
NEW LTX-2 Workflows here: https://civarchive.com/models/2318870
Workflow: Image -> Autocaption (Prompt) -> LTX Image to Video
LTX Prompt Enhancer (LTXPE) might have issues with latest Comfy and Lightricks update
Update July 20th 2025: GGUF Models for LTX 0.9.8:
Distilled model, works with V9.5: https://huggingface.co/QuantStack/LTXV-13B-0.9.8-distilled-GGUF/tree/main
Dev model, works with V9.0: https://huggingface.co/QuantStack/LTXV-13B-0.9.8-dev-GGUF/tree/main
(see "Model Card" in above links for LTX 0.9.8 VAE and textencoder downloads)
V9.5: LTX 0.9.7 Distilled Workflow supporting LTX 0.9.7 Distilled GGUF Model.
There is a workflow with Florence and another one with LTX Prompt Enhancer (LTXPE)
GGUF Model can be downloaded here:
https://huggingface.co/wsbagnsv1/ltxv-13b-0.9.7-distilled-GGUF/tree/main
VAE and Textencoder are identical to previous LTX 0.9.6 model (see V8.0 below)
LTX 0.9.7 Distilled is using only 8 steps and is very fast.
V9.0: LTX 0.9.7 Workflow supporting LTX 0.9.7 GGUF Model.
There is a workflow with Florence and another one with LTX Prompt Enhancer (LTXPE)
GGUF Model can be downloaded here:
https://huggingface.co/wsbagnsv1/ltxv-13b-0.9.7-dev-GGUF/tree/main
VAE and Textencoder are identical to previous LTX 0.9.6 model (see V8.0 below)
LTX 0.9.7 is a 13billion parameter model, previous versions only had 2b parameters, therefore it is more heavy on Vram usage and requires longer process time. Try V8.0 below with model 0.9.6 or V9.5 for very fast rendering.
V8.0: LTX 0.9.6 Workflow (dev and distilled GGUF model in same workflow)
there is a version with Florence2 Caption and a version with LTX Prompt Enhancer (LTXPE)
GGUF Models (Dev & Distilled) can be downloaded here:
https://huggingface.co/calcuis/ltxv0.9.6-gguf/tree/main
vae: pig_video_enhanced_vae_fp32-f16.gguf
Textencoder: t5xxl_fp32-q4_0.gguf
V7.0: LTX 0.9.5 Model Version GGUF with Wavespeed/Teacache.
LTX 0.9.5 GGUF Model and VAE: https://huggingface.co/calcuis/ltxv-gguf/tree/main
(vae_ltxv0.9.5_fp8_e4m3fn.safetensors)
Clip Textencoder: https://huggingface.co/city96/t5-v1_1-xxl-encoder-gguf/tree/main
There are 2 worklfows, a main workflow with florence caption only and additional one with florence and LTX prompt enhancer. Setup with Wavespeed (bypassed by default, Strg+B to activate)
workflow works with all GGUF models: 0.9 / 0.9.1 / 0.9.5
uncensored LLM for Prompt enhancer: https://huggingface.co/skshmjn/unsloth_llama-3.2-3B-instruct-uncenssored
-Outdated (march 2025)- V6.0: GGUF/TiledVAE Version & Masked Motion Blur Version
Updated the workflow with GGUF Models, which save Vram and run faster.
There is a Standard Version, which uses just the GGUF Models and a GGUF+TiledVae+Clear Vram Version, that reduces Vram requirements even further. Tested the larger GGUF model (Q8) with resolution of 1024, 161 frames and 32 steps , the GGUF Version peaked Vram usage at 14gb, while the TiledVae+ClearVram Version peaked at 7gb. Smaller GGUF Models might reduce requirements further.
GGUF Model, VAE and Textencoder can be downloaded here:
(Model&VAE): https://huggingface.co/calcuis/ltxv-gguf/tree/main
(anti Checkerboard Vae): https://huggingface.co/spacepxl/ltx-video-0.9-vae-finetune/tree/main
(Clip Textencoder): https://huggingface.co/city96/t5-v1_1-xxl-encoder-gguf/tree/main
You can go for the GGUF Version with 16gb+ and the TiledVae+ClearVram with less than 16gb Vram.
