Update the Florence version:Many people encounter dependency errors when using the Joy Caption plugin. I use Florence as a replacement—it’s easier for beginners to avoid these issues.
Not an upgraded version of the previous one.
By using an LLM to write prompts for CogVideoX-v1.5-5B I2V, it helps those who don't know how to write prompts or are too lazy to do so make better use of CogVideoX v1.5. It also allows users to choose to add guiding prompts or turn off the LLM feature and write prompts entirely on their own.
Although the v1.5 version supports any resolution, there are still differences in quality depending on the resolution. You can test multiple resolutions to find the best one.
For low VRAM users, please keep the following features enabled.
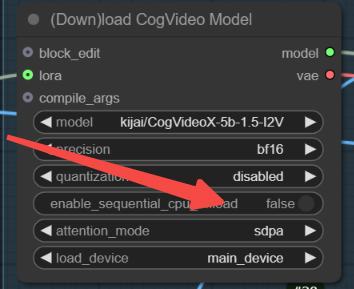
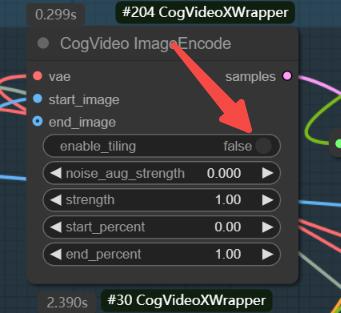
The GGUF version doesn't perform that well based on my tests, but v1.5 is still being updated, so we can expect better results in future versions.
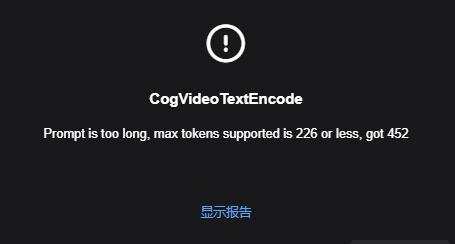
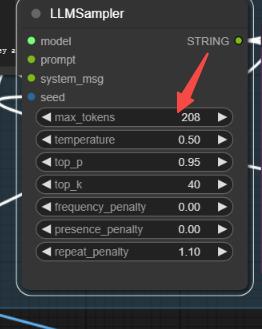
If this happens, it's because the LLM prompt is too long. You can change the random seed to regenerate, or modify the values below to reduce the tokens.
Description
Many people encounter dependency errors when using the Joy Caption plugin. I use Florence as a replacement—it’s easier for beginners to avoid these issues.
FAQ
Comments (19)
Hello, could you maybe provide some rendering time info, like what GPU you use and how long it take for one video? Thank you!
i never tried video gen mainly because i need little infos like that too... it would be be nice. thanks anywaqy for contributing !
It should run fine with 12GB of VRAM or more. My GPU is a 4090, and it takes about 3 minutes for a 1024**640 resolution on num_frame 49. The time varies with the generation resolution; for example, 1216**832 takes about 5 minutes. The time will be longer with num_frame 81.
RTX 3060 12GB handles this too. With flash-attn and not using GGUF version 60 frames 50steps with final output 768x1024 its about 20 minutes from image with bf16 precision of model and fp8_e4m3fn quantization + fuse sdpa + compiled at first run(was not very much longer) and vae tilling enabled. Epic workflow thanks!
Hi, can someone help me? In comfyui it asks me for Image Switch // RvTools and I have been able to install all of them except this one.
If you can understand the workflow, this node won't be necessary. You can connect the image on the right of 'Resize Image' to the 'start_image' on the left of 'CogVideo ImageEncode' to skip installing this node.
Go to custom_nodes directory and run "git clone https://github.com/Rvage0815/ComfyUI-RvTools.git" then restart comfyui and refresh.
Ok, thanks for your help :-)
Joy_caption
Error no file named pytorch_model.bin, model.safetensors, tf_model.h5, model.ckpt.index or flax_model.msgpack found in directory G:/comfyui/models/clip\siglip-so400m-patch14-384.
