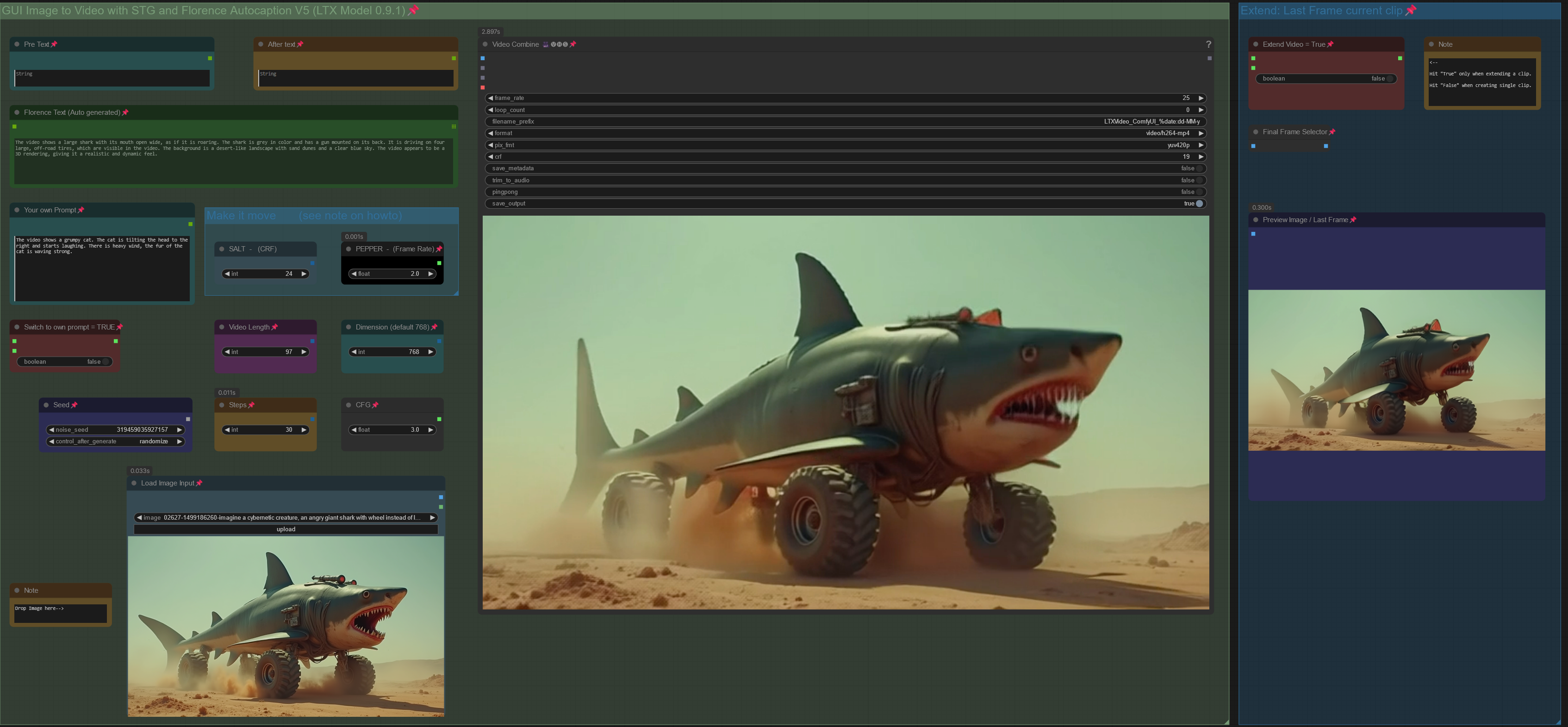
NEW LTX-2 Workflows here: https://civarchive.com/models/2318870
Workflow: Image -> Autocaption (Prompt) -> LTX Image to Video
LTX Prompt Enhancer (LTXPE) might have issues with latest Comfy and Lightricks update
Update July 20th 2025: GGUF Models for LTX 0.9.8:
Distilled model, works with V9.5: https://huggingface.co/QuantStack/LTXV-13B-0.9.8-distilled-GGUF/tree/main
Dev model, works with V9.0: https://huggingface.co/QuantStack/LTXV-13B-0.9.8-dev-GGUF/tree/main
(see "Model Card" in above links for LTX 0.9.8 VAE and textencoder downloads)
V9.5: LTX 0.9.7 Distilled Workflow supporting LTX 0.9.7 Distilled GGUF Model.
There is a workflow with Florence and another one with LTX Prompt Enhancer (LTXPE)
GGUF Model can be downloaded here:
https://huggingface.co/wsbagnsv1/ltxv-13b-0.9.7-distilled-GGUF/tree/main
VAE and Textencoder are identical to previous LTX 0.9.6 model (see V8.0 below)
LTX 0.9.7 Distilled is using only 8 steps and is very fast.
V9.0: LTX 0.9.7 Workflow supporting LTX 0.9.7 GGUF Model.
