



















Check my exclusive models on Mage: ParagonXL / NovaXL / NovaXL Lightning / NovaXL V2 / NovaXL Pony / NovaXL Pony Lightning / RealDreamXL / RealDreamXL Lightning
If you are using Hires.Fix with V5 Lightning, then use my recommended settings for Hires.Fix (3 Sampling Steps, Denoising strength: 0.5 and CFG Scale 1.0 - 2.0) or other settings you find better for you.
Use Turbo models with DPM++ SDE Karras sampler, 4-10 steps and CFG Scale 1-2.5
Use Lightning models with DPM++ SDE Karras / DPM++ SDE sampler, 4-6 steps and CFG Scale 1-2
Please pay attention to the model file name, the part of the name after the underscore is the true version of the model.
The model is already available on Mage.Space (main sponsor)
You can also support me directly on Boosty.
RealVisXL Hugging Face Full Collection
The model is aimed at photorealism. Can produce sfw and nsfw images of decent quality.
ᅠ
Recommended Negative Prompt:
(worst quality, low quality, illustration, 3d, 2d, painting, cartoons, sketch), open mouth
or another negative prompt
ᅠ
Recommended Generation Parameters:
Sampling Method: DPM++ SDE Karras (30+ Sampling Steps) or DPM++ 2M Karras (50+ Sampling Steps)
ᅠ
Hires Fix Parameters:
Upscaler: 4x-NMKD-Superscale-SP_178000_G / 4x-UltraSharp upscaler / or another
Denoising strength: 0.1-0.3
Upscale by: 1.1-1.5
ᅠ
Optional Parameters:
ENSD: 31337
ᅠ
This model is:
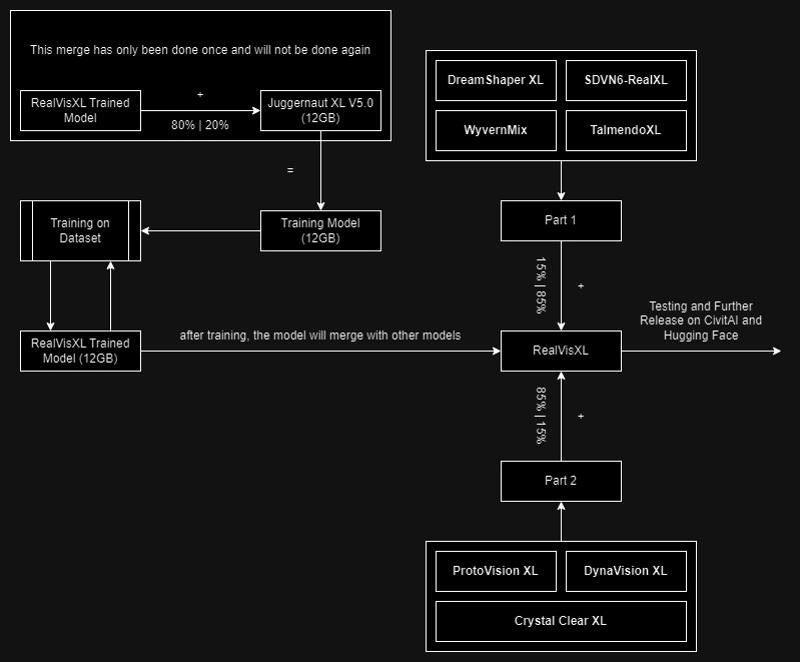
ᅠ
Huge thanks to the creators of these great models that were used in the merge.
SDVN6-RealXL by StableDiffusionVN
TalmendoXL - SDXL Uncensored Full Model by talmendo
ProtoVision XL and DynaVision XL by socalguitarist
Cinemax Alpha | SDXL | Cinema | Filmic | NSFW by viakole
Description
Based on V4.0.
Noise has been reduced compared to the V3.0 Turbo.
FAQ
Comments (243)
question, is lightining better then the turbo in terms of image quality and creativity ? i know lightining is faster but what about quality ?
will it mean its nexgen turbo? , another question as this model based on many others models , its also based on the latest ver of Juggernaut ( lightining)?
@karldonitz28599 gpt wrote this didn't it
when I try loading this in the checkpoint, it does not process and times out. Am I doing something wrong?
