
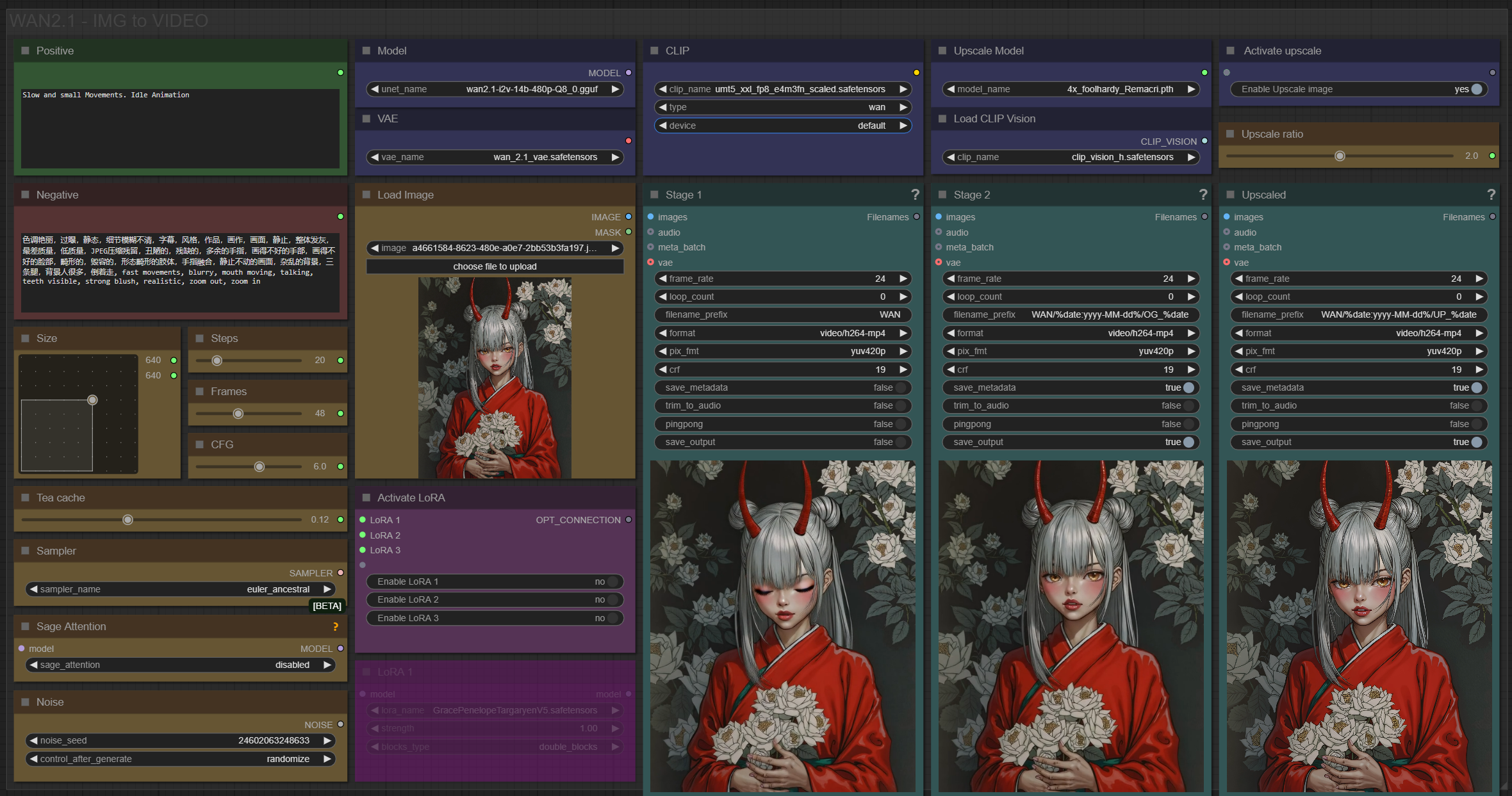
✨ WAN2.1 — Image to video — Simple Workflow
A clean, all-in-one WAN image-to-video workflow built entirely with the UmeAiRT Toolkit for ComfyUI.
Only 12 nodes. No spaghetti wires. Just load your model, write your prompt, and hit generate.