There is a workflow with Florence and another one with LTX Prompt Enhancer (LTXPE)
GGUF Model can be downloaded here:
https://huggingface.co/wsbagnsv1/ltxv-13b-0.9.7-dev-GGUF/tree/main
VAE and Textencoder are identical to previous LTX 0.9.6 model (see V8.0 below)
LTX 0.9.7 is a 13billion parameter model, previous versions only had 2b parameters, therefore it is more heavy on Vram usage and requires longer process time. Try V8.0 below with model 0.9.6 or V9.5 for very fast rendering.
V8.0: LTX 0.9.6 Workflow (dev and distilled GGUF model in same workflow)
there is a version with Florence2 Caption and a version with LTX Prompt Enhancer (LTXPE)
GGUF Models (Dev & Distilled) can be downloaded here:
https://huggingface.co/calcuis/ltxv0.9.6-gguf/tree/main
vae: pig_video_enhanced_vae_fp32-f16.gguf
Textencoder: t5xxl_fp32-q4_0.gguf
V7.0: LTX 0.9.5 Model Version GGUF with Wavespeed/Teacache.
LTX 0.9.5 GGUF Model and VAE: https://huggingface.co/calcuis/ltxv-gguf/tree/main
(vae_ltxv0.9.5_fp8_e4m3fn.safetensors)
Clip Textencoder: https://huggingface.co/city96/t5-v1_1-xxl-encoder-gguf/tree/main
There are 2 worklfows, a main workflow with florence caption only and additional one with florence and LTX prompt enhancer. Setup with Wavespeed (bypassed by default, Strg+B to activate)
workflow works with all GGUF models: 0.9 / 0.9.1 / 0.9.5
uncensored LLM for Prompt enhancer: https://huggingface.co/skshmjn/unsloth_llama-3.2-3B-instruct-uncenssored
-Outdated (march 2025)- V6.0: GGUF/TiledVAE Version & Masked Motion Blur Version
Updated the workflow with GGUF Models, which save Vram and run faster.
There is a Standard Version, which uses just the GGUF Models and a GGUF+TiledVae+Clear Vram Version, that reduces Vram requirements even further. Tested the larger GGUF model (Q8) with resolution of 1024, 161 frames and 32 steps , the GGUF Version peaked Vram usage at 14gb, while the TiledVae+ClearVram Version peaked at 7gb. Smaller GGUF Models might reduce requirements further.
GGUF Model, VAE and Textencoder can be downloaded here:
(Model&VAE): https://huggingface.co/calcuis/ltxv-gguf/tree/main
(anti Checkerboard Vae): https://huggingface.co/spacepxl/ltx-video-0.9-vae-finetune/tree/main
(Clip Textencoder): https://huggingface.co/city96/t5-v1_1-xxl-encoder-gguf/tree/main
You can go for the GGUF Version with 16gb+ and the TiledVae+ClearVram with less than 16gb Vram.
Masked Motion Blur Version: Since LTX is prone to motion blur, added an extra group to the workflow which allows to set a mask on input image, apply motion blur to mask, to trigger specific motion. (sounds better than it actually works, useful tho in some cases). GGUF and GGUF+TiledVAE+ClearVram version included.
V5.0: Support for new LTX Model 0.9.1.
included an additional workflow for LowVram (Clears Vram before VAE)
added a workflow to compare LTX Model 0.9.1 vs LTX Model 0.9
(V4 did not work with 0.9.1 when the model was released (hence v5 was created), this has changed as comfy & nodes were updated in the meantime, now you can use both Models (0.9 & 0.9.1) with V4, also with V5. Both have different custom nodes to manage the model, other than that, both versions are the same. If you run into memory issues/long process time, see tips at the end)
-Outdated (march 2025)- V4.0: Introducing Video/Clip extension :
Extend a clip based on last frame from previous clip. You can extend a clip about 2-3 times before quality starts to degenerate, see more details in the notes of the worflow.
Added a feature to use your own prompt and bypass florence caption.
V3.0: Introducing STG (Spatiotemporal Skip Guidance for Enhanced Video Diffusion Sampling).
Included a SIMPLE and an ENHANCED workflow. Enhanced Version has additional features to upscale the Input Image, that can help in some cases. Recommend to use the SIMPLE Version.
replaced the height/width Node with a "Dimension" node that drives the Videosize (default = 768. increase to 1024 will improve resolution, but might reduce motion, also uses more VRAM and time). Unlike previous Versions, Image will not be cropped.
Included new node "LTX Apply Perturbed Attention" representing the STG settings (for more details on values/limits see the note within the workflow) .
Enhanced Version has an additional switch to upscale Input Image (true) or not (false). Plus a scale value (use 1 or 2) to define the size of the image before being injected, which can work a bit like supersampling. As said, not required in most cases.
Pro Tip: Beside using the CRF value at around 24 to drive movement, increase the frame rate in the yellow Video Combine node from 1 to 4+ to trigger further motion when outcome is too static.
Node "Modify LTX Model" will change the model within a session, if you switch to another worklfow, make sure to hit "Free model and node cache" in comfyui to avoid interferences. If you bypass this node (strg-B) , you can do Text2Video.