Masked Motion Blur Version: Since LTX is prone to motion blur, added an extra group to the workflow which allows to set a mask on input image, apply motion blur to mask, to trigger specific motion. (sounds better than it actually works, useful tho in some cases). GGUF and GGUF+TiledVAE+ClearVram version included.
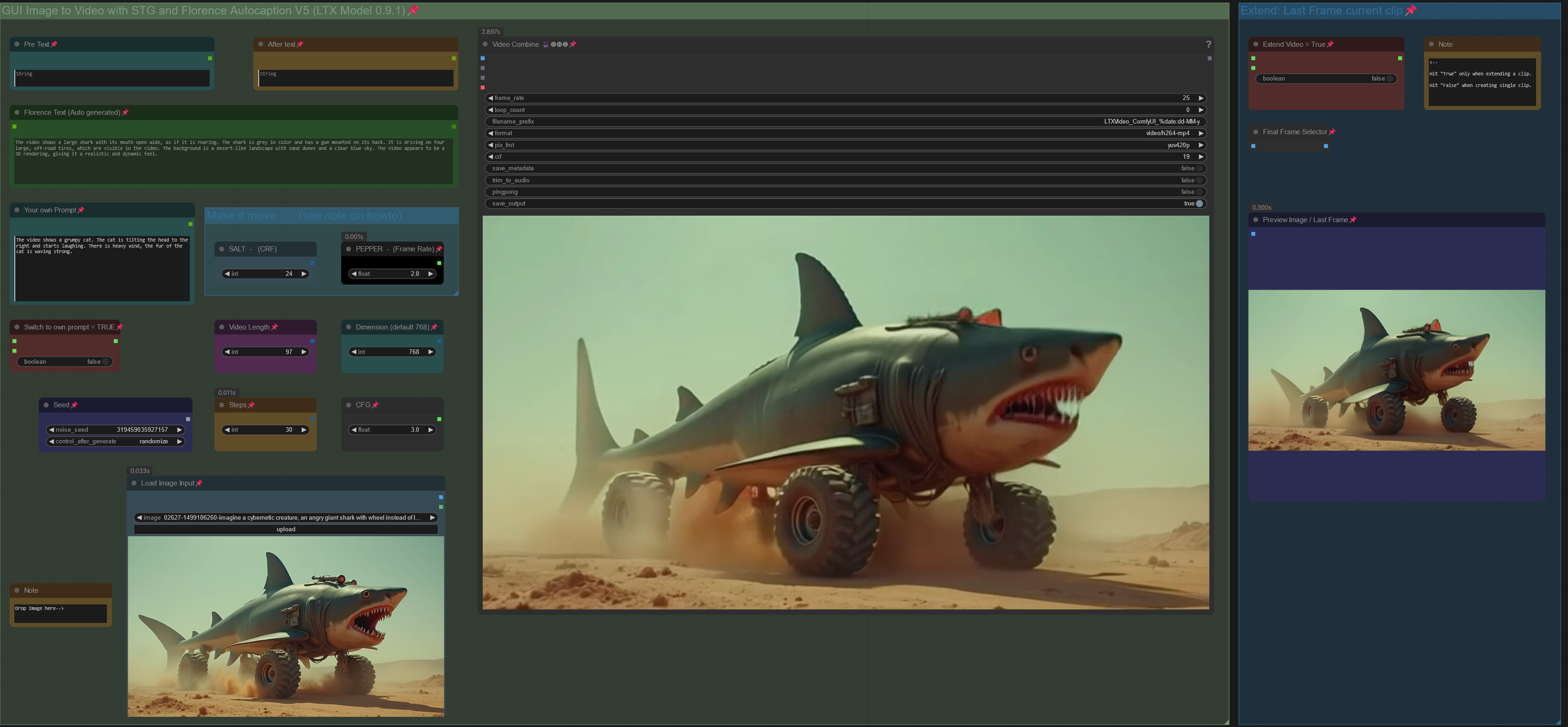
V5.0: Support for new LTX Model 0.9.1.
