



















Check my exclusive models on Mage: ParagonXL / NovaXL / NovaXL Lightning / NovaXL V2 / NovaXL Pony / NovaXL Pony Lightning / RealDreamXL / RealDreamXL Lightning
If you are using Hires.Fix with V5 Lightning, then use my recommended settings for Hires.Fix (3 Sampling Steps, Denoising strength: 0.5 and CFG Scale 1.0 - 2.0) or other settings you find better for you.
Use Turbo models with DPM++ SDE Karras sampler, 4-10 steps and CFG Scale 1-2.5
Use Lightning models with DPM++ SDE Karras / DPM++ SDE sampler, 4-6 steps and CFG Scale 1-2
Please pay attention to the model file name, the part of the name after the underscore is the true version of the model.
The model is already available on Mage.Space (main sponsor)
You can also support me directly on Boosty.
RealVisXL Hugging Face Full Collection
The model is aimed at photorealism. Can produce sfw and nsfw images of decent quality.
ᅠ
Recommended Negative Prompt:
(worst quality, low quality, illustration, 3d, 2d, painting, cartoons, sketch), open mouth
or another negative prompt
ᅠ
Recommended Generation Parameters:
Sampling Method: DPM++ SDE Karras (30+ Sampling Steps) or DPM++ 2M Karras (50+ Sampling Steps)
ᅠ
Hires Fix Parameters:
Upscaler: 4x-NMKD-Superscale-SP_178000_G / 4x-UltraSharp upscaler / or another
Denoising strength: 0.1-0.3
Upscale by: 1.1-1.5
ᅠ
Optional Parameters:
ENSD: 31337
ᅠ
This model is:
ᅠ
Huge thanks to the creators of these great models that were used in the merge.
SDVN6-RealXL by StableDiffusionVN
TalmendoXL - SDXL Uncensored Full Model by talmendo
ProtoVision XL and DynaVision XL by socalguitarist
Cinemax Alpha | SDXL | Cinema | Filmic | NSFW by viakole
Description
improved skin details
slightly improved anatomy
images are slightly more contrasty
FAQ
Comments (139)
Upd1: V2.0 is already available on Hugging Face, link in the model description.
I got the model uploaded to CivitAI just in time. Now I am sitting without internet on my computer and cannot upload the model on Hugging Face. The disconnection happened just as I was uploading the model on HF. As soon as the internet is back I will upload the model.
Restart sampler is good for this model.
This is a really excellent model, maybe the best so far for photography.
Have you considered including Realistic Stock Photo and/or Fodda XL Photorealism in your future merges? They're both also very capable, although I would say neither have quite the quality of the depth of field you've achieved here.
Hi. If these models don't restrict this model too much then I might be able to work something out. But for now, the new base is good enough to merge with the trained model :)
Last version of Fodda XL (6.0) is 90 percent or even more identical to your model. Or you guys used the same checkpoints or... I don't know. But it is a fact.
@WTFusion Hmm, that's weird. I couldn't find this model on CivitAI right now. Does it generate almost the same results as my model? Or did you check it with the tool that comes with the Super Merger extension?
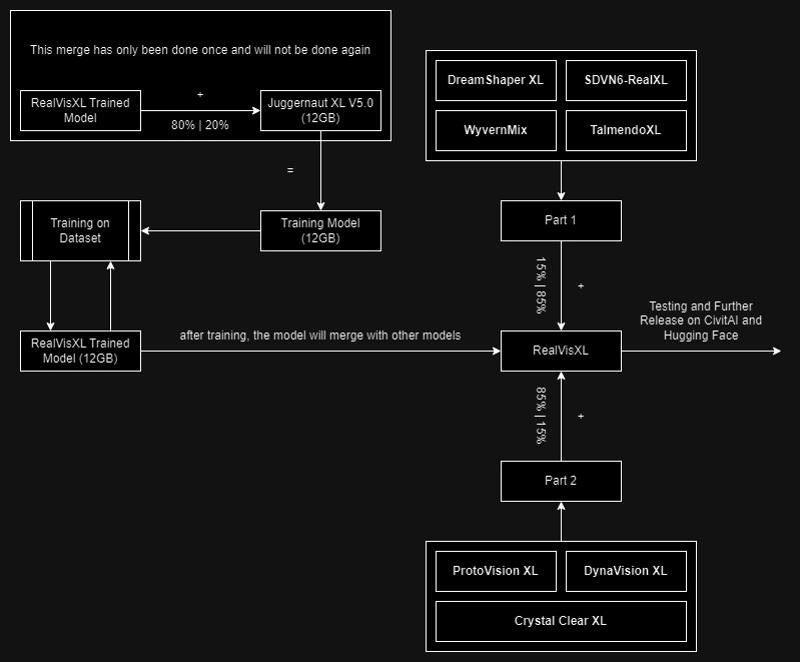
I've updated the model description and posted a schematic of the model showing how it was created.
