
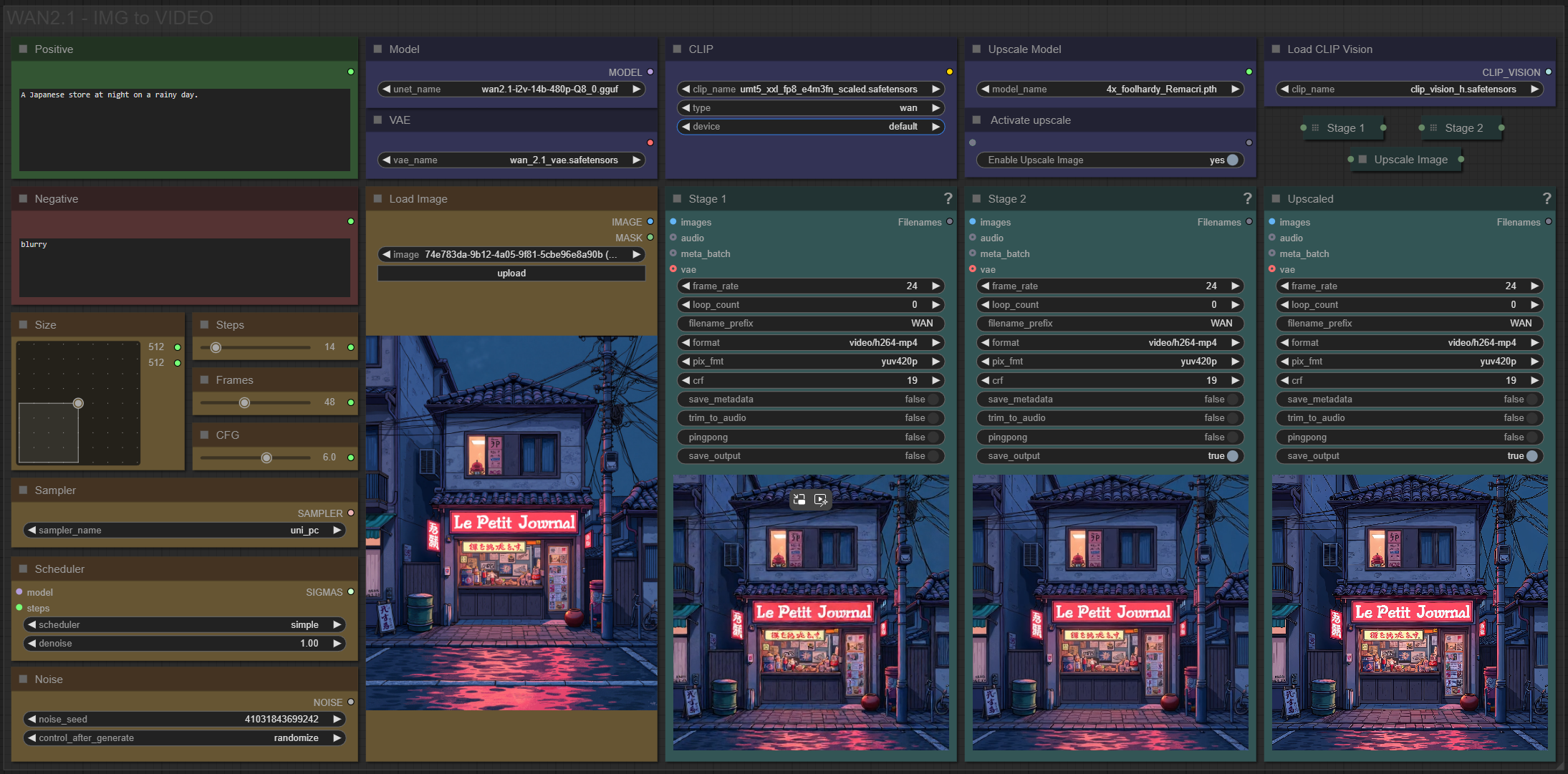
✨ WAN2.1 — Image to video — Simple Workflow
A clean, all-in-one WAN image-to-video workflow built entirely with the UmeAiRT Toolkit for ComfyUI.
