediction_fn(x, t)
File "F:\ComfyUI_windows_portable\ComfyUI\comfy\extra_samplers\uni_pc.py", line 398, in noise_prediction_fn
return self.model(x, t)
File "F:\ComfyUI_windows_portable\ComfyUI\comfy\extra_samplers\uni_pc.py", line 330, in model_fn
return noise_pred_fn(x, t_continuous)
File "F:\ComfyUI_windows_portable\ComfyUI\comfy\extra_samplers\uni_pc.py", line 298, in noise_pred_fn
output = sampling_function(model, x, t_input, **model_kwargs)
File "F:\ComfyUI_windows_portable\ComfyUI\comfy\samplers.py", line 195, in sampling_function
cond, uncond = calc_cond_uncond_batch(model_function, cond, uncond, x, timestep, max_total_area, cond_concat)
File "F:\ComfyUI_windows_portable\ComfyUI\comfy\samplers.py", line 170, in calc_cond_uncond_batch
c['control'] = control.get_control(input_x, timestep_, c['c_crossattn'], len(cond_or_uncond))
File "F:\ComfyUI_windows_portable\ComfyUI\comfy\sd.py", line 454, in get_control
self.cond_hint = resize_image_to(self.cond_hint_original, x_noisy, batched_number).to(self.control_model.dtype).to(self.device)
File "F:\ComfyUI_windows_portable\ComfyUI\comfy\sd.py", line 413, in resize_image_to
tensor = utils.common_upscale(tensor, target_latent_tensor.shape[3] 8, target_latent_tensor.shape[2] 8, 'nearest-exact', "center")
File "F:\ComfyUI_windows_portable\ComfyUI\comfy\utils.py", line 5, in common_upscale
old_width = samples.shape[3]
IndexError: tuple index out of range
@omar92 Fixed in latest version. Reason was output wasn't correct.
Should have been:
return ( pil2tensor(image_canny), )
Or:
return ( torch.from_numpy(np.array(image_canny).astype(np.float32) / 255.0).unsqueeze(0), )