@SG_161222 Yes, it generates very similar results. The only difference is in the color balance and minor details. The model disappeared after I asked him about this in the comments.
@WTFusion Hmm, that's very interesting. Thanks for writing about it :)
By the way did this model come out after mine came out?
@SG_161222 Yes, shortly after your model was released, it was over yours in the feed
@WTFusion Okay, thanks for your info :)
the model is amazing, pls add inpaint
Hi, I downloaded the inpainting model weights yesterday. I'll try to do it.
how to get good eyes ?
Easier to get "luck of the draw" when using random seeds than v1. Great update!
Hi! Thanks, very glad to hear that :)
After a little rest I will start working on V3.0
Is it necessary to credit the author when using this model, even when publishing the generated images?
Or is it only required when releasing a model that incorporates this amazing model?
Wow... this is already rendering amazing results! Thank you!
Thank you :)
I predict the emergence of many photorealistic models)
Hi ~,
I want to know how many batchsize you set?
thank you~
Hi! Batchsize = 1
I love this model!
Will it be compatible with ControlNet in the near future?
Is it possible to have access to version 1.0 overall 2.0 is better but for certain prompts 1.0 performs better
Hi. Just select V1.0 (BakedVAE) from the list of model versions.
I love your model. I was wondering, how many images did you use to train it?
Hi! Thank you! At the moment it's 1740 images.
Upd1: saw information about canceling scheduled power outages, the information below is no longer relevant.
Hi, everyone! I'm here with some news. From tomorrow I wanted to start working on V3.0 but I will have to delay it due to the power shutdown. I also have the exact schedule of the shutdowns.
From 8 am to 5 pm.
October 2 - October 6
October 9 - October 13
October 16 - October 20
I will try to work on an update between these shutdowns.
Any updates about v3.0 ? Great work, thanks.
i really like this model but i have an issue here, why i keep generating the same person over and over again? i made a preset prompt to describe a word, this is the prompt looks like
front shot, portrait photo (random person do a {word}:1), looks away, natural skin, skin moles, cozy interior, (cinematic, film grain:1.1)
i hope someone or the creator can help me to solve this.
thank you
Hi, try adding nationalities to the person.
You can also add a random name.
If you copied the workflow, disable Clip Set Last Layer node, worked to me 👍
I'm not sure why but on both webUi and ComfyUi. I get really blurry images. On webUi I'm using the recommended upscaler 512x512 to whatever 1.5 of that is, denoise I tried the suggested value range. On ComfyUi I didn't do any upscaling and if denoise is anything under 1.0 it becomes either a Piscasso or just a complete blur. I tried pretty much all the prompts on the first page of this gallery with the exact settings. I'm running on a 8 vram 3070
Are you generating images at the resolution at which SDXL was trained (e.g. 1024x1024, 896x1152, 768x1344)?
it's because you're doing 512x512, for SDXL it is recommended you use 1024x1024, 896x1152, 832x1216, 768x1344, 640x1536
ah yeah, that made things much better, the details especially eyes and hands are still a bit off tho, is it just some hardware limitation?
Well this quickly became my favorite when it comes to realism, getting some amazing portrait results. Amazing work!
amazing model. used it on rendernet.ai
I hope males will be anatomically correct someday
xpenis lora seems to help a bit
@elejama Thank you, that one sorta works, I render huge plus sized men (imagine enormous santa claus naked) and the xpenis lora makes them skinny men (the penis works tho)
@Grandpa yeah, it's contaminated with skinny guys with hairy legs but SDXL misses penis data in general so we have to wait or train our own loras
Guys why am I getting ONLY body horror? I mean I grab the exact commands from your own examples and get bodies morphed together. What am I doing wrong? Auto1111.
just my 2c: add a list of negative prompts and set the ideal image size
V2:
Really like the details and sharpness of this model.
What I struggle with the most by far are hands. Mutilated fingers are the main reason why 90%+ of all my generations get deleted.
Closeup faces are perfect. Once the person get further away however (full body framed) it struggles with eyes and teeth.
Hi, thanks for the comment. I have some ideas on how to fix the hands.
Faces, eyes and teeth can be fixed in some cases with Hires.Fix
is there a config file anywhere for this?
@SG_161222 is there a config file anywhere for this?
@SG_161222 Hey, thanks for the reply. After tinkering with more SDXL models I must say that my initially described 'hands'- and 'eye + teeth from further away'-problems seems to be where many SDXL models struggle in general. (Did not have tried that many at the time) Any kind of process that re-adds noise during image generation seems to help a bit - like using ancestral samplers or upscaling with 'HiresFix'. It is as if the AI sometimes needs some more random wiggle room to converge to good hands.
