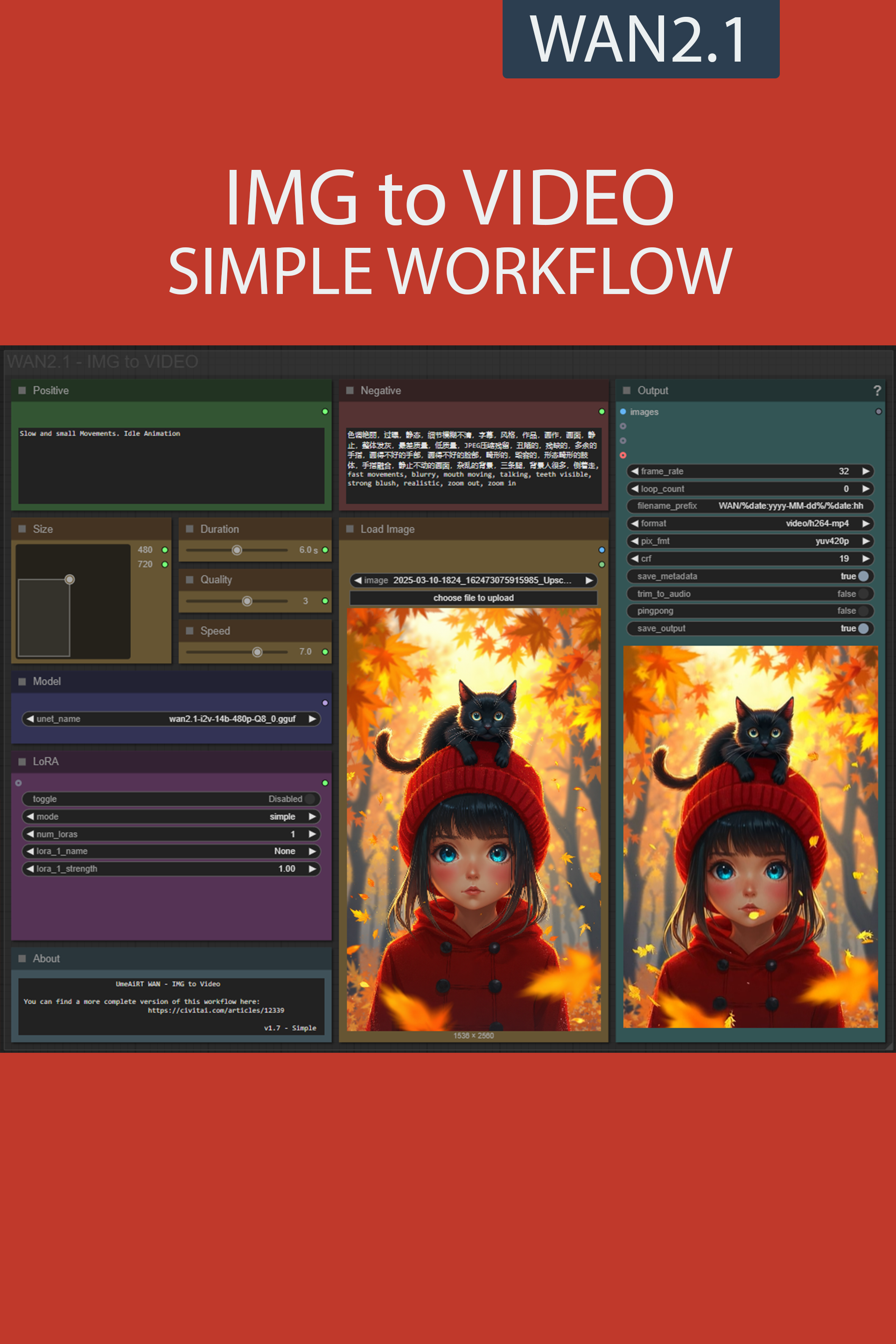
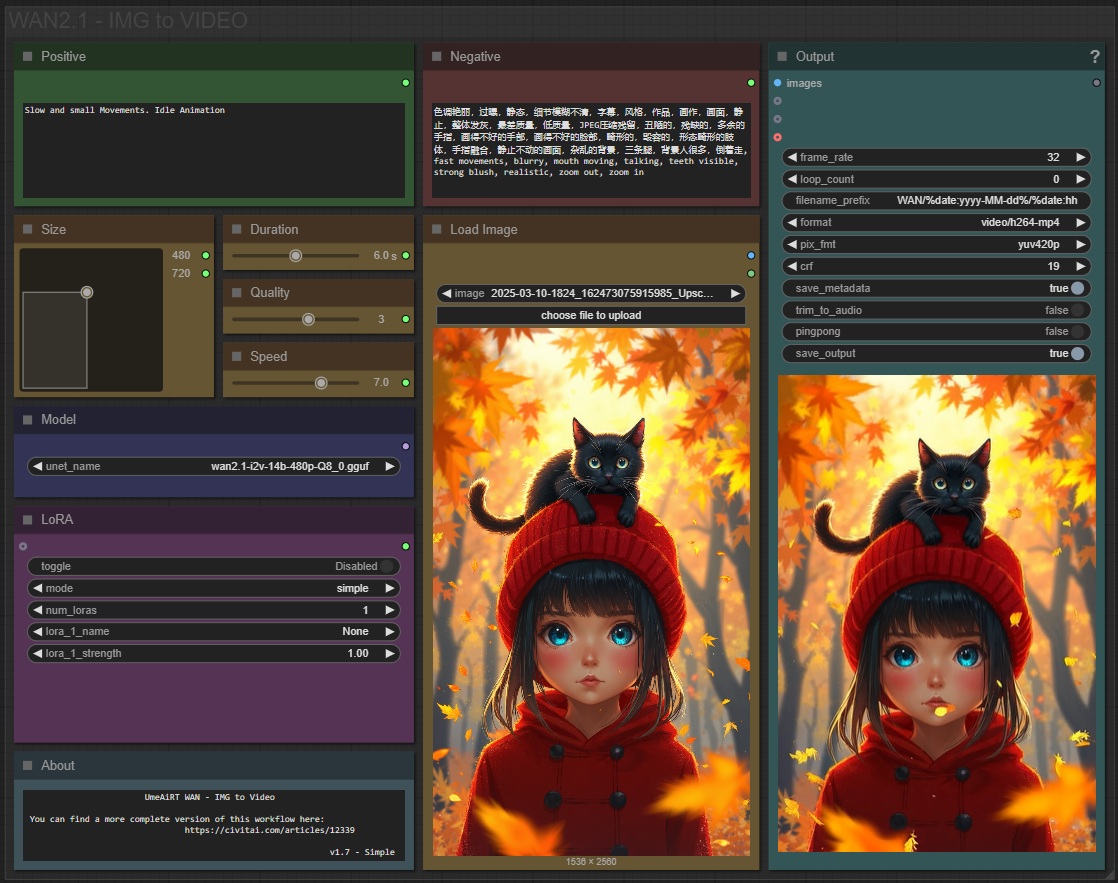
✨ WAN2.1 — Image to video — Simple Workflow
A clean, all-in-one WAN image-to-video workflow built entirely with the UmeAiRT Toolkit for ComfyUI.
Only 12 nodes. No spaghetti wires. Just load your model, write your prompt, and hit generate.
⚠️ IMPORTANT — Nodes 2.0 Required
This workflow is built for the Nodes 2.0 (Vue) interface of ComfyUI. If you don't enable it, the workflow may have display problems.
How to activate Nodes 2.0:
Open ComfyUI
Go to Settings (⚙️ icon, bottom-left)
Find "Use Nodes V2 (Vue)" and toggle it ON
Refresh the page
Load the workflow
If you prefer the classic interface, check out my Legacy version of this workflow instead (link).
🎯 Features
Text-to-video generation
Automatic download of models in auto version
Built-in SeedVR2 upscaler — high-quality tiled upscaling (toggleable on/off) Slower than a classic upscaler, but significantly better quality
Full metadata embedding — your images are saved with all generation parameters, ready for online publishing and remixing
3 LoRA slots — with individual on/off toggles and strength control and you can connect as many other lora modules to each other for as many LoRA as you want.
📦 Custom Node Required
Only one custom node to install:
Install via ComfyUI Manager (search "UmeAiRT") or use the UmeAiRT Auto-Installer.
The Toolkit packages everything internally — upscaler, face detailer, metadata saver. No other custom nodes needed.