V2.0 ComfyUI Workflow for Image-to-Video with Florence2 Autocaption (v2.0)
This updated workflow integrates Florence2 for autocaptioning, replacing BLIP from version 1.0, and includes improved controls for tailoring prompts towards video-specific outputs.
New Features in v2.0
Florence2 Node Integration
Caption Customization
A new text node allows replacing terms like "photo" or "image" in captions with "video" to align prompts more closely with video generation.
V1.0: Enhanced Motion with Compression
To mitigate "no-motion" artifacts in the LTX Video model:
Pass input images through FFmpeg using H.264 compression with a CRF of 20–30.
This step introduces subtle artifacts, helping the model latch onto the input as video-like content.
CRF values can be adjusted in the yellow "Video Combine" node (lower-left GUI).
Higher values (25–30) increase motion effects; lower values (~20) retain more visual fidelity.
Autocaption Enhancement
Text nodes for Pre-Text and After-Text allow manual additions to captions.
Use these to describe desired effects, such as camera movements.
Adjustable Input Settings
Width/Height & Scale: Define image resolution for the sampler (e.g., 768×512). A scale factor of 2 enables supersampling for higher-quality outputs. Use a scale value of 1 or 2. (changed to dimension node in V3)
Pro Tips
Motion Optimization: If outputs feel static, incrementally increase the CRF & frame rate value or adjust Pre-/After-Text nodes to emphasize motion-related prompts.
Fine-Tuning Captions: Experiment with Florence2’s caption detail levels for nuanced video prompts.
If you run into memory issues (OOM or extreme process time) try the following:
use the LowVram version of V5
use a GGUF Version
press "free model and node cache" in comfyui
set starting arguments for comfyui to --lowvram --disable-smart-memory
see the file in your comfyui folder: "run_nvidia_gpu.bat" edit the line: python.exe -s ComfyUI\main.py --lowvram --disable-smart-memory
switch off hardware acceleration in your browser
Credits go to Lightricks for their incredible model and nodes:
Description
GGUF Version (outdated since march 2025)
MaskMotionBlur Version
FAQ
Comments (157)
V6.0 here we come! ;-)
@tremolo28 GREAT!
Hi,
i have a request / question ;-)
There is also a text2Video workflow presented in: https://huggingface.co/calcuis/ltxv-gguf/blob/main/workflow-ltxv0.9.1-gguf.json
Can you update your workflow with this? maybe a boolean to select the Image2Video flow and the Text2Video flow? With the variants GGUF, ClearVram, VaeTiled, etc?
Hi, I have a workflow for T2V as well: https://civitai.com/models/1000563/ltx-image-to-text-to-video-with-stg-workflow
Plan to update it to GGUF over the weekend.
But, here is a Pro tip: Within V6 (I2V) workflow bypass (STRG+B) the "Modify LTX Model" in upper left corner and hit "Free Model and Node cache" in comfy, then you have T2V. :)
@tremolo28 oke, thanks, will try. BTW the workflow i mentioned is a real Text to Video (not with an image solution in between)
@tremolo28 yes the pro tip worked! thx
This is great! Thanks for sharing!
Any tips for getting cleaner footage? Or upscaling it?
I am using hires Input Images and set dimension (resolution) to 1024 for best results
Do someone could guide me on how to avoid static videos? i can't achieve dynamism or decente movement, mostly of cases i get eyes blink and freezed body
increase the motion parameters (Salt&Pepper) until there is sufficient motion. Usually values like Salt = 25, Pepper =4 should drive motion. If Input image has a high resolution (like 3-4k) or is of anime/cartoon style, increase Salt to around 28. Salt tends to apply motion to character/object, Pepper tends to drive motion in background (tendency, not a rule). Reduce values when motion is too fancy.
@tremolo28 Thank you so much
@tremolo28 I had the same problem thanks, now the video work well ❤️
Thank you for sharing, I am new to this, could you please suggest how could I change aspect ratio?
Aspect ratio of the clip is defined by the input image aspect ratio
Thank you for quick reply. It worked. Could you also please suggest what should I experiment with to make video similar to image, currently the video is very different from the input image, which settings should I tune?
@blopitup845 that is strange, the clip is supposed to follow the input image. You could post the png file with meta data to the experimental tab and I check (save meta data in the VHS combine node , click "save meta_data)
@tremolo28 Thank you for your help. I have posted the image with meta data from VHS. Its similar with other images too. Please let me know if I you need any more info. Caroon looking (2nd image) is the original and the other one (2nd) from generated video.
@blopitup845 processed your image throught the workflow from the metadata and it worked
https://civitai.com/posts/11508463
try hitting "Free Model and Node cache" in comfyui, maybe you had some interferences...