However I do think this model could definitely improve hands. Compared to other models the best hand results I got are from the 'nightvisionXL'.
Anyway, I rated it 5 stars because of the very detailed skins this model can create. :D
@SG_161222 can you tell us about this ideas to fix hands ?? im discarding the 90% of the generations too due to the bad hands. Thanks in advance for your job !!
Do you have any plans working on inpainting models?
I think this is one of the best models but the depth of field is off i did some face images the nose that's supposed to be closest to the camera gets blurred out and also on the forehead But anything else seems to be OK . thank cant wait for the new update
Thanks for this!,Do we need to use any kind of vae (fp16_sdxl_vae.safetensors?)
or just the model itself?
Don't need VAE. The title of model itself say it: "backed VAE".
I would avoid using any VAE if a model has its own VAE inside.
Can we use the standard SDXL refiner with this (say, switch at 0.7...), or should we not use a refiner?
you can use a refiner but the refiner gives a certain look and feel to the images, it feels like a "beautification" filter, i either recommend a switch at 0.8 or 0.9, but using the refiner is a very subjective thing, try to use the same seed and same settings and use with and without refiner and pick the one you like more and go with that
I don't think it needs refiner, but you can use refiner if you want. I usually don't use refiner with models that don't need it, because it's just a waste of time for a little bit of different but not better result.
Thanks guys. I found that for this model, the refiner wasn't needed.
The best!!!
I'm fighting a brown hue in most of my photos, but warm filter as a neg and cool filter as a pos (optional) seems to help.
Cancel that, this primarily happens in "bedroom" prompts. Just use "white bedroom" or other color instead. Completely eliminates the brown.
Can I lora-train my own photos with this model? I'm planning to use Kohya GUI on Kaggle. Could anybody tell me if there is important settings I should definitively be ensuring to have? Thanks in advance guys.
@SG_161222 same objective here, can we just take the model and re-train it on our own (few) images? like Dreambooth+SDXL ? do you have any recommended way / settings of doing so?
We offer SDXL LORA training tutorials on Fiverr! We also offer an 10USD OFF in any package of your choosing if you write you came from Civit.ai!
You can find us here: tamart_ai | Profile | Fiverr
Why does this model have a much higher graphics memory ratio and slower rendering speed compared to other models? Is it my computer problem
what card are you using?
No same all other sdxl models generate way faster but this one is the best one
forget useless Realistic vision model and make this cool model new final update plzzzzzzzzzzzzzzzz
I was never able to create any nude images using XL models. What am I doing wrong? I just moved from SD1.5 to SDXL and the settings are suited for SD1.5, by the way.
Ditch all your negative prompts. Try simply "a nude ____ woman, cinematic lighting"
naturist, for example = naturist woman
it is always generating female images and not following the prompt
Trying to install this on draw things but it's crashing the app everytime. Anyone know what's causing this and a possible solution?
Love this one. One of my go to's!
Everyday I wake up and pray for V3. Can we help?
Hi. I'm in the finishing stages of balancing a common dataset right now. Immediately after the release of RV6.0 (B1), I will continue training RealVisXL V3.0. This will happen in the coming weeks. Thanks waiting for the update :)
@SG_161222 sorry for my ignorance why is there a need to continue xd1.5 models when sdxl is better?
@cvai1 sd1.5 requires much less resources than sdxl :)
Will there be an inpainting version? :)
@SG_161222 I am so very greatful for your work.
i was about to create same comment, that everyday i came here to check the new version.
love u man
@nishu Hi! V3.0 stats will start updating early next week :)
@hujakuja Hi! As soon as I can figure out how to make an inpainting version of the model, I will :)
Hands down my go-to. Can't wait for next version.
Hi! I'll continue working on V3.0 soon. Early next week :)
Usually i use realisticvision and it's so fast to have my picture, around 10 sec.
But with RealVisXL with the same setting, i need minimum 3 min!! What is the problem?
realvisXL is a SDXL model, realisticvision is a SD 1.5 model
one of my fav model. I love also that the creator keep update infos about upcoming v3 + all those graphs. Really professional.. as the output images.
Vote 100
Will the next version be good at butts? Haven’t really tested with this version. Male and female but I only care about male. I would want balls behind the ass too when being given a back view.
haha didn’t think you’d actually see this😂 I do want the model to be able to do this but I fully understand if you are unable/unwilling to especially considering this isn’t a primarily nsfw model
@plus1 Hi! I think I can do nsfw for men. But it will take some time and most likely it won't be in V3.0.
Jesus...
Hello! Could you make an SDXL TURBO version of this model? Thank you
Hi, I think I will do this with the release of V3.0 for all versions.
@SG_161222 Great news, thanks!
@SG_161222 lovely i cant wait!
@SG_161222 we are waiting
@SG_161222 This is my favourite XL realistic model. That would be awesome. Thanks!