Lightning model is good at real photography style, not friendly to other art styles (using sdxl prompt style node in COMFYUI to modify the art style can not make it draw cartoons, comics, etc.), input other art style effects in the positive prompt word input box it still produces realistic photos. The lightning model doesn't get smaller, does it mask some data during training to get faster generation? Or need special keyword activation? (Same problem with the original Lightning LORA)
The styles could be due to the low CFG used normally for Lightning, so it doesn't adhere that much to the prompting style
@LiteSoulHD THX~
Whouhouuuuu Lightning let's goooo. I love this model so much. I live for seing it updated.
what should be step, cfg, sampler & image size for Lightning version
DPM++ SDE Karras / DPM++ SDE sampler, 4-6 steps and CFG Scale 1-2.
I usually use the standard SDXL resolutions.
This is the best most realistic model on Civitai without a doubt. Truly amazing and looking forward to what you come up with next.
May I ask what is the program and settings (or workflows) you used to create such high quality outputs? I struggle with fixed sizes like 512*768 all the time, and detailers or upscales can't get me a result close to this at all.
Use higher resolution like 1024 x 1024.
@vapochill I use them already, but when upscaling, the result is not as good as this at all
@Helpmepls Use a good upscaler like 4x ultrasharp. Max upscale 1.5-2x for best results, steps the same as sampler or half.
When I use this model I'm getting this error: TypeError: 'NoneType' object is not iterable”.
Im using SD WebUI Forge insted of Automatic1111. Other pre-installed model like RealisticVision51 works out for me.
Any clue?
Thats an issue with Forge though so you have to report it there
@HanaShiina thx for your answer! I guess so! so sad :(:(
@HanaShiina how do I report this case?
If you are using png info to extract a prompt you were using in A1111, it will transfer a lot of information over, including things not present in Forge. I recently encountered the same error, and it was because one of the ADetailer models it was trying to load through png info wasn't in my Forge install directory. You can verify this by simply copying the text you used in the prompt, negative and positive, and try running it without moving all the other settings.
you don't have the upscaler that is being pulled over from the prompt in the high res fix. change to an upscale you have and that error should go away
Best model to use with InstantID. Really best and fast image generation with cfg 1.5 and 6 steps.
filename: realvisxlV40_v40LightningBakedvae.safetensors
should be: realvisxlV4.0_v4.0LightningBakedvae.safetensors
Hi, I can't fix this, it's such a model file naming pattern at CivitAI.
I get this error trying to run in automatic1111. What could the problem be?
changing setting sd_model_checkpoint to realvisxlV40_v30InpaintBakedvae.safetensors [ae5c98bc88]: RuntimeError
Traceback (most recent call last):
File "C:\AI\stable-diffusion-webui\modules\options.py", line 146, in set
option.onchange()
File "C:\AI\stable-diffusion-webui\modules\call_queue.py", line 13, in f
res = func(*args, **kwargs)
File "c:\AI\stable-diffusion-webui\modules\initialize_util.py", line 174, in <lambda>
shared.opts.onchange("sd_model_checkpoint", wrap_queued_call(lambda: sd_models.reload_model_weights()), call=False)
File "C:\AI\stable-diffusion-webui\modules\sd_models.py", line 787, in reload_model_weights
load_model_weights(sd_model, checkpoint_info, state_dict, timer)
File "C:\AI\stable-diffusion-webui\modules\sd_models.py", line 375, in load_model_weights
model.load_state_dict(state_dict, strict=False)
File "c:\AI\stable-diffusion-webui\venv\lib\site-packages\torch\nn\modules\module.py", line 2041, in load_state_dict
raise RuntimeError('Error(s) in loading state_dict for {}:\n\t{}'.format(
RuntimeError: Error(s) in loading state_dict for DiffusionEngine:
size mismatch for model.diffusion_model.input_blocks.0.0.weight: copying a param with shape torch.Size([320, 9, 3, 3]) from checkpoint, the shape in current model is torch.Size([320, 4, 3, 3])
Hi! There is no inpainting support in Automatic1111, so you will have to download additional files to make inpainting models work.
This should help you.
"light-and-ray commented
Works well even with merges. To install you need to download patch of this pr: https://github.com/AUTOMATIC1111/stable-diffusion-webui/pull/14390.diff
Then open command line in your webui directory. And run: git apply <path_to_the_diff_file>"
buenas SG_161222, Podrías contactarme por privado nos gastaría comentarle algo sobre sus modelos XL.
o email. [email protected].
gracias
@SG_161222 sorry i am getting this error
PS D:\stable-diffusion-portable-main> git apply C:\Users\s\OneDrive\Desktop\14390.diff
error: configs/sd_xl_inpaint.yaml: already exists in working directory
error: patch failed: modules/processing.py:106
error: modules/processing.py: patch does not apply
error: patch failed: modules/sd_models_config.py:15
error: modules/sd_models_config.py: patch does not apply
error: patch failed: modules/sd_models_xl.py:34
error: modules/sd_models_xl.py: patch does not apply
getting
RuntimeError: CUDA error: out of memory
CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
Compile with TORCH_USE_CUDA_DSA to enable device-side assertions.
can anyone help ?