@tremolo28 Aww man! that looks so amazing and as natural as image, not sure what am I doing wrong here. One thing I did notice though that the auto prompt(Flourence) generated in my case does seems wrong, this is what it gives ("The video shows two green frogs standing on their hind legs on a concrete surface. The frogs are facing each other and appear to be holding a camera in their hands. The frog on the left is holding a small red flower in its mouth and is looking at the camera with a curious expression. The background is blurred, but it appears to be an outdoor setting with trees and greenery."). Did you gave any additional prompt in your case or any other change? I am running it on m1 mac 32gb and using v6 standard, I hope that should not be an issue. I am still facing same issue. Is there anything I could try making adjustments? Thank you again for all your efforts and help.
@blopitup845 The prompt seems not to be the issue, florence generates new prompts anyway per seed and is not always 100% accurate. My best guess, your issue is related to the Mac and the "modify LTX model" node. Try V5, it uses different nodes for the model, however it also uses most Vram.
@tremolo28 Unfortunately V5 crashed with an error which i believe is in mac pytorch. Seems I will need to wait for another model in this case or until the bug is fixed for mac. :( Thank you for all the help.
@tremolo28 Finally I was able to get V6 working, it was pytorch issue on mac, resolved it and everything works fine now. Thank you so much again for such an amazing work, its flawless!!
I bumped into the same issue as @blopitup845 with inconsistent videos on Mac. A PyTorch upgrade resolved it: https://github.com/Lightricks/ComfyUI-LTXVideo/issues/43#issuecomment-2529380548
Hey there! Any version that uses 24GB?
the model itself is below 8gb, the VAE Decoder can peak > 16gb depending on resolution, no. of frames, etc. V5 & V4 uses the original model and can go > 16gb of Vram usage. V6 uses GGUF models, which use less Vram, without impact on quality, provided the larger GGUF model is used (Q8 or f16/bf16)
Are there any good methods to detail a video? Once I get a generation I like, it would be nice to process it to detail. The closest thing I've found along these lines is this: https://www.youtube.com/watch?v=LDXFOwGvjwk
Did you try it? Did it work?
How do we "adjust Pre-/After-Text nodes to emphasize motion-related prompts"? Can you give some examples? I have been getting good results with adjusting Salt/Pepper but would like to see even more motion.
I use it for zooms, like the portrait examples below. I am using "A camera zoom" in pretext and "The Camera zooms in on face" as after text. This usually triggers a zoom. Did not experiment a lot with camera motion outside of zooming, but it feels like the model has a mind on its own when it comes to camera movement.
@tremolo28 Thanks! Will give it a try today.
Hey man, thats an amazing workflow. I found that when you free the vram after the clip step prior to the video, you can render 1024 video 5 sec at 5.7GB as we just got rid of CLIP which we dont need anymore. It may help to reduce runtime Vram even more =)
thanks, can you share the node name or number (#) you are refering to place the clear Vram node in between?
I put it between #6 and #69 so I put it between the output of the positive conditioning node and the input of LTXV conditioning. at that point the conditioning using CLIP is done and we dont need CLIP in memory anymore. And so running video generation at 1280 runs here at 9.2GB. at the time the conditioning is done it has already also loaded the LTX video model so at that time the vram consumption is much higher. it would be cool if we also can control at what time the LTX checkpoint is loaded this way we could use the vram in a sequence and end up using a very low footprint. but I did not yet find how to manage that
@osi1880vr thanks, I see. It sounds very useful with low vram and high resolution. May I ask what Workflow version did you use?
@tremolo28 I used this from your v6 Standard_GGUF_TiledVae_ClearVram. I was mostly curious as vram is not my issue, but I always like to see how much can be spared. But meanwhile I tryed the same trick with the v5 workflow where you are still using the full model and also there unloading clip after conditioning helps a lot to free memory. still it would be so cool to load the LTX checkpoint after clip was done :D
@tremolo28 yes, i checked it too, and it is really decreasing the vram!
i used it in the masked gguf clearvram etc version
did you use both Clear Vram nodes, the one before VAE plus the one after Text encoder?
@tremolo28 yes i keeped the original of your workflow, and also added a new one between the GREEN CLIP TEXT ENCODE (Positive Prompt) #6 and the POS LTXVCONDITIONING #69
@GK_Artist ok, thanks good to know
@tremolo28 with the 2 clear vram nodes in the workflow (because of my 10GB VRAM limit) (+GGUF + TiledVAE) i can now run 1280!
thank you both of you, will consider this in case I update the worklfow.
@GK_Artist Cool, that was my intention and you gave me proov I was right :D great, thank you =)
@osi1880vr Hi, have just added another Version (MultiGPU) to Experimental Tab, allowing to offload models to CPU (or multiple GPU). Tests with default setting peaked VRam below 6gb.
@GK_Artist Hi, have just added another Version (MultiGPU) to Experimental Tab, allowing to offload models to CPU (or multiple GPU). Tests with default setting peaked VRam below 6gb.
@tremolo28 Thanks for posting these! Hey, all of you, I am the owner of the MultiGPU custom_node, so if anyone has any questions about the new workflows, I'll be happy to answer them and/or link to some more resources. :) Cheers!
@tremolo28 thx! will going to try it.