Hi, everyone! Training V3.0 is complete. I have already merged (maybe not the last one, depends on your feedback) and uploaded the model on Google Drive. If you want to help test the model and leave feedback on it, the model is here. I would be very grateful!
I've already spent a few hours testing and comparing the V2.0 and V3.0 (now I'm finding it harder to beat the V2.0 in many aspects). The faces and hands have gotten a bit better and I'm already planning to make them even better in V4.0. Turbo versions of all versions of the model will come out with the V3.0 version. Thank you all!
Thanks! I've tried it as Realistic Vision XL 2.0 is my favorite model, will be eager to see your templates. I've posted 3 pics here using v3, hope that's OK :)
@plectrudecatastrophe Hi! Thank you so much for your help. Can you tell me which you liked better, V2.0 or V3.0? :)
Just wanted to say we all appreciate your work. I'll be trying v3 today.
Initial tests are showing that it is difficult to make a comparison, but here goes: hands and faces somewhat better, overall skin realism not quite so good, overall seems to be a slight color bias toward yellow. Testing continues.
@rob52840 Thank you! I'll see what else I can do with the skin and the bias toward yellow. Looking forward to your next comments :)
Awesome. Love RealvisXL 2.0 as is, so I'll definitely give it a try and let you know what I think!
@SG_161222 My pleasure! I see you've released a V2.1 - V3 also experiences occasional torso stretches. On the plus side, model seems very versatile and shows fewer mutations :-)
@rob52840 Thank you very much! I'm already preparing to update V3.0, when the updated V3.0 is available for testing I'll publish a post here with a link to Google Drive :)
I generated almost 100 images...v 3.0 is really great model! I'll post the best results under 2.0 model gallery.
Download quota for 3.0 exceeded. Can you re-upload please? :)
I tested v3.0 today vs v2.0 (my go to checkpoint).
Finding I am getting more ‘keepers’ from 2.0 than 3.0 so far using my model LoRA (ok, only be specific kind of image I was trying to render and my LoRA was also trained against 2.0 so maybe that makes a difference).
The images from 3.0 did seem more natural (her face and body - a lot more close ups of her face), but at the cost of definition, detail and dynamism.
Christmas came early! Thank you man, I really really appreciate your work.
@SG_161222 - actually, with a bit of juggling with the prompt skin detail and tone improve a lot over v2. v3 seems to handle different loras well, all in all, it's a worthy update. Looking forward to the next update :-)
@rob52840 Thank you! The update for V3.0 is now available, the link is in my new post :)
@SG_161222 Hi.. I've been trying without success to download the update, Google Drive spat me repeatedly out a couple of times when it was almost finished, Mega nz as well - doesn't hepl that my Internet connection is ****** slow. Maybe Mega's got a daily limit here where I live, might try installing a downloader with proxies and see if that helps. So at the moment I can't do any testing, sorry - however the comments from other users look good.
@rob52840 I can upload the model for you on Google Drive but to my other account, that should help :)
@SG_161222 Thank you very much - downloading now, will take some time...
@SG_161222 Nope :-( threw me out twice, and didn't let me continue. But I looked at the images from itsnotroobs, (great comparisons) and it's looking much better, doesn't seem to be too bright, maybe a bit too much saturation, but that's nitpicking. Faces and hands are definitely better than v2, detail looks better than v3.U0, in my humble opinion U1 looks good to go.
@rob52840 Thank you very much! Now this model is available for everyone and without downloading problems :)
@SG_161222 My pleasure - hope you found my comments of some use :-)
does it need a refiner, if so which one?
Thanks
I am very glad to find this model. I would like to congratulate and say thank you to @SG_16122 for your hard work for creating this model. The results are exceptionally good!
hi,
could you include in the next version some loras that can be activated with just a few keywords?
I'm thinking of "EnvyZoomSliderXL" "sd_xl_offset_example-lora" "polyhedron_chiaroscuro" or others if you have any ideas.
I can give you some buzz if you need it to do this...
thanks
Hi, thanks for the suggestion, I'll see what I can do :)
@SG_161222 great!
the idea would be to incorporate loras that manage light, framing and details, because I use Fooocus and it's limited to only 5 loras slots, which would leave places for others.
Do you need Buzz to do this? I don't know if you use the Civitai platform.
Thanks a lot!
The hard work is paying off mate. Ver 3.0 getting close what i think XL is really capable of.
You are a Rockstar! Thank you!
Hi everyone! (V1.0, V2.0) Turbo will be uploaded on CivitAI and Hugging Face within a few hours. V3.0 is still in test (I will decide on the release of the model based on your feedback).
Hi, thanks for your work. I have some testresults for v3.0 for you. Were shall I upload these?
@VinnieNL66 Hi! Thank you so much. Can you upload this on Google Drive? :)
Details
Files
Available On (1 platform)
Same model published on other platforms. May have additional downloads or version variants.