Ur gpu is bad.
Turn off live previews if you have not already. I still get the error sometimes, but its less frequent.
@UMCEKO atleast comment something useful ,we can troll some other day , i don't think an rtx 4050 6gb is that bad , even if that's the case then they should've atleast mentioned the required VRAM size
@lukesnell ok i'll try it , or should i try to update torch version , also i am thinking of switching forged version as i am still using automatic1111
forgot to mention i am using replacer , with groundingDino_SwinT , and SAM model SAM_vit_h , is this causing problem ? cause i am changing wardrobe or removing it i wanna see what it's results are ? previously i was using epicphotogasm_zinpainting.safetensors , was making great results but sometimes , poor results too
@akshaygodofwar413 definitely update torch version, you can also try using these in the command line if you have not already,
Nvidia (12GB+ VRAM): Use --opt-sdp-attention or --xformers.
Nvidia (8GB VRAM): Combine --opt-sdp-attention or --xformers with --medvram
Nvidia (4GB VRAM): Combine --opt-sdp-attention or --xformers with --lowvram.
@lukesnell Can you please detail what those do ?
@gladstonepro562979 https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Optimizations
@akshaygodofwar413 Sorry mate I was high when I wrote that.
@UMCEKO it's okay , understandable , no offense
Hello,
Could you please tell me which are the optimal resolutions I can use please. I am on the 4.0 turbo baked model.
Thank you : )
most of the time I use 832*1216
It's a shame that all of these Lightning and Turbo models still can't hit the dramatic shadows that a classic 20-30 step model can. I'll keep trying, but I find myself going back to 4.0 regular, despite the lower speed.
My favorite model so far. Quick question tho, I keep getting getty image boxes. What's the best way to get rid of those?
Great text match ability.
Thanks for this great Model... This may be the one who made me (almost) switch from 1.5 to SDXL...
Thanks for the work. What is the difference between this model and V3?
What value are you using for Eta for k-diffusion samplers?
Can't use ControlNet, help me
Newbie here, sorry for the amateur question, how do I run it after downloading the file? Are there any other programs that I should have installed?
You need to use a program like a1111, comfyui, sdnext, or sd forge (or similar).
@MysticDaedra Thanks a lot!
If you're unsure about how to install various software, Pinokio is an excellent resource. It has one-click installations for a wide range of new AI tools, simplifying the process. Just make sure you have a PC equipped with a pretty decent graphics card. A1111 and forge are great for newbies and if you really want to get into it then you can use comfyui which in my opinion has the highest learning curve
How do I download it? It says 20 hours left :(
I have no problem in downloading other models or LORAs.
I'm struggling with textures in 4.0. A lot of different subjects seem to be relatively flat or plastic-y to me. This is a general problem in SDXL, but 4.0 (not the lightning version) specifically seems to have this issue.
Are there any recommended methods for increasing texture detail? I've tried embeddings and detail loras, but none of them really do anything to the textures.
Getting the lighting down is first thing before thinking about details/texture. Have you played with that?
One of the best SDXL models out there.
Nice one!
What I don't understand is, do I need to download all of these, or just the latest version?
D/L the latest version, 4.0. You can choose between Lightning, Turbo, or normal. The first 2 have faster inference, but perhaps the quality lacks a bit. Either would do, imo.
HOLLY CRAP!!!! this model can generate an anatomically correct bee... you have no idea how many models I tested in doing that. This is progress
This model is probably the best realistic model right now- thanks!!
hello, can you also outpaint with this model?
The Lightning version is the best XL checkpoint I've used so far. Excellent job!
How can I privately consult you? Am ready to pay for your time and knowledge, I really need help.
you may think this model is only best for realistic character portraits but it's great at EVERYTHING!
It's really nice.
Best overall model for SDXL. I tested for what I needed and compared this mainly with Juggernaut. And while both are great. RealVis won me over for so many incredible reasons. Versatile, accurate, creative, and all-round amazing! My go-to SDXL model now.
I've tried many SDXL checkpoints and this is hands down the most consistently photorealistic one I've tried thus far.
This is a great model but bit work slow in my pc I guess due to my hardware but it is truly amazing
wow
Congratulations now SDXL models looks exactly the same as SD1.5!!!