@pollockjj766 thank you! will going to test it.
anyone try adding wave speed yet?
https://github.com/chengzeyi/Comfy-WaveSpeed
testing in a sdxl workflow .. it does speedup but few misfires too
tried to include Wavespeed and Teacache, but could only get it to work with T2V without STG. Generation speed is like half, but result is ugly without STG. Will keep an eye on it.
@tremolo28 thank you for the info, good to know
@mystifying just when I replied, I found a way to implement Teacache with I2V. See workflow in Experimental tab: https://civitai.com/models/995093?modelVersionId=1155974
@tremolo28 sweet gonna test that later today..ty
Added a Teacache Version to Experimental Tab.
It reduces process time about 40%, but not sure about quality impact. Still needs some testing.
https://github.com/welltop-cn/ComfyUI-TeaCache
Experimental tab: https://civitai.com/models/995093?modelVersionId=1155974
<3
updated the Teacache worklfow with more reasonable Parameters:
- changed sampler to Euler_ancestral + updated parameter of teacache and STG
(Jan 15th 2025)
@tremolo28 GJ!
In case you fiddle with the parameters in the workflow for the teacache version, make sure to hit the "Free model and node cache" in comfy afterwards. The teacache node is caching some data, that seems not to get proper "cleaned" when changing a parameter , resulting in odd video clips. With parameter I mean, anything in the model chain before it goes into the sampler. Might become obsolete when the Teacache node gets updated.
@tremolo28 this is a great tip, I was wondering how to flush the cache in Comfy
dont see really improving in speed, and get strange quality decreasing using teacache.. hope this will be improved.
@GK_Artist thanks for testing. I think the strange quality is not refering to teacache itself, but I had to use a different setup for STG to make it work with TC . The new setup seems not delivering same quality. The TC speedup only occurs on the sampler, not on the VAE. On my setup (Rtx4080) it has a 30-40% speed bump over the whole generation process. Will keep on working on it....
@tremolo28 I have to adjust my test results. After updating all to the latest versions, i notices the bigger the resolution the faster the sampler works with the teacache. Also testing now with the teacache settings values.
I have also used the 2 clear vram nodes in the workflow because of my 10GB VRAM limit. Becasue of the 2 Clear VRAM nodes (+GGUF + TiledVAE) i can now run 1280!
Going to test the best settings for the teacache too so get the best final result.
update: when using teachache i need to use a low pepper setting 0.5 and salt 30, on the 1280 resolution, to have a good video without too much motion. If i use higher Pepper settings, then the motion get wiped out and become big liquid flows in the video. But it depends on the image.. not always the case. Difficult to check before based on the image which settings to use.. Should nice if this can be automatically determined.
Can you make the new combi of all including the masks? so that we can maybe better control the movement?
conclusion 1: teacache is faster! (but to determine the correct setting upfront is difficult)
conclusion 2: the 2 clear vram nodes are a great improvement! in the flow.
Up to the next improvement ;-)
@GK_Artist thanks. I have a bit of a hard time with the teacache worklfow myself. Salt and Pepper seem to work differently (I avoid using Pepper there, as it creates to much odd animations). I was also juggling with the following parameters: "Image Noise scale" (values tested: 0.01-0.15) , "block_indices" (14,11,19, it blocks layers in the model to avoid odd motion, but the more layers you block, the static) and sampler (euler vs euler_ances.). I feel I have more control and better motion with the non Teacache workflow.
As said in another post, the issue seems not to be teacache itself., but the different setup I had to use to make it run with the LTX STG feature.
Yes, I might add Teacache to the Masked Motion Blur Version as well for testing.
@tremolo28 yes, idd. the Teacache is idd faster but difficult to get good consistence results. Let s hope on some improvements. For now i use again the masked gguf tiled vae v6, with the 2 clear vram nodes added. 1280 on 10gb.
I tried to download everything but the clip loader never worked. Please tell me what should be the folder of this clip name and what node should I download
Hi, here is some info about the file locations https://huggingface.co/city96/t5-v1_1-xxl-encoder-gguf/discussions/2
Hi,I have a question,is LTX really can`t make nsfw video? Thanks
i need help with setting. like CFG, CRF, STEPS and length. i keep getting ugly distorted video 😭
There are PNG files included in the download, if you drag&drop those into comfy, you can see the settings. There are also notes in the workflow with explanations.
Batch a whole Folder in the Workflow.
Is it possible to add a folder instead of only one Image in the Worklow ? this would be nice =)
So far the best Workflow here und runs fine on my i5 with 64Gbram and a 3060 12GB. 5-8 it/s
should work, if you replace the "Load Image Input" node with a Load Image batch node. Like "Load Images (Path)" from VHS custom nodes pack.
When I use the workflow its pretty good and quick. However I noticed in none of the V6 workflows is the CRF connected. When you unpin it, it has no connection. Is that right?
the CRF is connected, node #210 "Salt (CRF)" is connected with node #81"Video combine", therefore adding compression to input image. If I unpin it, connection is still there.
@tremolo28 Strange. I swear i just straight download from here, put it in and its not connected. What should i connect it with on the video combine?
@danque to yellow node #81 "video combine", it has an input for CRF
@tremolo28 It doesn't for some reason. I have to look into it. Thanks for answering.