included an additional workflow for LowVram (Clears Vram before VAE)
added a workflow to compare LTX Model 0.9.1 vs LTX Model 0.9
(V4 did not work with 0.9.1 when the model was released (hence v5 was created), this has changed as comfy & nodes were updated in the meantime, now you can use both Models (0.9 & 0.9.1) with V4, also with V5. Both have different custom nodes to manage the model, other than that, both versions are the same. If you run into memory issues/long process time, see tips at the end)
-Outdated (march 2025)- V4.0: Introducing Video/Clip extension :
Extend a clip based on last frame from previous clip. You can extend a clip about 2-3 times before quality starts to degenerate, see more details in the notes of the worflow.
Added a feature to use your own prompt and bypass florence caption.
V3.0: Introducing STG (Spatiotemporal Skip Guidance for Enhanced Video Diffusion Sampling).
Included a SIMPLE and an ENHANCED workflow. Enhanced Version has additional features to upscale the Input Image, that can help in some cases. Recommend to use the SIMPLE Version.
replaced the height/width Node with a "Dimension" node that drives the Videosize (default = 768. increase to 1024 will improve resolution, but might reduce motion, also uses more VRAM and time). Unlike previous Versions, Image will not be cropped.
Included new node "LTX Apply Perturbed Attention" representing the STG settings (for more details on values/limits see the note within the workflow) .
Enhanced Version has an additional switch to upscale Input Image (true) or not (false). Plus a scale value (use 1 or 2) to define the size of the image before being injected, which can work a bit like supersampling. As said, not required in most cases.
Pro Tip: Beside using the CRF value at around 24 to drive movement, increase the frame rate in the yellow Video Combine node from 1 to 4+ to trigger further motion when outcome is too static.
Node "Modify LTX Model" will change the model within a session, if you switch to another worklfow, make sure to hit "Free model and node cache" in comfyui to avoid interferences. If you bypass this node (strg-B) , you can do Text2Video.
V2.0 ComfyUI Workflow for Image-to-Video with Florence2 Autocaption (v2.0)
This updated workflow integrates Florence2 for autocaptioning, replacing BLIP from version 1.0, and includes improved controls for tailoring prompts towards video-specific outputs.
New Features in v2.0
Florence2 Node Integration
Caption Customization
A new text node allows replacing terms like "photo" or "image" in captions with "video" to align prompts more closely with video generation.
V1.0: Enhanced Motion with Compression
To mitigate "no-motion" artifacts in the LTX Video model:
Pass input images through FFmpeg using H.264 compression with a CRF of 20–30.
This step introduces subtle artifacts, helping the model latch onto the input as video-like content.
CRF values can be adjusted in the yellow "Video Combine" node (lower-left GUI).
Higher values (25–30) increase motion effects; lower values (~20) retain more visual fidelity.
Autocaption Enhancement
Text nodes for Pre-Text and After-Text allow manual additions to captions.
Use these to describe desired effects, such as camera movements.
Adjustable Input Settings
Width/Height & Scale: Define image resolution for the sampler (e.g., 768×512). A scale factor of 2 enables supersampling for higher-quality outputs. Use a scale value of 1 or 2. (changed to dimension node in V3)
Pro Tips
Motion Optimization: If outputs feel static, incrementally increase the CRF & frame rate value or adjust Pre-/After-Text nodes to emphasize motion-related prompts.
Fine-Tuning Captions: Experiment with Florence2’s caption detail levels for nuanced video prompts.
If you run into memory issues (OOM or extreme process time) try the following:
use the LowVram version of V5
use a GGUF Version
press "free model and node cache" in comfyui
set starting arguments for comfyui to --lowvram --disable-smart-memory
see the file in your comfyui folder: "run_nvidia_gpu.bat" edit the line: python.exe -s ComfyUI\main.py --lowvram --disable-smart-memory
switch off hardware acceleration in your browser
Credits go to Lightricks for their incredible model and nodes:
Description
Support for LTX Model 0.9.1
additional Low VRam workflow included
Compare workflow included to compare LTX model 0.9 vs 0.9.1
FAQ
Comments (107)
Your workflow is much better than the official one! The official workflow often exhibits very large dynamic transitions, which can cause significant distortions in the characters.Thank you so much!Additionally, I think using the V4 workflow combined with the 0.9.1 model seems to produce better results than V5. You might want to give it a try.Could you further optimize the V4 workflow to better adapt to the 0.9.1 model?Additionally, I think generating videos from images is the most interesting aspect of AI videos.