Hey, you model is great...but you need to work on sitting, laying, handstanding etc. it has a problem with anything not standing or sitting straight. But i do like it a lot after testing it for a day now.
Can we get a config file for the inpaint model?
If I reach second token in prompt (more than 75 chars) images will get distorted. Any settings necessary? Fantastic model BTW.
So far the best model for my needs!
But one question, I do not get Girls with really short hair (1-2 Inches) (expect I use 'Buzz Cut', but this is too short for me).
Does someone knows good keywords, to get Girls with really short hair?
there's some good short hair loras. or start with a SD15 image and /remix to SDXL
@MorganFreeman Thanks, I found a lora for my needs
@niper53 can you tell Wich one please
@kd231002573 This one: https://civitai.com/models/78661/ashortcut
blonde pixie cut,try it
@akuwa666 Do you mean a lora named 'blonde pixie cut' or do you mean just use the keyword 'blonde pixie cut'?
@niper53 keywords,gpt give to me
lightning version is same as same model using lightning lora ? then if yes , any lose of quality ?
then , lightning model can be used as regular non lightning model ??
Can this model be used commercially?
the model uses Clip Skip: -2.
should be mentioned in the description.
how do you even set a negative clip skip? Im in stable diffusion forge and it can only go down to 1.
@wesadgveagea I don't know 'forge' but I think I read somewhere that by default all models (checkpoints and loras) are using Clip Skip: -1 by default and in ComfyUI it uses Negative -1 and it's the minimum while in Forge can use it as a positive 1 - which would be still the same thing but represented by the software differently (I think). But some Models require Clip Skip: -2 to work properly. Also from my experience anime/cartoon models are using Clip Skip: -2.
This is the error that I get if I try to change Clip Skip in ComfyUI to a Positive Integer:
"Prompt outputs failed validation CLIPSetLastLayer: - Value 1 bigger than max of -1: stop_at_clip_layer"
I think in ComfyUI -2 translates as +2 in Forge.
@EROS1CA yes
May I ask how you found out about CLIP skip? I compared -1 & -2, but -1 seems a little better.
@CHNtentes With the ComfyUI 'default' workflow I gen an image, then load a "CLIP Set Last Layer" node set it to :-1 make new generation (same fixed settings, steps: 4, cfg: 2, dpmpp_sde karras, same seed) and I get different result but when I change the CLIP to :-2 I get the same 1:1 image as the 'default' workflow (with no 'CLIP Set Last Layer' node at all). I also find -1 gens to have issues in the image while in -2 I don't see those. Correct me if I'm wrong. But doesn't the lack of "CLIP Set Last Layer" implies you're using the default CLIP Skip by the model/checkpoint?
It's an XL model, that makes no sense
@diffusionfanatic1173 what "makes no sense"?
Thanksssss
can i use this model commercially?
https://civitai.com/models/139562?modelVersionId=272378
when will you released RealVisXL V5?
if it's not ready then how much progress complete?
Noob question here. For models with "BakedVAE" does that mean in Forge we set SD VAE to "None" or "Automatic"?
BakedVAE means it doesn't need extra SD VAE. Therfore "None" is best. In this case "Automatic" would also work because there is no VAE file with the same name and it would do nothing, which is the same as "none".
I generated a music video using realvisxlV40_v40LightningBakedvae
Almost one year ago, I generated dozens of image with many different SD1.5 Models. After a long time I tried the this SDXL model. it is supporting artist styles as well. Definitely SDXL is far superior. I pay my respects to the maker of RealVisXL_v4.0(BakedVAE) checkpoint.
I'm having problems with making this one work. For some reason when I try this model I get noise as a result. I don't know why this is as this is the only model that's doing this for me.
change your sampler to ddpm with cfg 2 and it will generate nice pictures
@hamid29365494 already did that but to no avail, i redownloaded and now it works. dont know what went wrong
great quality! two issues though:
- it is very hard to convince it to do anything else but portrait. much harder than other models.
- the description says that it can do NSFW. I don't think so. needs more training or a merge
@jAC3KMdz3M5H Most of the results my prompts produce are full body views. I think, it is because I usually specify the shoes, that the girl in my image wears. I don't know, what kind of NSFW you want to achieve, but my images are all NSFW. But I want erotic, not sexual acts.
@niper53 okay, but "full body shot", "wide shot", etc. works in other models
@niper53 and regarding NSFW, this model produces scary anatomy. I've solved it by using a NSFW LORA at a low level without using any of the trigger words. Apparently this fills in the gaps of this model
I was able to generate NSFW using in the positive prompt (naked, nipples:1.5)
Thanks for great model. I am really loving to create images. realistic results.