⚠️ IMPORTANT — Nodes 2.0 Required
This workflow is built for the Nodes 2.0 (Vue) interface of ComfyUI. If you don't enable it, the workflow may have display problems.
How to activate Nodes 2.0:
Open ComfyUI
Go to Settings (⚙️ icon, bottom-left)
Find "Use Nodes V2 (Vue)" and toggle it ON
Refresh the page
Load the workflow
If you prefer the classic interface, check out my Legacy version of this workflow instead (link).
🎯 Features
Text-to-video generation
Automatic download of models in auto version
Built-in SeedVR2 upscaler — high-quality tiled upscaling (toggleable on/off) Slower than a classic upscaler, but significantly better quality
Full metadata embedding — your images are saved with all generation parameters, ready for online publishing and remixing
3 LoRA slots — with individual on/off toggles and strength control and you can connect as many other lora modules to each other for as many LoRA as you want.
📦 Custom Node Required
Only one custom node to install:
Install via ComfyUI Manager (search "UmeAiRT") or use the UmeAiRT Auto-Installer.
The Toolkit packages everything internally — upscaler, face detailer, metadata saver. No other custom nodes needed.
📂 Files you need (in manual version)
For base version
I2V Model : 480p or 720p
In models/diffusion_models
For GGUF version
I2V Quant Model :
- 720p : Q8, Q5, Q3
- 480p : Q8, Q5, Q3
In models/unet
Common files :
CLIP: umt5_xxl_fp8_e4m3fn_scaled.safetensors
in models/clip
CLIP-VISION: clip_vision_h.safetensors
in models/clip_vision
VAE: wan_2.1_vae.safetensors
in models/vae
Speed LoRA: 480p, 720p
in models/loras
ANY upscale model:
Realistic : RealESRGAN_x4plus.pth
Anime : RealESRGAN_x4plus_anime_6B.pth
in models/upscale_models
Description
Bugfix : path for windows
Update : New teacache node, UI adjustment
Testing : No group node to maximise missing node detection
FAQ
Comments (35)
I'm quite curious if it's technically possible to create the I2V workflow with start and end frame, like the Kling does?
In the new 1.3 version i added an option to save the last frames and thus allow you to create a video that would follow another
@UmeAiRT No, I mean... All Wan workflows have only one "Load image" box - the first frame. But in the variant I mentioned there are TWO "Load image" boxes - one for the first frame and one for the last frame. And then AI tries to generate the frames between these two images. Unless this is technically impossible due to the model's restrictions... Kling AI has this thing, but... It's not local, it's paid, and it's censored.
Why do you have the TeaCache disabled by default. Is it not helpful in this workflow?
Teacache default setting in this workflow is 0.12 not disabled so i dont understand
@UmeAiRT Hmm.. when I downloaded the workflow teacache was (BYPASSSED) . But when I enable it.. I am really not noticing any improvement in speed. Its the same speed whether I enable or disable. This doesnt make sense to me.
I thought I would find the complete project. Instead I found a blank page :(
Just click on the square at the bottom right of comfyui to refocus the workflow
@UmeAiRT ok,thx a lot :)
@UmeAiRT anyway, how do you increase the video length and quality?
@ApexThunder_Ai For video lenth just add more frame in the frame selector, with default save setting 24fps -> 1 second. For quality Q8 model are better but need more VRAM and take more time
@UmeAiRT so i have to increase fps where it says: frame rate to all 3 windows?
@ApexThunder_Ai No just increase yellow frame slider : video time is Frames (in yellow slider) divide by FPS in Stage node. 48 frames with 24 frame_rate -> 2 second video
@UmeAiRT unfortunately it crashes often. I have a rtx 4070 oc 12 gb. which checkpoint can you recommend for both 480p and 720p?
@ApexThunder_Ai I haven't tested this card so I can only guess: with this graphics card I don't think 720p is really achievable. I think the best is to start with the Q4 and if it's not too long try the Q5. The new 1.3 version uses less VRAM for upscaling which should already help you.