Thank you. V4 did not work with 0.9.1 when the model was released, this seems to have changed as comfy & nodes were updated in the meantime, so you can use both Models (0.9 & 0.9.1) with V4, also with V5. Both have a slightly different pipeline.
one of the best workflows i ever used! 10* for you!!!!
awesome work with with version 5 and the GPU free node ! nice
I made a song with some scraps I generated with 0.9. (some clips are from kling and minimax) https://youtu.be/bxLkRmKoB1g?si=fWrcGi3oJlKRe908
funny :)
There is a finetuned VAE released by user spacepxl, to reduce checkerboard artifacts. You can add a "Load VAE" node and use it instead of the vae output from Checkpoint loader node.
did some testing, the fine tuned VAE definately reduces checkerbox artifacts, which also helps when extending clips based on last frame, appears you can run some more generations before it degenerates, on the other hand It seems also to reduces a bit of contrast and increases brightness slightly, which makes each extended clip go brighter than the one before. (Tested Model 0.9 with V4)
@tremolo28 brother the gens were doing fine suddenly i cnanot generate it takes an hour and more and the time keeps increrasing ? whats the bug?
@loneillustrator you might have run into shared memory, you can try the lowvram V5 Version or hit „clear model and node cache“ in comfy.
@tremolo28 i got stuck on the low vae workflow as well, how to solve? after 4 5 gemns
@loneillustrator try using V4 workflow, it uses other custom nodes, that seem more memory efficient than the ones from V5. You can use both models (0.9 & 0.9.1) with V4 or V5.
@tremolo28 thanks, what of v6?
ComfyUI-LTXTrick added support for Enhance-A-Video (which seems to be better than STG), can you add it to the workflow? im not sure how to do it myself 😅
Can you point me there, I dont see any update. The last entry I see is a bug fix from dec.22nd and the release of model 0.9.1 from dec. 19th, which is integrated in V5 already.
that sounds interesting! can't wait :)
@tremolo28 ofc, if u go to https://github.com/logtd/ComfyUI-LTXTricks, u'll see "add Enhance-A-Video" at the "commits" area.
You can also see the update at https://github.com/NUS-HPC-AI-Lab/Enhance-A-Video, if you look at the updates area, it says "2024-12-22: Our work achieves improvements on LTX-Video and has been added to ComfyUI-LTX. Many thanks to kijai 👏!"
@Mikusha got it. Enhance-A-video has been integrated into the "LTXTricks" custom nodes, that have been released to run model 0.9, as used in V4 of the workflow.
With newer model 0.9.1 , "LTXVideo" custom nodes have been introduced, i assume Enhance-A-video has been added there as well. V5 is based on that.
When both custom node sets "LTXTricks" and "LTXVideo" are up-to-date, the feature supposed to be there, I can see the reference to Ehance-A-Video in the LTXTricks nodes, with LTXVideo nodes tho, I am not that sure.
@tremolo28 but can you like, add the node to one of ur workflows? thing is that i don't know where it's supposed to be connected. 😅
@Mikusha as i see it, there are no new nodes, it has been updated within existing LTXTricks nodes, that are used in the V4 workflow, can see a reference in the code. Most likely the LTXVideo nodes from V5 have been updated as well with Enhance-a-video.
Bro have you getting this to work: https://www.reddit.com/r/StableDiffusion/comments/1h79ks2/fast_ltx_video_on_rtx_4060_and_other_ada_gpus/
it could be game changer, but I struggle to run it
Seems not yet to be ready for comfyui yet. Will keep an eye on that.
Try using the LTX video VAE, which has been fine-tuned to reduce checkerboard artifacts in the final video. Many people praise it in the comments for its quality. You can find the model and details here: https://huggingface.co/spacepxl/ltx-video-0.9-vae-finetune.
did not work with newer model did you use .9.1 ?