I am having trouble generating realistic faces on full body, it there any prompts I should use. Also should clip skip be set to one or two
@nicholasmccabe304 I generate all my images with this model. They are all full body and photorealistic. I think they have realistig faces, see my profile (https://civitai.com/user/niper53 ).
I create for each prompt and seed with 10, 13, 17 and 20 steps, cfg-value 1.5 and sampler is euler_a.
If you are interested in the prompt, you need to download the image and look to Exif-Data (e.g. with ExifTool.exe) because civita.com does not realise generation-param from NMKD SD-Gui.
You can also send me a message, and I send you the prompt of the image
You may consider to use ADetailer. It hugely improves the results for full body arts
any update regarding version 5 release ??
Hi, I am currently continuing to work on Realistic Vision 6.0 B2 (extending the training dataset, which will also be used for SDXL and SD3 training). I think this will be the last update for this model. Next I plan to work on SD3, as well as continue to train RealVisXL.
@SG_161222 you means Realistic Vision 6.0 B2 is the last update? but RealVisXL & SD3 update continue in future?
@Beast01 Yes, Realistic Vision V6.0 B2 (SD1.5) will be the last update. Next will be the SD3 based model and the continuation of RealVisXL training.
@SG_161222 Many thanks, your models are always my choice
@SG_161222 Many thanks for the info. I'm looking forward to the next release of RealVisXL, and SD3 - just have to wait and see when they release it. By the way, need any help testing? (On Automatic1111). Rob
I made a blunder, this is a good model but it needs a good graphics card. the v6 version suits very very well for me and it's good. If you want a better quality you can test out your models on the v6 then try this version once you have streamlined your ideal prompt i guess
I have a problem when I generate naked women. The images are very good as usual with realistic vision xl, but it’s common that on the breasts of the woman appear a line from the nipples way down the breats. It’s very odd but common. How could I avoid that?
We see that on a lot of SDXL. You'll notice it even more when they are wearing clothing, specially bras or corset tops. I think it's leftover from something in the base model, since it's a somewhat common clothing hemline. It bleeds into unclothed images too. Saw it a lot in the early days across many models. Nowadays, with so many extensively retrained models out there, it's not very common, but I suspect there's a lot of the "early days" still under the hood of this model.
@shapeshifter83 I didn’t know that. I have tried in negative scars or something like that. But no success. Thanks anyway
Hi, I have the following issue: "Token indices sequence length is longer than the specified maximum sequence length for this model (95 > 77). Running this sequence through the model will result in indexing errors" The model has a maximum of 77 tokens or is it because I am using InvokeAI? Thank
This is a limitation of diffusers, a library used for generating images with SD models. Other methods use kdiffusion which parses the tokens differently and applies them at different steps, as far as I know.
@MachineMinded thank!
This is best SDXL lighting i ever use, faster generate and high quality detail realisitc image
noob question... how can i download the ckpt file version of this?
pick v4.0 (it should be already automatically be selected) and then click on the download icon. model should be around 6. something GB
How does one cross-post?
I believe as long as your generator software includes metadata about which checkpoint you used, as long as you make a post anywhere on the site it will cross-post it to the Resources that you used (like LORAs and Checkpoints). Alternatively, you can click the Add Post button on a resource and it will definitely post to that resource.
@RedAstronaut interesting. Thank you. Much of my metadata doesn't auto populate because I change my png files to jpg for the most part.
@MysticMindAi You can configure A1111 to save a JPG automatically and I think that will include the metadata.
FlashGordon is incredibly fast and best Lightning model nowadays for adding details (suck as skin texture for example) IMHO. But a huge downside is that it always stretch out faces to absurd look )) If I use landscape orientation (f.e. 1152x864) it seems okish. So if this isue could be solved on Portrait orientation it would be just amazing.
Another excellent model for realistic photos, I don't particularly care for or need the Turbo and Lightning models, so I can't comment on them, but the default RealVisXL V4.0 is excellent. I love the lighting and color grading it produces and how realistic people can look under the right lighting and in the right situation. Very good model, it could use a little work on distant/smaller faces because they tend to get deformed but that's nothing that can't be fixed with inpainting.
It's a model that creates very dynamic poses and allows for good camera control.
I'm getting a lot of weird faces, which I don't see in anyone's posts or the examples. Am I missing some settings or something? I had an older version of SD which had a toggle for 'restore faces' but the Automatic 1111 that I downloaded today doesn't have it.
imo, dont use restore faces, use ADetailer for webui. if you using fooocus try use paint for detailed face. Its easy to try. There is lot of tutorial on youtube. GL.