Recommend using the Florence version. There's no difference between the Florence version and the Joy Caption version, but Florence can help avoid many dependency errors.
joy caption:https://github.com/StartHua/Comfyui_CXH_joy_caption
I get:
LLMLoader
Failed to load model from file: Q:\ComfyUI\models\LLavacheckpoints\Meta-Llama-3.1-8B-Instruct-Q5_K_S.gguf
That's even though I have the file there 🤔
I have manually downloaded Meta-Llama-3.1-8B-Instruct-Q5_K_S.gguf and placed it into Q:\ComfyUI\models\LLavacheckpoints
Searching for the file online though I find atleast three different versions of the same name: 5.4GB, 5.6GB and 5.7GB 🤔
Actually this is the full error:
llama_model_loader: loaded meta data with 29 key-value pairs and 292 tensors from Q:\ComfyUI\models\LLavacheckpoints\Meta-Llama-3.1-8B-Instruct-Q5_K_S.gguf (version GGUF V3 (latest))
llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
llama_model_loader: - kv 0: general.architecture str = llama
llama_model_loader: - kv 1: general.type str = model
llama_model_loader: - kv 2: general.name str = Meta Llama 3.1 8B Instruct
llama_model_loader: - kv 3: general.finetune str = Instruct
llama_model_loader: - kv 4: general.basename str = Meta-Llama-3.1
llama_model_loader: - kv 5: general.size_label str = 8B
llama_model_loader: - kv 6: general.license str = llama3.1
llama_model_loader: - kv 7: general.tags arr[str,6] = ["facebook", "meta", "pytorch", "llam...
llama_model_loader: - kv 8: general.languages arr[str,8] = ["en", "de", "fr", "it", "pt", "hi", ...
llama_model_loader: - kv 9: llama.block_count u32 = 32
llama_model_loader: - kv 10: llama.context_length u32 = 131072
llama_model_loader: - kv 11: llama.embedding_length u32 = 4096
llama_model_loader: - kv 12: llama.feed_forward_length u32 = 14336
llama_model_loader: - kv 13: llama.attention.head_count u32 = 32
llama_model_loader: - kv 14: llama.attention.head_count_kv u32 = 8
llama_model_loader: - kv 15: llama.rope.freq_base f32 = 500000.000000
llama_model_loader: - kv 16: llama.attention.layer_norm_rms_epsilon f32 = 0.000010
llama_model_loader: - kv 17: general.file_type u32 = 16
llama_model_loader: - kv 18: llama.vocab_size u32 = 128256
llama_model_loader: - kv 19: llama.rope.dimension_count u32 = 128
llama_model_loader: - kv 20: tokenizer.ggml.model str = gpt2
llama_model_loader: - kv 21: tokenizer.ggml.pre str = llama-bpe
llama_model_loader: - kv 22: tokenizer.ggml.tokens arr[str,128256] = ["!", "\"", "#", "$", "%", "&", "'", ...
llama_model_loader: - kv 23: tokenizer.ggml.token_type arr[i32,128256] = [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, ...
llama_model_loader: - kv 24: tokenizer.ggml.merges arr[str,280147] = ["Ġ Ġ", "Ġ ĠĠĠ", "ĠĠ ĠĠ", "...
llama_model_loader: - kv 25: tokenizer.ggml.bos_token_id u32 = 128000
llama_model_loader: - kv 26: tokenizer.ggml.eos_token_id u32 = 128009
llama_model_loader: - kv 27: tokenizer.chat_template str = {% set loop_messages = messages %}{% ...
llama_model_loader: - kv 28: general.quantization_version u32 = 2
llama_model_loader: - type f32: 66 tensors
llama_model_loader: - type q5_K: 225 tensors
llama_model_loader: - type q6_K: 1 tensors
llm_load_vocab: special tokens definition check successful ( 256/128256 ).
llm_load_print_meta: format = GGUF V3 (latest)
llm_load_print_meta: arch = llama
llm_load_print_meta: vocab type = BPE
llm_load_print_meta: n_vocab = 128256
llm_load_print_meta: n_merges = 280147
llm_load_print_meta: n_ctx_train = 131072
llm_load_print_meta: n_embd = 4096
llm_load_print_meta: n_head = 32
llm_load_print_meta: n_head_kv = 8
llm_load_print_meta: n_layer = 32
llm_load_print_meta: n_rot = 128
llm_load_print_meta: n_embd_head_k = 128
llm_load_print_meta: n_embd_head_v = 128
llm_load_print_meta: n_gqa = 4
llm_load_print_meta: n_embd_k_gqa = 1024
llm_load_print_meta: n_embd_v_gqa = 1024
llm_load_print_meta: f_norm_eps = 0.0e+00
llm_load_print_meta: f_norm_rms_eps = 1.0e-05
llm_load_print_meta: f_clamp_kqv = 0.0e+00
llm_load_print_meta: f_max_alibi_bias = 0.0e+00
llm_load_print_meta: f_logit_scale = 0.0e+00
llm_load_print_meta: n_ff = 14336