Thx a for the V5 Workflow :)
LTX 0.9.1:
The first video creation took like 30 seconds as it did in all other workflows before.
Whenever i click queue again the next video generation takes like 20 minutes now.
I am on a RTX 3080 and your previous workflows did not have this behavior.
My LTX V0.9.1 Model experiences:
The quality of LTX dropped so much in V0.9.1 in my opinion compared to LTX V 0.9 regarding character face and hair details.
Everything i do create ( same sources like i used in V0.9 ) now looks like someone added a smoothing filter which affects the entire quality of the AI processing.
If one checks
https://huggingface.co/spacepxl/ltx-video-0.9-vae-finetune
right side Obama v0.9.1 sample, i am sure one notices the loss of picture details in LTX v0.9.1 regarding this smoothing filter like look.
LTX v.0.9.1 Hair AI:
In LTX V0.9 Hair looks simply amazing.
It looks identical to the source picture input and if animated, it looks 100% real and beauty in motion.
In LTX V0.9.1 it is now just a mess with no details anymore.
In LTX V0.9 you see every strands of hair of a person in the animated video. The AI uses the 1:1 source details in the outputs. In LTX v0.9.1 it looks like the AI skips 80% of these details now.
If one imagines LTX V0.9 understands 99 % to animate motion to the majority of each single hair of a person in it's dimensions for example in a windy scene, the LTX v0.9.1 model only understands 20% of this logic now.
I am not a big fan of 0.9.1 either. Uses more memory, result quality varies. The process time with 0.9.1/V5 can increase like crazy , when you run into shared memory, it uses then RAM in addition to VRAM and slows everything down by a lot. If the low Vram workflow (v5) does not work fo you either, I would stick to V4, it uses other custom nodes and seems more efficient. I have a 4080 and use V4 with 0.9 model most of the time.
@tremolo28
Thx for sharing your opinion with v0.9.1.
I tried the Low VRAM workflow now and it is behaving much better.
There is no info though in that i run into low memory.
But it must be this then.
I noticed with V5 everything LTX0.9.1 looks like fast forward in motion.
Like speedup.
This is in the normal and low VRAM workflow.
I used the default settings.
Do you have any idea what i have to change here to receive a normal speed motion with v0.9.1 ?
If i switch to 0.9 this is normal again ;)
Even if i might work with LTX V0.9 until there is a new release again which hopefully is better as v0.9.1 i wonder what this is.
I do use all your workflows, i also like the first ones :)
I do not use massive scene descriptions prompting in LTX image2video for characters,
just simple motion / emotion / expression prompts
and body behaviors to receive a living character or simple prompts to introduce motion in background like animated fog (if there is fog). Even smile weights prompts do work nice.
Actually i do not see any logic in "as it is recommended" detailed prompting all and everything of the scene surrounding or clothing style if i just want to animate a scene. In my experience it is enough to describe what should be animated in my imagination.
At least if my main focus is to animate a character in such a limited scene shot time sequence,
and this works great.
I do have a wish since i like your examples much.
Perhaps you could also offer the prompts / motion prompts you used in your examples every now and then so one can learn from these.
No one adds their prompts as i noticed.
@LVNDSCAPE Added some tips to the description on memory issues/long processing time, maybe those help.
Regarding prompting, I just use the florence prompting most of the time. If I want to force like a camera zoom, I add" A camera zoom" to pretext and something like "The camera zooms into the face" at aftertext.
I will try to add meta data to some of my video examples in the future, so you can drag and drop the clip in comfy and see the workflow with all parameters, here examples:
Have you thought about adding some kind of batch creation? This model is so quick it'd be great to be able to generate a batch of like 6 vids and then just pick the best one
If you want to create like 6 vids in a row, you can queue them with comfy.
@tremolo28 You have a very good point 🙃
is there any way to set dtype to fp16? My 2060 super does not support bf16:(
I am not very familiar with that topic, but in V5 the checkpoint loader node can load a model as bf16 and fp32. Never tried it tho, not sure if the model supports it.
gguf version is available for 0.9.1 from calcuis on huggingface please make this workflow compatible for gguf version
added a GGUF Version to Experimental workflow based on V4.
