
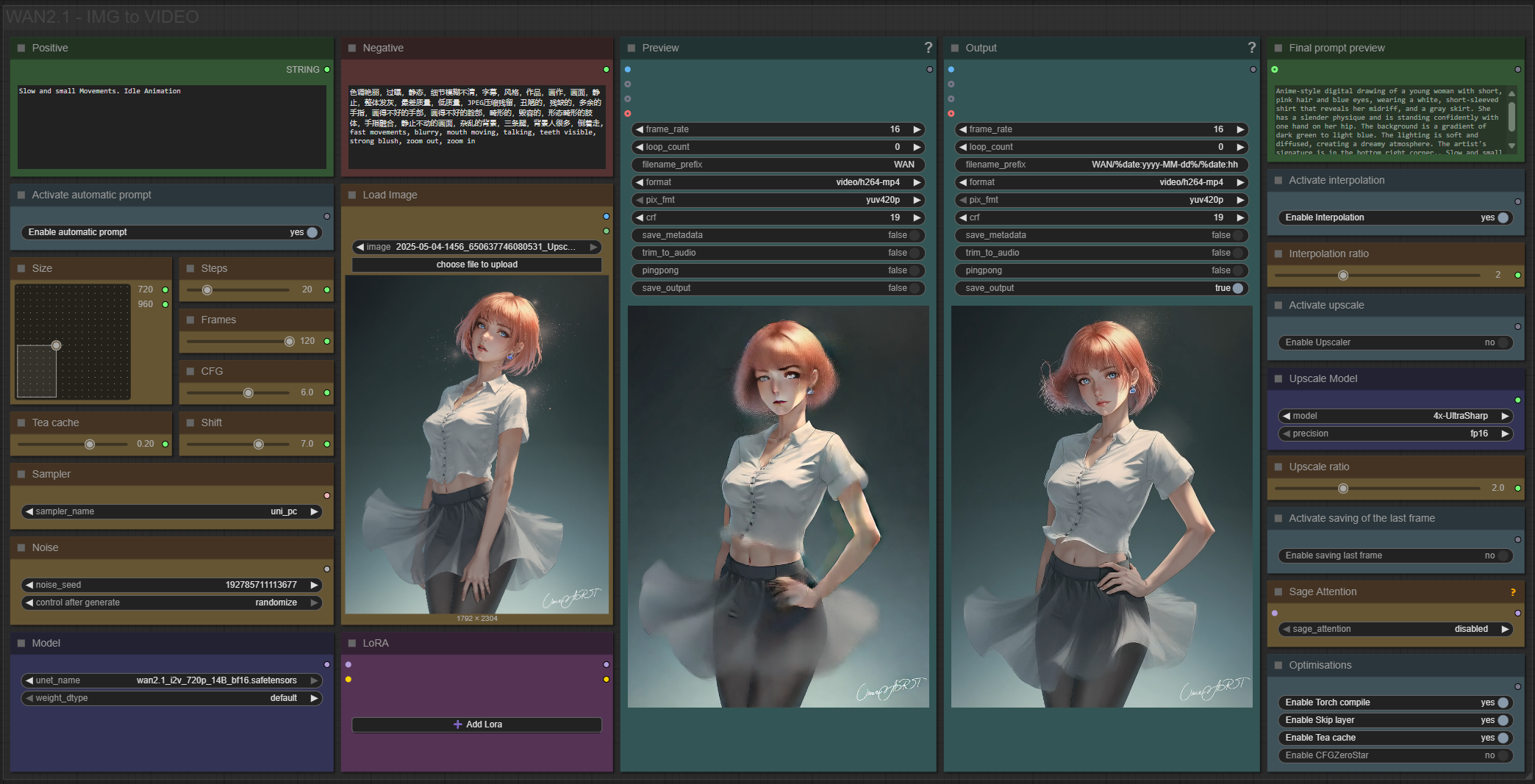
✨ WAN2.1 — Image to video — Simple Workflow
A clean, all-in-one WAN image-to-video workflow built entirely with the UmeAiRT Toolkit for ComfyUI.
Only 12 nodes. No spaghetti wires. Just load your model, write your prompt, and hit generate.
⚠️ IMPORTANT — Nodes 2.0 Required
This workflow is built for the Nodes 2.0 (Vue) interface of ComfyUI. If you don't enable it, the workflow may have display problems.