More speed for generate. Try sd forge
lightning models will be exact same as non lightning model plus using the lightning lora ?
This is the best realistic model on the site! But it feels like Lightning is better than regular v4? Sometimes I'd like more control, but using the regular version they always end up less realistic. Why is that?
yes you're right..
I gotta ask... do you need the lora with the lightning?
@zGenMedia Nope, no LORA. The lightning is baked in somehow. Just load up the model and use the recommended settings (DPM++ SDE Karras, 6 steps, CFG 2)
@RedAstronaut Is clipskip -2 on this? Thank you for that information btw. No where does it say anything about that. Thanks.
@zGenMedia I use clip skip 1. The CFG is the Guidance which I set to 1.5 or 2.
Any update on v5 status?
But , where is it ???
RealVisXL V5.0 Status (Updated: Feb 15, 2024):checking the model everyday on site for the V5 XL update but everytime i check nothing changes.
Hi, I'll be starting work on V5 in the next few days.
@SG_161222 Sounds great! Looking forward to it very much :-)
@SG_161222 Same man cannot wait for this. Made the jump from V2 to V4 and the changes were dramatic, huge improvement. So assuming you will merge all the other checkpoints update the latest versions and improve your own training. V5 has a lot of potential, I am sure.
same here (not everyday) but this model is the best i could find for realism !!! Love it !!!
@SG_161222 BEST. NEWS. EVER! Thanks!
@SG_161222 What do you use for Captioning? are you using GPT-4o captioning or something? I want to make a lora myself and want to know from one of the best models on civitai
@pigeon_ For SFW images, I use ChatGPT-4o. For description of NSFW images I use my small program for manual description.
It would be great if you could improve the capabilities of the RealVis XL V5 model to produce more realistic and better hand drawn characters and more poses can be produced
You do realize this is a photography-centric checkpoint right?
@penguinsrsocool
Do you realize this is a photography-centric checkpoint, right?
yes. I know that. But I want to create an image that is not what you think.
@karldonitz28599 use models that cater to hand drawn styles then? why is anyone even agreeing with this comment..? "make my milk more like apple juice, please"
great
This is the most powerful model I have ever used in realism. Thanks to the author for his dedication
Guys, I have a problem when using IP-Adapter on this model. It gave me very weird result, the face looks like a creepy doll! Anyone experience the same? Is it because of the IP-Adapter? Please help me !! :(
My setting for the IP-Adapter:
- Preprocessor: ipadapter faceid plus
- Model: ipadapter faceid plusv2
- Weight: 0.5, Start: 0.0, End: 0.8
Btw, thank you for sharing such a great model!
This is an sdxl checkpoint
Make sure you are using the Model: ipadapter faceid plusv2 sdxl
Great model for realistic style! I think one main reason is less saturation & contrast actually make images look closer to real life.
This model is well worth using, especially for those who like portraits, it produces the best skin texture I've ever seen!
this model is so good at photo realistic fantasy/surreal/artistic images. 8/10
Any 10/10?
@maykerev1812 I suppose each model has its own strength & weakness...
@maykerev1812 nothing model cant be 10/10 friend, because there is no perfect in this world
5.0?
Yeah they posted info about it but no download.
@zGenMedia where?
Hello! Yes, I know I have taken too long with V5.0. I had several unsuccessful attempts that required me to restart the model training. I am trying to improve the detailing, skin texture, anatomy, and increase realism. So far, everything is going well. I think I will soon show some examples.
@SG_161222 awesome can't wait
@P_Universe A small example: https://civitai.com/posts/4074141
@SG_161222 I assume the one below is 5? If so, good eyes, I hope you can improve the entire body from a certain distance but it looks great
@P_Universe Yes, the bottom one is a V5 :)
@SG_161222 the skin textures looks amazing!
@P_Universe Thanks :)
@SG_161222 love the look of v5, do you have an ETA on the model?
@SG_161222 Take your time man, I'm sure it's going to be great, thanks for your work.
Wow, this is a very nice real model, thank you brother, but I would like to ask, besides 1024*1024, is there any other better generation size? 768*1024 or 960*1280, etc. What size do you mostly use for your training set images?
Hi! Thank you! I usually use resolutions of 896x1152 and 768x1344. For training, I use 1024x1024, 896x1152, and 768x1344.
What an incredible model. 👍👍
I haven't waited for my ex to come back for that long.