Grab a GGUF Model plus the VAE (ltx-video-vae.safetensor) from:
https://huggingface.co/calcuis/ltxv-gguf/tree/main
Experimental workflow: https://civitai.com/models/995093?modelVersionId=1155974
@tremolo28 dude never thought someone like you who creates workflow and author will reply that fast, Thank you so much and yes I'm trying now this, but still wondering what will be the difference for me in between v4 experimental you gave me now vs the v5.0 (0.9.1)
@tremolo28 thanks for the workflow. I have also added myself the clear vram node, now it is working perfect ;-)
@yikifooler those versions are the same, function wise. They just use different custom nodes for the LTX model. The nodes from V4 do work with GGUF, the ones from V5 not yet. Both can manage LTX model 0.9 and 0.9.1
@tremolo28 got it and it works great the results are great but something is wrong I guess, It incrementing the total generation time by double every time I run It, same image started with 2 minute and now it is 15 minutes for the same image
@GK_Artist not working for me I guess
@yikifooler You probably ran into shared memory, slowing down everything. Have Put some tips on that in the description. You can also try to use a smaller gguf model.
I assume the LTXVideo repository nodes are still needed and not just the tricks? (was hoping it was all built in now). For some reason both in manager and via git installing the nodes gets stuck, I think it gets stuck trying to install the The main LTXVideo repository (appears it needs that to run the nodes for comfyui I think)
Tried manually, cannot seem to add docs folder... keeps stalling. Tried git restore --source=HEAD . hoping there is some answer on github or a way around these nodes with alt?
I found this on reddit:
"I had the same issue. For others having the same problem, what ended up working was going to https://github.com/Lightricks/ComfyUI-LTXVideo, downloading the zip file of the Code and extracting it here: ComfyUI\custom_nodes\ComfyUI-LTXVideo
This is probably not the best method, but it worked. Please post if you have a better method."
Source: https://www.reddit.com/r/comfyui/comments/1hjd3gk/ltx_video_image_to_video_091_stg_enhance/
@aohn92 Thanks I tried once to do this but let me give it another go, seems to get hung up on something with the docs folder. I saw a suggestion it could be a pip update or a different version of python. Seems odd to not even complete cloning it never even gets to the install. Hopefully the reddit post method can work I had fun with the basic tools be nice to try this WF for sure! :)
@aohn92 This one from enfafi worked from that thread - https://www.reddit.com/r/comfyui/comments/1hjd3gk/comment/m43aqjz/?utm_source=share&utm_medium=web3x&utm_name=web3xcss&utm_term=1&utm_content=share_button
Thanks I had read it before even had the wf I tried teh manual, the pip etc but the install zip command made all the libraries get added skipping the main repository stalling out.
Firstly congratulations, a great workflow!!! I would like to ask you if you could help me with how I can perform upscaling on the generated videos.??? Is there something simple I can use???
Guess there are workflows dealing with upscaling of videos. I am using topaz video AI, as easy to use
Thanks for v5 works well on 10gb vram, was a pain adding the LTXV nodes.
Hi! Thank you for your awesome workflow!
Btw, in v4, Node 188 EmptyLTXVLatentVideo, when I increased the batch_size to 2 or more, it doesn't do anything after the first video generated (and the queue continues running for some reason). Is it supposed to generate a batch of videos from the same input image?
It will generate n videos and stitch them together
Unfortunately I keep getting OOM errors on 8gb using the low VRAM workflow. Tried lowering resolution to 512, ltx v0.9.1 and 0.9.0, reduced the number of frames to 73 and even tried fp16 and fp8 clip just in case, but I wasn't able to make it work.
It errors out either during the sampler step (768 resolution) or more likely during VAE decode , and the Clean VRAM Used node is connected before the decode step.
Edit: Just noticed the tips, I haven't tried setting the start commands, will report if that works.
Update: It didn't work, OOM memory error during VAE decode using the lowvram and disable smart memory flags. The experimental workflow for the GGUF model works though.