How to activate Nodes 2.0:
Open ComfyUI
Go to Settings (⚙️ icon, bottom-left)
Find "Use Nodes V2 (Vue)" and toggle it ON
Refresh the page
Load the workflow
If you prefer the classic interface, check out my Legacy version of this workflow instead (link).
🎯 Features
Text-to-video generation
Automatic download of models in auto version
Built-in SeedVR2 upscaler — high-quality tiled upscaling (toggleable on/off) Slower than a classic upscaler, but significantly better quality
Full metadata embedding — your images are saved with all generation parameters, ready for online publishing and remixing
3 LoRA slots — with individual on/off toggles and strength control and you can connect as many other lora modules to each other for as many LoRA as you want.
📦 Custom Node Required
Only one custom node to install:
Install via ComfyUI Manager (search "UmeAiRT") or use the UmeAiRT Auto-Installer.
The Toolkit packages everything internally — upscaler, face detailer, metadata saver. No other custom nodes needed.
📂 Files you need (in manual version)
For base version
I2V Model : 480p or 720p
In models/diffusion_models
For GGUF version
I2V Quant Model :
- 720p : Q8, Q5, Q3
- 480p : Q8, Q5, Q3
In models/unet
Common files :
CLIP: umt5_xxl_fp8_e4m3fn_scaled.safetensors
in models/clip
CLIP-VISION: clip_vision_h.safetensors
in models/clip_vision
VAE: wan_2.1_vae.safetensors
in models/vae
Speed LoRA: 480p, 720p
in models/loras
ANY upscale model:
Realistic : RealESRGAN_x4plus.pth
Anime : RealESRGAN_x4plus_anime_6B.pth
in models/upscale_models
Description
What's new? :
ComfyUi 0.3.31 compatibility fix,
new color match node,
MultiGPU loader in a separate version.
FAQ
Comments (86)
Isn't it better to use tiled vae node instead of the normal one?
I tested it and I think it's working well, unless I didn't test it enough.
where do i get the "tiled vae node"?
were do i find the b gguf models?!?!
Which upscaler are people using? All the ones I've tried were disappointing, always blurry results.
RealESRGAN_x4plus
Any idea what happened, just this week it seems that comfy is using extreme amounts of memory both vram and regular ram and hanging up when upscaler is used. Is this something that windows messed up ir nvidia or something else, because nvidia downgrade didn`t help.
I'm noticing the same. My generations take SIGNIFICANTLY longer with this workflow (if they are able to run at all). I'm thinking it has something to do with Sage but I'm honestly not sure.
@Longbottumnsfw yeah, starting to get the same feeling now, also it might be to do with tea cache also. Also, this escalates to freezes when upscaling in particular, even though the system memory is overall extremely overloaded.
I had one 81 frame render take 5 hrs, 4080 super, no upscale
@Dradical So it seems like this is an ongoing issue. No improvement over here. Same with my other workflows.
You mean that the workflow works "correctly" and in the last few days it has become much slower?
@ufik254 When you have problems with the upscaler, often due to a lack of VRAM, it is recommended to do it in the dedicated workflow and not in the same process as the video generation. This allows you to have all your resources available and greatly reduces problems.
@UmeAiRT This is not the issue, it worked before (same old story I know), but after some changes to something it doesn't. I was just hoping somebody would have encountered something similar as this seems to be in my case only related to upscale.
@ufik254 I used the tensorrt upscaler because it was much faster. Have you tried replacing it with the slower native version?
@UmeAiRT Going back to this, any workflows you can suggest for isolated upscaling? I should be more than ok to separately upscale and be fine.
@UmeAiRT Interesting enough, using a seperate upscaler also floods ram (32gb)
i have a 4090 and have been having bad VRAM issues lately. it's frustrating
Hi, I would like to know when you will release the workflow that supports Wan2.1-Fun-14B-Control-gguf. Thanks a lot.
@UmeAiRT yes thank you very much
Great as always!, Is there a way to modify the backend so the final generation is more faithful to the first preview? For example, I often notice that in the final generation, abrupt movement is smoothed out a lot and doesn't look as "rough" as in the first preview.
the first generation in preview is often half baked, the second generation refines it to be higher quality, if you prefer something with less refinement you could reduce the steps on the second sampler
Im not good with comfy but i have a question:
Is there a straightforward way automate "recursive" generation in this workflow?