Best Photoreal model, fast, prompt follow, general anatomy. All very well scored. 5/5
been getting consistent results with this base model. my favorite so far
Good jop , i like it
Can you train lora with this model?
{kind=link}
DO IT!!
nice model, fast images, beautiful girls. thanks for posting.
JUST AMAZING, I have no more words to describe this model, it is simply my favorite without a doubt, but there is one question that bothers me, why can't I use version 4.0 Lightning BakedVAE?
GOD
great to follower of prompts, for face swap on fooocus is impressive :)
What VAE should i use with it?
Just too epic!
Is there gonna be a V.5?
@ai_dreamer seems very close
@ai_dreamer thanks for that. so v5.0 will not be based on Stable Diffusion 3, and that there will be no SD3 version of RealVisXl as such?
@makaveli_313 sd3 totally sucked people gave up on it a while ago if anything id expect to start seeing FLUX fine tunes soon but the current v5 of RealVisXL is still based on SDXL-1.0
@pigeon_ thank you for answering : )
so currently v5 is at 90% completion but after its 100% completed training how much longer until it actually is posted on civitai
I am the best, this will be my favorite without a doubt, I will delete the others
Hello everyone! An early version of RealVisXL V5.0 (560k steps) is now available on Hugging Face. The model is still in training, and the final version will be released on Hugging Face and CivitAI at the end of August. You can leave your feedback on this version in the comments below.
Need a fast low step version, either lightning or hyper. And smother, low noise.
Are the settings required different? I just used it in my worfklow and I get a much more smooth looking image than with realvis4.0 which gives more detail and noise.
@ivanmomchilov8802 It seems I selected the wrong version that I intended to upload to Hugging Face. For now, I have made the model page private. Once I upload the correct version of the model, I will make it public again.
Thank you! good to know, I've downloaded it just before and some test looked good to me (using Forge), I'll wait for updates!
Please also release a Lighning version of V5.0. RealVisXL V4.0 Lightning was amazing!
Looking forward to it Thanks!
Can't wait to try it! Really enjoying working with V4.
i hate to say this but V5.0 is coming out at such an unfortunate time because FLUX.1 is all the rage now and on most image leaderboard even the smallest Flux model Schnell ranks higher than V4.0 of RealVisXL so I must say I'm not too excited for V5 anymore so I really hope you plan on fine tuning FLUX on your dataset I'm sure that will easily turn out amazingly
You are right, but I will still be using the SDXL model, like RealVisXL, since I am not capable of training a LoRA for the Flux AI model. I’m sure most people do not own 24GB of VRAM to train a LoRA for Flux. I have only about 6GB of VRAM on my RTX card, and I was able to train a LoRA using one trainer in just 3 hours. Flux is great, but SDXL models will still be very usable for most people like me, especially those who do not own 24GB of VRAM to train their own LoRA.
@PredictAnything I fully agree. I don't care about SD3 or Flux. Most users don't have a high-end graphics card. And then there's the censorship, even on Flux. I work about 90% with RealVisXL4.0 and can't wait for v5.0.
@favutuqe well yes of course for people who cant afford to run FLUX V5 is gonna be the best option but I can run Flux so I specifically am not excited. I'm not saying that V5 will suck or something RealVisXL is easily the best SDXL fine-tune but since I can run Flux I wish he would make one for Flux that's all I'm saying
Flux is unworkable without a 4090. The time sink is real. If you value time as a commodity and unless you are satisfied with lower quality Schnell than that's on you. But for vast majority of people that actually use Gen AI in a time sensitive setting with lower end GPU, SDXL is still the go to. And like the majority we looking forward to V5 on SDXL.
Looking forward to RealVis V5 on SDXL NOT on Flux. Thanks.
Flux is better than Stable Diffusion for composition and prompt adherence but I'm getting much better realism out of RealVis and it's much faster. My current workflow is to generate in Flux then img2img with RealVis to get something decent. Even though I use Flux, I'm looking forward to RealVis 5. Perhaps RealVis 6 can be a Flux model, but RealVis 5 is still a great idea.
Flux creates plastic skins on people, also sort of too clean and perfect for me.
@3r3de again so am i looking forward to V5 i just want to see a FLUX version developed aswell because I do have the GPU to be able to run FLUX dev
@Spoonman2002 um its called realism lora... fixes that issue easily built it doesn't really have it to begin with
@pigeon_ Have you actually tried the realism LoRA for Flux? It's nowhere near as good as RealVis.