Only 12 nodes. No spaghetti wires. Just load your model, write your prompt, and hit generate.
⚠️ IMPORTANT — Nodes 2.0 Required
This workflow is built for the Nodes 2.0 (Vue) interface of ComfyUI. If you don't enable it, the workflow may have display problems.
How to activate Nodes 2.0:
Open ComfyUI
Go to Settings (⚙️ icon, bottom-left)
Find "Use Nodes V2 (Vue)" and toggle it ON
Refresh the page
Load the workflow
If you prefer the classic interface, check out my Legacy version of this workflow instead (link).
🎯 Features
Text-to-video generation
Automatic download of models in auto version
Built-in SeedVR2 upscaler — high-quality tiled upscaling (toggleable on/off) Slower than a classic upscaler, but significantly better quality
Full metadata embedding — your images are saved with all generation parameters, ready for online publishing and remixing
3 LoRA slots — with individual on/off toggles and strength control and you can connect as many other lora modules to each other for as many LoRA as you want.
📦 Custom Node Required
Only one custom node to install:
Install via ComfyUI Manager (search "UmeAiRT") or use the UmeAiRT Auto-Installer.
The Toolkit packages everything internally — upscaler, face detailer, metadata saver. No other custom nodes needed.
📂 Files you need (in manual version)
For base version
I2V Model : 480p or 720p
In models/diffusion_models
For GGUF version
I2V Quant Model :
- 720p : Q8, Q5, Q3
- 480p : Q8, Q5, Q3
In models/unet
Common files :
CLIP: umt5_xxl_fp8_e4m3fn_scaled.safetensors
in models/clip
CLIP-VISION: clip_vision_h.safetensors
in models/clip_vision
VAE: wan_2.1_vae.safetensors
in models/vae
Speed LoRA: 480p, 720p
in models/loras
ANY upscale model:
Realistic : RealESRGAN_x4plus.pth
Anime : RealESRGAN_x4plus_anime_6B.pth
in models/upscale_models
Description
Base version
FAQ
Comments (34)
This is working, but my outputs for i2v get kinda "flashy" the lighting changes significantly throughout, there's something wrong but can't quite figure it out
Try a higher step count if you haven't already, I was getting the same with a until I boosted the step count to at least 14 and ideally 20+ motion and rationality also improved massively as you get higher. I've also seen better results with the Res_Multistep sampler
My result is often "flashy", I try to increase the steps to 20+ and to switch to the Res_Multistep sampler but without better results
@Allerias I personally use 30 step and you can see that the 20+ videos I've posted with this workflow don't have this problem.
@UmeAiRT I will try with 30 step. I think it depend of the primary image. In any case thanks for this workflow, it's the most functional I've been able to try. I'll go look at your other creations :)
@Allerias I have do some test with 20 to 30 step and yes i think the base image is important. If you find something for best result ask me ^^
Wonderful scheme, thank you. But the error keeps appearing:
Unexpected architecture type in GGUF file, expected one of flux, sd1, sdxl, t5encoder but got 'wan'
Please tell me how to fix it?
you need to update ComfyUI-GGUF custom node
Thanx, now it work, great.
I am able to load the workflow but nothing appears, no nodes nothing, it just shows blank canvas
Just use "refocus" shortcut at the bottom right of comfyui
@UmeAiRT Yep! It works! Thanks. And, by the way, awesome workflow. Simple, to the point and great results.
I have tried all the available WAN2.1 workflows. Yours is the only one that is simple, well laid out to learn from, and is also faster than many of the other's that claim to be fast. It worked right out of the box and was a breeze to modify as techniques progress. Great work, you've got a new fan.