What should be in node "Unet Loader (GGUF")? This is checkpoint? I put ltx-video-2b-v0.9.1 model in checkpoint folder, but it still "undefined"
yes, that node loads the GGUF model. Location is ../models/Unet
@tremolo28 It says "undefined" anyway
@_Jarvis_ did you download a .gguf or .safetensor file from the link? https://huggingface.co/calcuis/ltxv-gguf/tree/main
gguf is the right one for the unet loader node.
Is there workflow for upscale video and enhance the details ?.
i will upload it
For Cartoon/anime style generation how do I avoid massive distortion of the final output? it seems no matter what salt/pepper combos I try the result always winds up with properly animating it (motion always happens) but it distorts/contorts the picture by twisting around the hands/face etc into a mess. Unsure if this has to do with salt/pepper or do I have to adjust something else?
Reduce the values when motion gets too funky. Try Salt first up to 28-30. if movement is too low, increase Pepper. Pepper usually helps when there is water in the back, that does not move or rain , or hair that is too static, etc.
@tremolo28 Will try it out. Thanks
Thanks for your workflow! I've been looking for ages and couldn't find anyone sharing a method to speed up LTXV I2V with TeaCache. I'm super glad your workflow works and that it runs on Mac!
thank you, glad to hear it works as well on mac
I dont get the extend frame, i enable it to true and queue twice but doesnt seem to continue from last frame
when first clip is done, rightclick the last frame and select "open in new workflow", then last frame became first frame in new workflow. Or copy last frame to Input Image (see notes above extend group in the workflow)
@tremolo28 oh manual copy of image. but that image is generated even if boolean is false, i thought its going to be automatic
@ApexArtist1 the end frame is always created, the boolean switch only ensures the extended frame does not get further Salt/Pepper treatment as it would decrease quality faster with each extension, so it gets bypassed.
Does "Lightricks LTXV" is better than gguf version "ltx-video-2b-v0.9.1-r2-f32.gguf"s in this workflow description?
I dont see a quality difference between the original .safetensors models and the larger GGUF Models, like Q8,F32 or F16. If this is what you are asking.
@tremolo28 That's exactly what I mean, my english kinda sucks sometimes =P. Thank you mate, soon I collect some buzz I'll tip for this workflow!
why when i use "pre text" or "after text" then the video freezes?
VideoCombine.combine_video() got an unexpected keyword argument 'crf'
This is an awesome workflow. Thanks for your hard work.
I´m able to run it in my 4050RTX 6VRAM laptop + 16 RAM.
GPU is working 100% and RAM 80ish %
It takes around 200-300 seconds, with 20-27 steps, CFG 1-4
0.9.1_Q8 models.
0.9_Finetuned all Vae
t5 encoder
Salt 20-28, Pepper 1-3
I´m thinking on adding scaling, REVIFE and Faceswapping (for improvements)
I´m doing something wrong?
Teacache is making way slower the generations
0.06 Over 300secs (good quality)
0.4 Over 500 secs (medium quality)
0.8 Over 700 secs (garbage)
Has anybody find a solution for controlling better the movements?
I know Salt (object) and Pepper (surroundings)
Pre and after text, are not working very good for me.
Changing the size of the output is viable?
Thanks again for your awesome work!
what's your average time to complete a step? I feel like my 30s/it on RTX 2070 Super on the tiled/clear workflow is a sign of something going wrong.
I would also suggest on putting Florence section into another workflow, or adding a way to unload it before generation - it's sitting in vram thoughout whole generation process, occupying nearly 3GB that could be used for better quality models/resolution, despite the fact that its job is done in first seconds after querying.
huh, nevermind. I've tried the normal workflow with all files at Q8 and it worked out of the box, with 12s/it to boot. and yet, the "optimized" one would OOM with same files.
I loaded the simple workflow as is and installed all the mods. I queued the image and it produces a 1 second 1 frame video. What am I doing wrong?
Maybe related I'm also getting "Failed to validate prompt for output 79" in the console
With latest update of VideoHelperSuite, the VideoCombine Node for the video output node seems to resize everytime you load or switch to a workflow, which can be anoying, hope it gets a fix.
Recommend to unpin the node and resize it manually.
a fix will come: https://github.com/Kosinkadink/ComfyUI-VideoHelperSuite/issues/387
There is a silly workaround to prevent resizing/minimizing of the video combine node: Edit the node title and add text like "_____", fill the whole textfield until it fits from the size. It will then resize to that size based on the length of the title.
Loras are popping up for LTX, as someone released a trainer (check for LTXV + Lora at Civitai). Tried to incorporate 2 of them , but did not yet note any impact. If you want to try them, add a Load Lora node.
Edit: A LTXV setup with Lora requires special "Load Lora" and "Load Checkpoint" nodes, as descibed here: https://github.com/dorpxam/ComfyUI-LTXVideoLoRA?tab=readme-ov-file
it does not work with a GGUF checkpoint yet. Needs the good old 0.9.1 safetensore model.