@UmeAiRT so which one should i download:
wan2.1-i2v-14b-480p-Q5_0.gguf
wan2.1-i2v-14b-480p-Q5_1.gguf
wan2.1-i2v-14b-480p-Q5_K_M.gguf
wan2.1-i2v-14b-480p-Q5_K_S.gguf
????
@ApexThunder_Ai try Q5_K_S
@UmeAiRT ok,thx :)
I love both this workflow and your text to video workflow, they have been really helpful.
I'm trying to figure out how to add something like reactor so I can choose the face and a way to get the last frame so I can lengthen the videos.
Any suggestions would be very helpful as I'm still struggling to learn Comfyui
First option: You can simply add the node "preview image" to the decode Stage 1 or Stage 2 output and choose one of the images manually then "save as".
Second Option: Install the comfyui-impact-pack - there is a node "Image Receiver" which can read the Last Frame Image if you link image to the source from the node "Image to Video". Set link_id to 1000 to get the last one.
@theorigin79 Thank you for the help, do you know how to add interpolation as well to help increase the smoothness and length?
@synalon973 I'm working on a workflow update that includes interpolation, i think i publish it this weekend
@UmeAiRT That sounds great, I'm looking forward to it already.
@synalon973 I just uploaded it, don't hesitate to give me feedback for corrections.
@UmeAiRT I'll give it a try right away.
@UmeAiRT I'm generating an image now I'll upload it shortly, I'm wondering if you will add interpolation to your text to video workflow as well?
@synalon973 Yes I do it tomorow
@UmeAiRT I'm looking forward to that one as well.
@UmeAiRT It still works very well, I had to reduce the resolution and the upscale to 1.5 because my GFX card kept running out of memory (RTX 4080) but thats an issue with my hardware not the workflow.
I'm not sure if I should use sage attention or not, and I have no idea if I should change the Teacache value at all so if you can add a description about those it would be helpful.
When I turned off upscale the node had a no frames issue before interpolation, I'm not sure if it would have worked anyway because my card ran out of memory and I haven't tested that at a lower resolution because I haven't needed to turn upscale off again.
The faces and hands seem to work very well even with full body video, are you using a face detailer and hand detailer in the workflow somewhere?
I'm not sure how it would work but maybe adding an option for reactor/deepfuze or something similar to make it easier to add a face into the video, but its already outstanding as it is in my opinion.
@synalon973
WanVideo model to use TeaCache. Speeds up inference by caching the output and applying it instead of doing the step. Best results are achieved by choosing the appropriate coefficients for the model. Early steps should never be skipped, with too aggressive values this can happen and the motion suffers. Starting later can help with that too. When NOT using coefficients, the threshold value should be about 10 times smaller than the value used with coefficients.
Official recommended values https://github.com/ali-vilab/TeaCache/tree/main/TeaCache4Wan2.1:
+-------------------+--------+---------+--------+
| Model | Low | Medium | High |
+-------------------+--------+---------+--------+
| Wan2.1 t2v 1.3B | 0.05 | 0.07 | 0.08 |
| Wan2.1 t2v 14B | 0.14 | 0.15 | 0.20 |
| Wan2.1 i2v 480P | 0.13 | 0.19 | 0.26 |
| Wan2.1 i2v 720P | 0.18 | 0.20 | 0.30 |
+-------------------+--------+---------+--------+'
btw. i am using also an RTX 4080 (16GB) and i using the 4Q_K_M model pretty consistently. (32GB RAM), but higher resolutions are also an problem for me. TeaCache is very noticable! It reduces your generation time by almost half. Use the 0.13 setting for pretty good quality.
@theorigin79 That will be a big help thank you, I knew it helped render faster but didn't understand how or why and had no idea at all about the settings.
@synalon973 Thanks for your feedback, i have updated the guide with new nodes : Step-by-Step Guide Series: ComfyUI - IMG to VIDEO | Civitai
With the workflow 1.2 all my upscaled saved files are wrong. VLC can't read them it's just a black screen. Same thing if i try to read the files on another computer.
The stage 2 files are good.
I don't have this issue with the workflow 1.1
I have no problem. I tried adding an upscale setting on this version, maybe it's a problem in some cases. I'll do more testing and make a fix.
I also have issue with upscaling. There is video corruption even at 1.5 scaling. Something is off in the video saving.