📂 Files you need (in manual version)
For base version
I2V Model : 480p or 720p
In models/diffusion_models
For GGUF version
I2V Quant Model :
- 720p : Q8, Q5, Q3
- 480p : Q8, Q5, Q3
In models/unet
Common files :
CLIP: umt5_xxl_fp8_e4m3fn_scaled.safetensors
in models/clip
CLIP-VISION: clip_vision_h.safetensors
in models/clip_vision
VAE: wan_2.1_vae.safetensors
in models/vae
Speed LoRA: 480p, 720p
in models/loras
ANY upscale model:
Realistic : RealESRGAN_x4plus.pth
Anime : RealESRGAN_x4plus_anime_6B.pth
in models/upscale_models
Description
New, simplified version.
No new features, just an easier-to-use interface for less experienced users.
FAQ
Comments (27)
或许你应该使用强力lora加载器,他更方便
PowerLora 要求放置对 WAN2.1 造成问题的剪辑
Dumbass me was gonna make a comment complaining the LORA's are not working on the version 1.7
Turns out I forgot the toggle button to turn them on...
same here :0
whats the difference between gguf model and safetensors regular wan model?
I don't fully understand the technical side, but as far as I can understand it GGUF is better for CPU and GPU acceleration with quantized models. I assume that means Sage Attention works well with it, and it works well with LLM.
Safetensor is safer than ckpt and is faster loading but doesn't have the other benefits that GGUF has as far as I can tell.
There is probably much more to it but that is my low level basic understanding.
@synalon973 Thanks for the explanation!
the umt5_xxl file should be placed in clip? other guides I've seen says to put it in text_encoders?
How to fix blurry hands? Tried all settings, all good except blurry hands
I use detailed hands, detailed fingers, defined hands, defined fingers in the postive prompts. It helps a bit.
first workflow I tried for Wan, and honestly, I'm shocked at how good it is for I2V at least, hunyan shits the bed at that department. THE FUTURE IS HERE BOIS
Bro this is great. Could you add workflow with more loras, like 7 or more :) I dont know how to connect this pasta to add more.
Thanks for all your shares of work flows and tips.
Works great, On a 4070 12GB + 32GB, it took 438 secs to generate a decent 720-ish upscaled clip.
* I2V, 480P, Q4_K_S, sage attention and tea cache on.
* 13 FPS, interpolate to 26 FPS.
* 46 frames, 3.5 secs clip.
* 14 steps, uni_pc.
* Base 405X720 (9:16), Upscale 1.8X, bicubic.
Thanks for your feedback
Really been enjoying both the complex and simple versions of this workflow. Not sure if it's because I run all of these local rather than using a VM, but your setups have not only been the most consistent to use/run, they have also been simple to setup and even get running in the first place.
That said, I did have a though/idea I wanted to throw at you so you could tell me whether it's possible or not...
Since you have the "save last frame" feature in your complex workflow, would it be possible to setup parameters in which you could say, set a "video count" threshold where depending on how many you were intending to make, you could set a custom iteration loop where the last frame of the previously generated video gets immediately fed into a second run of the workflow?
I hope you'll excuse my ignorance if this is already a thing or can't be done. I have EXTEMELY limited knowledge of how all this works but based on playing around with a couple of things, it felt reasonable to assume that something like this could be possible. Curious to hear your thoughts on it.
Thank you!
I've never implemented a loop of this type before, so I'd have to do some research. For the moment, I've already published another workflow that automatically extends a video, maybe that could help you.
Mine errors out loading the Florence 2 prompt gen model, despite it being installed in my LLM folder. Any ideas why? Thanks!
You have the solution in the patchnote:
Known issue :
Florence dont works with some versions of transformers.
To solve that :
Navigate to your ComfyUI Portable directory (if you are using it)
Run .\python_embeded\python.exe -m pip install transformers==4.49.0 --upgrade
@UmeAiRT Thanks for this and apologies for not seeing the patchnote. I tried this but still get the same error. Will keep using V1.6 for now thanks!
Does anyone know a good way to minimise the flash at the beginning of the clip? I can't seem to prompt mine out but the sample clips don't seem to have that. Thanks.
Changing sampler and/or scheduler may help as will lowering your lora strength.
Hello, is there any way not to eat up all RAM while upscaling the video? It used about 30+GB of RAM when I tried to create a 512*512, 120 frames video.
For long videos I recommend doing the upscale separately with this workflow: Upscaler simple workflow WAN2.1 - v1.0 | Wan Video Workflows | Civitai
@UmeAiRT many thanks!