Edit: Have added a workflow to Experimental Tab with GGUF support and a version with TiledVAe and ClearVram
I've updated the https://github.com/dorpxam/ComfyUI-LTXVideoLoRA nodes right now. No more 'Load Checkpoint', just a single 'Load LoRA' node which supports all scenarios, including GGUFs ;)
@dorpxam thank you for the update, works great now along with GGUF models. Will update my workflow on experimental tab. Great work.
Gives this error: Error no file named pytorch_model.bin, model.safetensors, tf_model.h5, model.ckpt.index or flax_model.msgpack found in directory C:\Users\User\Documents\ComfyUI\models\LLM\Florence-2-large.
seems like the caption model florence2 is missing, it is supposed to auto download on first run. Anyway, here is the download link for the model. Download all to the specified "...LLM/florence-2-large" folder:
This workflow is too good! Its so easy to use and I found a lot of nice ideas that I can include in my other workflows.
Thank you very much for sharing this!
Thanks a lot for the feedback and buzz 👊👍
which one you find is best ? i always find the quality really soso when characters move.
@tremolo28 👊 🤝👍 It was worth every buzz. I'm sharing this around with my friends.
I'm excited to see what you make next!
@aureh12387 I'm using the v6.0 workflow. I only changed 2 variables: I set SALT to 30 and Steps to 50.
I'm getting good results fairly often (I usually get 1 good result within 3 generations).
As a comparison, Kling is cleaner and more powerful (I usually get a good result every generation) but this LTX workflow seems to do a better job at a wider range of animations/motions. (And of course its local which makes it 100 times better than Kling lol)
If you need examples, I shared my workflows (its just this same LTX workflow but you can see all my settings) for all these animations https://civitai.com/collections/8059955
I appreciate the workflow; it works exceptionally well and is truly impressive. However, I wanted to ask if it is possible to reduce GPU temperatures, which currently range between 75°C and 80°C when "SamplerCustom" is in process. Is there any setting I can adjust to lower the temperatures? I don’t mind if the video generation takes 10 minutes longer; my main concern is keeping the GPU from running too hot .
GPU: rtx 3080 10gb
Undervolting with MSI Afterburner. Google for detailed instructions.
@tigerart Thank you so much for reminding me about undervolting! I had completely forgotten about it since I never used it for gaming—I only knew about it but never applied it. Unlike gaming, video rendering tends to push temperatures much higher. Now, thanks to undervolting, I can render a 10-second high-resolution video while keeping the GPU at 70°C, even in the middle of summer here in Argentina, despite the added challenge of ambient heat.
Finally a amazing one after hours and hours of jungle workflow and weird installation, i did it ! You have best one. I have only one small small question there is a sort of way to reduce noise and modification to keep orginal face ? (and also i feel it moving so much, i reduced a lot salt and peper, but it keep moving crazy. If i put "smile" in prompt it show me a crazy man who smiling hard haha
Thanks, LTX Video model has a bit of a mind on its own, output depends a lot on the Input image, Salt & Pepper, dimension and no. of steps. in your example I would try to increase no. of steps (>35) and dimension of 1024, this can tame the motion, beside reducing Salt & Pepper.
24salt 3.5pepper on a hi-res image is the only way to get the Bullet_Time LORA to activate, reguardless of Dimension node setting.
-
Without LORA: start at 20 SALT and 1 PEPPER, generate and increase the SALT until you hit 24 SALT- then increase PEPPER, until the animation gets too crazy... -if animation doesnt happen by the time you're at 24 SALT and 4 PEPPER... then you need to add "Pre Text" and "After text" prompts... but ive only had that happen like fkn once in over 100 generates- but still worth noting.
-
Overall, amazing workflow. Thanks. I dare say... the best one on this site currently for low vram setups.
(8gb of vram, ~1min generates)
I'm using it normally but today when I update comfyui I get an error: 'SymmetricPatchifier' object has no attribute 'get_grid' help me
same here. V5 still works (non GGUF). Will investigate.
update: V4 does not work as well. V4 and V6 use the LTXTricks node, while V5 uses LTXVideo nodes. I asume the issue is with the LTXTricks, that has been depricated :https://github.com/logtd/ComfyUI-LTXTricks
A new model 0.9.5 just been released. At this moment recommend to go with V5. Will try to fix it, but can´t guarantee, need to check how to incorporate new model 0.9.5.
update: looks promising, got Ltx 0.9.5 running. Setup works with 0.9.1 and 0.9 as well, also GGUF seems to work (not avail. yet fot 0.9.5, matter of days). So I plan to release V7 supporting all 3 models with GGUF
update: Work in progress version of V7 with LTX 0.9.5 support added to Experimental Tab. Technically it supports all three models.