Thank you for your support
Thank you so much, working and I'm testing now
Silly question. How do you get more than 1 second?
Second = Frame / frame per second.
So if you set frame to 48 and frame rate to 24 you have a 2s video.
@UmeAiRT Thanks! I couldn't find the Frames control
@drfronkonstinmd https://i.ibb.co/XfnqW0dv/Screenshot-2025-03-05-073326.png
{kind=link}
This is a great workflow! I'm enjoying it so far.
Has been the easiest to understand and most intuitive I2V workflow for WAN i've seen on her so far!
I have changed the properties for the "Step"-Setting on the Frames selector to always do jumps of 12 which really helps to make videos half a second longer each jump of the frames dial.
Only other thing i'd wish for is maybe the implementation of TeaCache as it reduces the amount of time to generate a video by a lot.
I could probably switch to a lower VRAM model as i'm using the one you've recommended for 24GB right now but i'm really liking the quality of it!
Also: I've tried the workflow from a clean installation with just the custom nodes you've mentioned and you've missed the WanVideoWrapper one as you probably assumed people who'd use WAN have it pre-installed :D
(And having comfyui on the newest version was a must too)
Thanks for your feedback. I'll try to find time to add TeaCache but the latest version of ComfyUI "broke" all my node layouts.
@UmeAiRT That'd be awesome! I've tried other users implementation of TeaCache but they're mostly for 12GB VRAM GPU's and use pruned models that have a way lower quality output :/
I've had the same issue with the recent comfyui update but i've fixed it by starting it with a lower frontend version. I've just attached "--front-end-version Comfy-Org/[email protected]" to my starting script like so:
"python main.py --front-end-version Comfy-Org/[email protected]"
maybe that'll help you too 🫡♥️
@UmeAiRT i have implemented teacache, at least the comfyui native node as the new kijai node requires a different sampler node and i didn't want to temper too much with the original workflow, and sageattn to reduce the generation speed to half of what it took before! Great workflow, thank you again :)
Here's an image with the workflow included:
@vslinx Thank you very much for your help. I had a lot of work this week but this weekend I will update my workflow with these new features.
@UmeAiRT No need to thank me, there's probably still a lot of room for improvement since i've only implemented the native comfy TeaCache ^^
Your current one is also more compatible since not many people have triton and sageattn running on windows, but even with disabling the sageattn again the speed increase should be somewhere around ~30%.
Thank you again for your workflow 🥳🤝
still showing"When loading the graph, the following node types were not found:"
you also have to install the WanVideoWrapper custom node https://github.com/kijai/ComfyUI-WanVideoWrapper
and have comfyui on the newest version :)
Very nice workflow... I wish the upscale didnt always mess up the eyes. But otherwise, great results. And like how you set the width/height.
Do you know how to modify the workflow,, in order to output the "last" image in the video? So we can do a continuation on the next run.
WanImageToVideo (In group node 'workflow>Stage 1') not found, and it's not registered in ComfyUI custom nodes. Where do I get this?
Check if you have all this customs nodes, close and open again the workflow :
ComfyUI-GGUF
ComfyUI-KJNodes
ComfyUI-Impact-Pack
ComfyUI-VideoHelperSuite
ComfyUI-Frame-Interpolation
ComfyUI-Custom-Scripts
rgthree-comfy
ComfyUI-WanVideoWrapper
had to update comfyui. It's a node that is included in ComyUI base packages, if you're using git, make sure to pull the latest.
Still testing it, but it works beautifully. Very consistent, the hands are handled well and the upscaler does its work. I was wondering one thing though. In the first step, you can kinda see what the final motion is going to look like. Is there any way to generate a bunch of those, see what you like the most, and then complete the whole process (steps 2 and 3) only for the ones that you choose? That would really help because you wouldn't be "wasting" time with results you don't really like.
After seeing the preview in the first panel if I don't like it I just click cancel to save the time.