So that when a generation is done, the last frame is shown and if one decided that generation was good, one can then select the most recent last as the input for the next segment, without having to browse for it.
This would make generating longer videos a lot smoother.
v2.2 doesnt work with vram 16gb. i used q5k_m gguf. because of OOM. i can use flow2 workflows but yours cant. few weeks ago, i used well your workflows i2v but recent days i cant. i dont know why, but surely all about OOM
Several people say they have this memory issue even though the workflow was working before. I have not yet identified which component was updated or modified to cause this problem.
@UmeAiRT maybe its all about unstable comfyui custom nodes and comfyui core team issue. fortunately, your old version workflow works well, so i can make it anyway :)
I think it might be the comfyui-videohelpersuit int > float change. You got to reconnect "calcul frames" again to "save interpoled" with float. I have tested this now 4 times. Usually after the first generation, going into second, it already bugged out. 🙏 hopefully that's it.
But I'm also using Q4_K_S right now. I'll test later if higher quality will still stay in VRAM requirements, now that this bug is gone.
same issue. I used to be able to use k8 witrhout OOM, now I have to use K6. 3090
I'm also using a 16GB GPU and get VRAM errors as well!
failed, cant run on zluda
I have never used Zluda, do you have any documentation on the subject?
视频的颜色会和原图有明显的差异变化,比如整体变暗或者皮肤变红,这是什么问题,有解决办法吗
This is wonderful. Thank you. First video workflow that has worked without major troubleshooting, and it is intuitively laid out and easy to tune each parameter while not losing track of changes. My only issue is LoRas not showing up in the power loader. I can't figure out what is making some show up and others not. Also, there are TONS of LoRas from other models in the list that I want to exclude. If anyone knows how the rules are set for what shows up, I'd love to know.
For LoRA you can create sub folder to make it easier to select
@UmeAiRT Actually I just appended WAN_ onto every .safetensor that didn't start with it already. Added description for those brilliant ones that are ambiguously named. Now not only do they all show up, I can actually tell which ones are usable in WAN and they're all nicely sorted together in the list (100+ LoRas makes for a tedious search). Probably should have tried that before commenting, as it was in my mind to do so. Thanks for the input though. Always appreciated.
for some reason the base one always produce me black videos. The gguf one is fine no issue at all. I have a 5090. I think the problem is related to one node I have updated but can't figure out which one is it.
I've been using the base bf16 version today without any problems on an L40S. I'll try to reduce the number of custom nodes to maximize compatibility now that many of the features are implemented natively in ComfyUI.
@UmeAiRT it's kinda crazy I got one generation working fine, I just changed input img and prompt and again started to produce only black videos. Btw you are my GOAT!
@UmeAiRT I'm also facing the black video problem. How do i fix it?
@AbsoluteAnime On 2.2 gguf? Is your comfyui up to date?
@UmeAiRT I have everthing up to date, the gguf works with no issue every time, the base sometimes works sometimes not. Still I didn't figure out the problem.
@UmeAiRT yes its on gguf and my comfyui is up to date, but i disable torch compile since its not working for me.
'DaViT' object has no attribute '_initialize_weights'
I'm using version 2.2 complete. I don't know what I'm doing wrong, but the upscale option doesn't works for me. I already turned on the option with upscale ratio of 2, using Ultrasharp first and then RealERSGAN, but the file is not there, only the OG file exist. Anyway, thanks for this workflow, really impressive work.
Have you activated interpolation? Since it's located before upscale, if you disable it, upscale won't work.
Thank you for the reply. So that's why it doesn't work. Haven't tried it with interpolation tho, since I want to make I2V about anime with 16fps. Anyway, is there a workaround so that it works without interpolation turned on? Though I have a separate workflow for upscaling, but it's so much convenient to just do it all at once in your workflow.
EDIT: Nvm, I just thought that I could just using 8fps with interpolation turned on. That'll work right?
It just fails without even giving me an error. I'm just immediately sent back to idle.
Same here
Super cool. I tried switching to use WanFirstLastFrameToVideo but couldn't get anything other than static (though I had TeaCache etc enabled); any ideas what'd need to change to make this work?
You want to say this workflow https://civitai.com/models/1389820 or you change node in the IMGtoVIDEO workflow?