I had this exact error, realized I would need to update LTX Video node. Manager said it was in nightly mode and did nothing, git pull said already up to date (it was not the file dates were mostly Dec and some early january dates. I had to download the zip and exact into the node folder. Ran install requirements but all satisfied, but now that error has gone
there is a new LTX checkpoint v0.9.5 https://github.com/Lightricks/LTX-Video
fck... New LTX Model requires own setup, old workflow not working after update and Hunyan I2V to be released this week. I am in hell..... :)
@tremolo28 good luck! hope you are days off to implement all ;-)
i already using the normal flow from ltx, great results already!
work in progress Version added
experimental 095 someting wrong with the promptenhancer? error message: Expected all tensors to be on the same device, but found at least two devices,
Getting the same error, maybe the captioning model is too large to fit in low vram GPUs?
hm, dont know what is the issue, it works on my pc (16gb Vram, 64gb Ram). However, the model behaves sometimes odd, describing stuff, that isnt there, etc. I might upload a version with both florence and ltx prompt enhancer.
I've reused the captioning part from V6 and it works again https://i.ibb.co/vCMcJGbW/Screenshot-2025-03-06-000115.jpg
{kind=link}
Have uploaded a new Version to Experimental Tab with Florences as default and LTX Prompt Enhancer as optional captioner
@tremolo28 thank you ❤️
@tremolo28 thx! going to experiment!
This is an issue with vram. 12gb does the same with this node every time.
Temp fix if you want to edit, im sure it will be fixed
@rocky533 Thanks for pointing the way to fix it - however, does the prompt enhancer also improve the output? Did you compare at by any chance?
@EliteLensCraft i got it to make prompts, but i did not make the fixes, so it errors most of the time. But the prompt seemed coherent. I dont know if it will be better, but it seemed well formed for what i look for. Better than florence alone or searge like i use normally.
@EliteLensCraft did some test with both florence and LTX prompt enhancer on same input images. For me the enhancer delivers more unpredictable results, resulting in more unstable clips compared to florence. Enhancer is also a bit censored (if you name some private bodyparts, it returns a message like "I cannot create content that is explicit"). Thinking about dropping the LTX prompt enhancer from workflow, due to above, plus the Vram issue and adding additional complexity, but not a lot of value.
@tremolo28 I've seen a WAN-Video prompting guide, like: https://www.comfyonline.app/blog/wan2-1-prompt-guide - however, LTX gives some guidance on how to use but mostly T2V e.g. https://huggingface.co/Lightricks/LTX-Video (if you scroll down) but I'm still not sure if it is more important in the usecase of I2V to describe the scene itself OR how the scene should behave in terms of camera movement/changes/effects and so on...
@EliteLensCraft thanks, mate
@EliteLensCraft LTX works off very simple prompts for ITV. Text to vid does not do well no matter what you type. ITV works with as little as, "a woman offers a shy smile and wave to the camera" You dont need to describe whats in the image, just what you want to see the image do. This only changes when you have movement that moves the background or the subject moves to show another part of themselves not in the image.
Thanks for the new workflow.
For me, v7 with LTXV0.9.5 is more difficult to adjust video than v6, and currently I can't use teacache (and the update breaks nodes!) I am not sure how to fix this problem.
I look forward to future GGUF and teacache integrated versions.
we might need to wait few days, teacache might require an update and GGUF models need to be created.
You can follow this repo/Link for updates:
Teacache: https://github.com/kijai/ComfyUI-TeaCache (Kijai´s node, he is usually fast with updates)
GGUF Models: https://huggingface.co/calcuis/ltxv-gguf/tree/main (awaiting LTX 0.9.5 GGUF)
I agree, 0.95 seems better, and the new nodes are nice. But when they removed many nodes... it borked many peoples workflows and the new nodes are harder to control output.
(Self resolved)
Apparently “wave speed” is still available in 0.9.5, so placing the “Apply First Block Cache” node between the “Checkpoint Loader” node and the “LTXV Apply STG” node reduced the generation time by about 45% in my case!
Manager says can't finde these nodes:
pr-was-node-suite-comfyui-47064894
pr-was-node-suite-comfyui-47064894
comfyui-crystools
Did 0.9.5 break STG? Older WF that was pretty good at 0.9.1 is horrible output on 0.9.5. After updating nodes I got my older WF with salt and pepper working but the output sucks so I guess there is something else?
Wil try experimental see if I can figure the change.
Wondering if time to go back or check wan out.
I agree with that.
From what I have tried, LTV 0.9.5 seems to give more stable results with an output size of 1024p than 768p. However, it is important to note that the increased output size and the inability to use teacache increases the generation time.
@mine73kp2_diffusion teacache works. At least https://github.com/lldacing/ComfyUI_Patches_ll this one does. Its a flux model type.
Memory use is also up with new model.
Your 0.9.1 workflow provided much higher quality and detailed video at 1280 x 704 than 0.9.5. My imagery has anthropomorphic fur, and there is no comparison between the two using the same source. From what I can tell, its impossible to go back. (Edit for clarification) for the reason you describe below. 0.9.1-r2-q8_0 plus v0.9-vae_finetune was a chef's kiss.
@Prestog123 You still can use 0.9.1 with finetune VAE with v7. Also Wavespeed/Teacache is there.
But yeah, we can´t go back to original 0.9.1 workflow, as some of the used nodes have been changed when 0.9.5 was released.