@jbboncemore2 yes I think its almost as good as RealViz however a full blown RealVis version of Flux would crush easily
Yup it's better overall but RealVisXL makes images in two seconds meanwhile Flux 1 Schnell takes 1-2 minutes
@zayx only if your computer sucks I can make FLUX images in seconds so I personally am wanting a FLUX fine tune of RealVis but that doesn't mean I'm not still excited for SDXL Rewwalvis v5
I think the Flux Hypetrain is overrated. It is annoying to write extremely detailed prompts, and most of the custom nodes are not compatible. Therefore, I prefer SDXL. The quality of Flux is not bad, but with a bit of thought and a good workflow, you can generate images with this model that outperform Flux in terms of realism
Flux is a vastly superior base model, but it currently lacks a ton of knowledge that SDXL checkpoints have. Practically no real people, few copyright characters, few artists, bad at animals, lacks a lot of clothing styles, tends to ignore facial feature and body shape descriptions, etc.
It will be awesome once we get some good Flux finetunes, but that will take time.
Hello everyone! Today I uploaded RealVisXL V5.0 (596k) on Hugging Face. Last time, I made a mistake and uploaded the wrong version of the model. You can leave your feedback on this version of the model in the comments. I also tried training LoRA (training on CivitAI) based on Flux (including NSFW test images). Next, I will work on Flux (when there is support in OneTrainer) or SD3.1.
You are an absolute legend man! Anyways, the 13.9 gb fp32 version is about what? Can you give a little hint about it? As the file is kinda big to get so I would like to know what it actually is i.e. based on sdxl, sd3, flux or whatever..
Nice! Im looking forward to the FLUX fine tune very much because I can actually run FLUX on my computer and considering the base model of flux is already better than even the best SDXL fine tunes I cant even imagine what a FLUX fine-tune will be able to do
@JoshBMX This is the SDXL model version for those who need an fp32 model.
hello, not sure why, but I get TERRIBLE results with v5...... does v5 demand different samplers, steps or cfg?!
I love v4, use it A LOT !
-edit: hm, looks like my current workflow is the cause of the problem. When I use older workflows with v5 the results are EXCELLENT !
@MysticDaedra Hi! The model is not finished yet, so it is not on CivitAI. The final version of the model will be ready by the end of August and will be uploaded to CivitAI. You can leave comments wherever you like, even on HF.
@SG_161222 Thanks, I missed your earlier post and was super confused lol. Downloading now!
Woooow, finally realvis V5 and news on flux! An amazing 2x1!, super excited to try both
Thanks for the hard work, man! I'm excited to take this model for a spin
i like v4.0,Even version 5.0 can't generate a model runway
UPD1: Added a link to the post comparing Flux and RealFlux.
Hello everyone! If everything goes well, a test version of my realistic Flux "RealFlux" (images from test model) model will be released soon. The training of RealVisXL V5.0 is still ongoing, and the release date remains unchanged (end of August).
Nice to see you're working in Flux. We sure need your talent. Needless to say, Realvis5 will be an amazing final installment for SDXL. Really looking forward to it. Thanks.
Lol I come here everyday to check if you flux model has been released. I pledge 30$ if it is released tomorrow.
Looks like v5.0 (on huggingface) is fully completed! When will it be added here?
Details
Files
realvisxlV50_v40LightningBakedvae.safetensors
Mirrors
realvisxlV40_v40LightningBakedvae.safetensors
realvisxlV50_v40LightningBakedvae.safetensors
RealVisXL_V4.0_Lightning.safetensors
RealVisXL_V4.0_Lightning.safetensors
realvisxlV40_v40LightningBakedvae.safetensors
RealVisXL.safetensors
rv_lightning.safetensors
realvis_lightning.safetensors
realvisxl_lightning.safetensors
realvisxlV40_v40LightningBakedvae-mid_139562-vid_361593.safetensors
realvisxlV40_v40LightningBakedvae.safetensors
realvisxlV40_v40LightningBakedvae.safetensors
realvisxlV40_v40LightningBakedvae.safetensors
realvisxlV40_v40LightningBakedvae.safetensors
RealVisXLV40.safetensors
realvisxlV40_v40LightningBakedvae.safetensors
realvisxlV40_v40LightningBakedvae.safetensors
base.safetensors
realvisxlV40_v40LightningBakedvae.safetensors
realvisxlV40_v40LightningBakedvae.safetensors
realvisxlV40_v40LightningBakedvae.safetensors
RealVisXL_V4.0_Lightning.safetensors
realvisxlV40_v40LightningBakedvae.safetensors
realvisxl_light_v4.safetensors
realvisxlV40_v40LightningBakedvae.safetensors