llm_load_print_meta: n_expert = 0
llm_load_print_meta: n_expert_used = 0
llm_load_print_meta: causal attn = 1
llm_load_print_meta: pooling type = 0
llm_load_print_meta: rope type = 0
llm_load_print_meta: rope scaling = linear
llm_load_print_meta: freq_base_train = 500000.0
llm_load_print_meta: freq_scale_train = 1
llm_load_print_meta: n_yarn_orig_ctx = 131072
llm_load_print_meta: rope_finetuned = unknown
llm_load_print_meta: ssm_d_conv = 0
llm_load_print_meta: ssm_d_inner = 0
llm_load_print_meta: ssm_d_state = 0
llm_load_print_meta: ssm_dt_rank = 0
llm_load_print_meta: model type = 8B
llm_load_print_meta: model ftype = Q5_K - Small
llm_load_print_meta: model params = 8.03 B
llm_load_print_meta: model size = 5.21 GiB (5.57 BPW)
llm_load_print_meta: general.name = Meta Llama 3.1 8B Instruct
llm_load_print_meta: BOS token = 128000 '<|begin_of_text|>'
llm_load_print_meta: EOS token = 128009 '<|eot_id|>'
llm_load_print_meta: LF token = 128 'Ä'
llm_load_print_meta: EOT token = 128009 '<|eot_id|>'
llm_load_tensors: ggml ctx size = 0.30 MiB
llama_model_load: error loading model: done_getting_tensors: wrong number of tensors; expected 292, got 291
llama_load_model_from_file: failed to load model
!!! Exception during processing !!! Failed to load model from file: Q:\ComfyUI\models\LLavacheckpoints\Meta-Llama-3.1-8B-Instruct-Q5_K_S.gguf
Traceback (most recent call last):
File "Q:\ComfyUI\execution.py", line 323, in execute
output_data, output_ui, has_subgraph = get_output_data(obj, input_data_all, execution_block_cb=execution_block_cb, pre_execute_cb=pre_execute_cb)
File "Q:\ComfyUI\execution.py", line 198, in get_output_data
return_values = mapnode_over_list(obj, input_data_all, obj.FUNCTION, allow_interrupt=True, execution_block_cb=execution_block_cb, pre_execute_cb=pre_execute_cb)
File "Q:\ComfyUI\execution.py", line 169, in mapnode_over_list
process_inputs(input_dict, i)
File "Q:\ComfyUI\execution.py", line 158, in process_inputs
results.append(getattr(obj, func)(**inputs))
File "Q:\ComfyUI\custom_nodes\ComfyUI_VLM_nodes\nodes\suggest.py", line 292, in load_llm_checkpoint
llm = Llama(model_path = ckpt_path, chat_format="chatml", offload_kqv=True, f16_kv=True, use_mlock=False, embedding=False, n_batch=1024, last_n_tokens_size=1024, verbose=True, seed=42, n_ctx = max_ctx, n_gpu_layers=gpu_layers, n_threads=n_threads,)
File "Q:\ComfyUI\venv\lib\site-packages\llama_cpp\llama.py", line 338, in init
self._model = _LlamaModel(
File "Q:\ComfyUI\venv\lib\site-packages\llama_cpp\_internals.py", line 57, in init
raise ValueError(f"Failed to load model from file: {path_model}")
ValueError: Failed to load model from file: Q:\ComfyUI\models\LLavacheckpoints\Meta-Llama-3.1-8B-Instruct-Q5_K_S.gguf
@kallamamran Try updating Comfyui
Fyi there is an issue current if you try to install llama-cpp-python from the manager. Because it tries to install the version 0.3.5 but this one exist only for metal on macos. So you need to download the 0.3.4 from https://github.com/abetlen/llama-cpp-python/releases/tag/v0.3.4-cu124 and install it with a command similar to this :
C:\ComfyUI\ComfyUI_windows_portable\python_embeded\python.exe -m pip install C:\ComfyUI\llama_cpp_python-0.3.4-cp312-cp312-win_amd64.whl
Hi, In noticed this problem. However when I installed the WHL file you mention, I got another error, my python.exe in the folder D:\ComfyUI_windows_portable\python_embeded was no longer valid, it was 0 bytes and python no longer worked. Had to reinstall it. The ComfyUI I am running uses Python version 3.11, so installing 3.12 files causes a problem I think, of am I overlooking something?
When I run the WHL file - I get the error: ERROR: llama_cpp_python-0.3.4-cp312-cp312-win_amd64.whl is not a supported wheel on this platform.
Very excited to try the workflow!
Both versions seem to need a different version of the LLMloader/Sampler and fails to download Image switch. Do I need to install those manually?
https://gyazo.com/a732daf9f85c6d7fbf948dfd20fdf070
Did you ever solve this? I'm having the same issue.
It's the same problem for me.