"OOM memory error during VAE decode"
I confirm. Same on RTX 3090 with some biggish generations. This workflow is not using "tiled" VAE decoder. I guess it is not compatible.
I was thinking about adding that "Clean VRAM used" node, because it can indeed help.
My "load clip" node doesn't have the "ltxv" option. I have updated Comfyui and reinstalled all the relevant nodes and still nothing.
I checked and it seem the node can't be loaded
(IMPORT FAILED) ComfyUI-LTXTricks
Unable to install LTXV nodes via Manager.
Could we please have the Tiled VAE Decoder maybe? The generic one is pushing VRAM to the limit sometimes.
No more errors, it just crashes around 65% and disconnects me from Comfy. Using normal and low VRAM on a 4070 Ti 12 GB.
Experimental Tab includes now a workflow for GGUF models and a workflow with the OLLama caption setup.
GGUF Models and Vae: https://huggingface.co/calcuis/ltxv-gguf/tree/main
OLLama Server: https://ollama.com/
I use your workflow for all my recent video's and experiments.
See: https://www.youtube.com/watch?v=bgxij00qm3U
What a lovely video, l really like the style and touching plot. Great work👍
@tremolo28 thank you. and thank you for the great workflow. im now going to test the ollama version
can you maybe create a GGUF LOW VRAM OLLAMA Version?
@GK_Artist workflow in Experimental tab has been updated with GGUF LOW VRAM OLLAMA tiled VAE Version.
@tremolo28 thank you! will going to test it now! COOL!
Why V4 output is so blurry and artifacted compared v5? same everything ,i need Tiled VAE😣
tiled VAE Version has been included in Experimental workflow tab (GGUF, TiledVAE and ClearVram before VAE)
Can you maybe create a GGUF LOW VRAM TILED VAE OLLAMA Version? ;-)
it is in the Experimental tab workflow now. There are 3 additional versions:
1. Ollama and GGUF
2. Ollama and GGUF with tiled VAE
3.Ollama and GGUF with tiled VAE and a node to clear Vram before VAE.
@tremolo28 thank you, i will let you know the results ;-)
@tremolo28 i have tested the workflow and it is working perfect! https://civitai.com/images/49549452
Thank you for your fast feedback on my request ;-)
Going to test the several boolean settings, how it reacts. And finetune the Ollama settings a little more, e.g. put more details about camera movement.
@GK_Artist may I ask which OLLAMA Version did work for you and how much Vram do you have? Not sure if the Clear Vram version is really required.
@tremolo28 i use the version as provided in your workflow Ilama3.2:latest. And because i have a RTX 3080 10GB i need the Clear VRAM node.
@GK_Artist thanks. was testing with OLLAMA and it is very unpredictable, with chaotic results. Dont think it adds a lot of value. When using Florence as Input for LLama, it is even worse, even when lowering Florence detail settings. Best result I get, is when injecting a simple own prompt into LLama. Did you run some tests as well and can share your thoughts?
@tremolo28 i have tested it more and sometimes it gives good results, but sometimes when the camera motion is to much mentioned in the prompt then the results are bad idd. So i runned florence and also ollama to see the differences, but i think idd Florence without ollama is still the best. Or ollama's prompt template should be better described for LTX. Want to see if that improves the quality too. But for now i think Florence2 only is better and by using the Pre- and After text i can also guide the camera.
Where do I get the LTXVApplySTG and STGGuider nodes? My comfyui manager in SwarmUI found the other nodes being used, but not those ones.
Edit, seems the GGUF workflow doesnt have that issue
Oddly had to search for it in the node manager: ComfyUI-LTXVideo
added another Version to Experimental Tab to apply a mask with motion blur to input Image to trigger motion on masked objects. LTXV is trigger happy to motion blur in Input Image, the workflow allows to apply blur to masked objects. It is yet very experimental. See notes in workflow.
this is great, i can adjust the motion more, was trying in the old workflow to create a video of an image, but everytime the persons in the middle were walking not in straight line, now with setting the Y value higher then the x-value i can steer them in a straight line! thanks @tremolo28
@GK_Artist the MaskMotionBlur workflow has been updated (Jan06,25) with another node for real motion blur, works much better, motion direction and strength can be adjusted in a better way.
@tremolo28 thanks, going to test this too
@tremolo28 see result: https://civitai.com/posts/11254854
can now give extra motion of a subject in an image. Cool!
@tremolo28 are you going to make a GGUF TILED VAE CLEARVRAM MASKED Florence2 Flow too? ;-)
@GK_Artist Experimental workflow for MaskMotionBlur has been updated with a GGUF-TiledVAE-ClearVram Version
@tremolo28 yes! already testing, first impression really good!
will put some showcases soon on civitai
@GK_Artist noticed some jittering in every x frame with the tiled_VAE Version. It seems to be prevented by setting the "temporal_overlap" from 8 to 16 (also tested 24 & 32) in the "Vae Decoder (Tiled)" node. Not sure if this introduces other "effects". When replacing that node with the normal VAE Decoder, there is no issue.
@tremolo28 thanks will take into account. See my new short video using the mask motion. It is almost online.
Problems I am experiencing with the default gguf i2v workflow.
1. images not generating any motion (even when I use a manual prompt) and seems to be dependent mainly on seed.
2. Images with motion start off motionless for a long period before they move.
2. Generation times on the same image and prompt vary greatly for each seed. Some are fast while others sit there for ages.
4. Locked up Windows (may be just a random thing though).
Any suggestions?
regarding Motion, recommend to adjust the Motion Parameters in the GUI (Salt & Pepper) The speed issue you are facing might relate to you run into shared memory, slowing down the process time a lot. You could try a smaller GGUF Model or replace the "VAE Decode" node with "VAE Decode (tiled)" node. This works only with V4 or with the GGUF Version, that is based on V4 workflow.
I am highly interested in your work. However, I am a beginner and have only managed to load your workflow. After that, some nodes, including the LTX node, failed to load, and even attempting to install them through the manager did not resolve the issue. I believe a guide or fix for your workflow is necessary
another user had same issue, he confirmed to git clone the LTX nodes directly from github:
LTXVideo nodes as used in V5:
https://github.com/Lightricks/ComfyUI-LTXVideo
LTXTricks nodes as used in V4:
https://github.com/logtd/ComfyUI-LTXTricks
I can support with the workflow I created, but not realy with Comfyui or custom nodes issues.
if this doesnt help, update git to the newest version. git 2.45.1 has a breaking change regarding not being able to pull data from git LFS, this results in files not being pulled and then you get stuck. ive tried to fix it both via UI and shell - it all came down to my git being outdated.
Try using ComfyUI through Stability Matrix, it makes everything easier!
Created a small video using the Mask Editor to have more control over the motion.
love it, it seems also reacting to the beat. Great Job.
Created an Animal Fusion Video of a Wolf and an Eagle using this workflow!
https://www.youtube.com/watch?v=8N74Q6es5lo
Thanx for GGUF version. Not sure why not change CLIP loader to GUFF version? I try it and its work flowless with 1/2 VRAM for CLIP - t5-v1_1-xxl-encoder-Q5_K_M.gguf
any idea how to fix path error on VHS_LoadVideoPath node?
im using: ltx-video-2b-v.9.1, t5xxl-fp8-e4m3fn, dpmpp_2s_ancestral, 25 frame rate, 24 salt, 4 pepper, 176 steps, cfg 3, dimension set to 768. input image is 1216x832. my generation time is around 6 minutes on a windows 11 with a 7950X3D, 64GB ram and a 16GB 4080 Super. i also have high artifacts and usually very little movement. where am I going wrong here? does this sound "normal"?
Did you try euler as sampler? 176 steps seems to much, should work in the range of 20-40
@tremolo28 i am an idiot. i think i misclicked steps for video length at some point- hence the high step count. using euler with 176 steps cut it down to 3:40 and vram to 60%. now with 40 steps its at a breezy 50 seconds (1.3s/it). one thing that ive still got to counter is the random text spawning, even though my negative has : "distorted, watermarks. text, logo, credits, title, title card, subtitles, introduction, name card" included to counter that. its possible the 2D western cartoon style of the image is causing this.