@UmeAiRT Ah, I didn't see that other workflow - I just changed it here. Comfy core now has WanFirstLastFrameToVideo, same as the WanImageToVideo node in this workflow; but I'm having a hard time getting it to actually work here.
@kurokuro I didn't see that he added it to the native node. I'll modify my workflow to use it.
Hey, can anyone tell me how to use this workflow on rented vrams like vast.ai?
@UmeAiRT In theory it should work the same way. Thanks, I'll give it a try!
Sampler Stage 1 gets stuck on 0%, what am I doing wrong?
Have you enabled TorchCompile? This makes the first frame very long, it is recommended to do a first generation with a lower resolution or/and a shorter video to avoid an extremely long loading time.
@UmeAiRT I did, and left for a while and 2 hours later it was still 0% so I assumed it was just stuck.
Just tried without TorchCompile and it works, thanks!
@UmeAiRT Hmm now I get just black video :/
@DoctorAculaMD Torchcompile dont work and blackvideo ... What graphics card are you using? Can you try a clean comfyui up to date? you can use my script : https://civitai.com/models/1309415
@UmeAiRT I switched to gguf and now everything works. Thanks :-)
@DoctorAculaMD I test GGUF on 4080 and base (bf16) on L40S. Wich version dont work?
@UmeAiRT GGUF worked, it's the basic that didn't
My video had zero motion, no idea what went wrong. I am using the gguf single gpu workflow.
This is usually due to two things:a bad prompt,Teacache too strong.
Can you give me this two parameter?
@UmeAiRT Of course! Teacache: 0.13
Prompt: Anime-style drawing of a cute, busty, purple-haired demon girl with large horns, wearing a light blue crop top and a short white pleated skirt, standing in a dimly lit room with a bed and a lamp in the background. She has a playful, mischievous expression and is wearing black thigh-high stockings. The lighting is soft and warm, creating a cozy atmosphere., The image is a digital illustration featuring an anime-style character with long, flowing purple hair that has subtle pinkish highlights. The character has a neutral expression and is wearing a white, semi-transparent crop top that hangs over her breasts. The background consists of simple, muted tones, possibly a room or a hallway with light-colored walls and a dark floor. The character's skin tone is fair, and there proportions have been exaggerated for aesthetic reasons, with a focus on the bust area. The overall style is smooth and detailed, typical of modern anime or manga illustrations. Slow and small Movements. Idle Animation
Negative prompt: 色调艳丽,过曝,静态,细节模糊不清,字幕,风格,作品,画作,画面,静止,整体发灰,最差质量,低质量,JPEG压缩残留,丑陋的,残缺的,多余的手指,画得不好的手部,画得不好的脸部,畸形的,毁容的,形态畸形的肢体,手指融合,静止不动的画面,杂乱的背景,三条腿,背景人很多,倒着走, fast movements, blurry, mouth moving, talking, teeth visible, strong blush, zoom out, zoom in
I really like this workflow, as well as the T2V one. However something about the interpolation stage 2 is broken. It runs fine the first time but starting the workflow a second time will quickly fill up the VRAM and bloat into the RAM. Over the painful process of many days now I try to find the issue about it. At first I thought it's sageattention, then torch.compile and my latest is that it's happening somewhere when interpolation is active. I've noticed that the custom-scripts node can no longer connect to the videohelpersuit via INT, it expects Float. If you remove it, it will only connect via float again.
Further I'd like to add, that one can use --use-sage-attention and then remove the kjnode sageattention node to reduce the chance for bugs. I assume you did so to allow people to use the wf to work without sageattention. however it currently throws something about not supported CPU 89 error (sorry don't have it at hand right now anymore), which is false positive. but spams console.
Everything else is working and enabled. It's just this VRAM issue requiring to restart comfyui completely as no matter what, no freememory or other, will reset this bug. Only full restart of comfyui'
Edit: I don't want to jinx it but maybe connecting those two nodes with float instead of int finally fixed it. prays
There is a big VRAM issue but I don't think it's interpolation, because I don't use it.
I don't know if it's the install or the workflow, but i only get it using image to video. using k8 gguf I will alwayss run out of ram at any resolution on a 3090, usually on the second or third generation, but using k6 I don't run out of ram no matter how long the video is. I run out of ram no matter what I set the 'virtual ram' too, or whatever it's called, too.
Please add the ability to see a preview. even though it is split up between two stages it would be nice to see immediately whether the movement is correct.
I second this, if it's possible
@theowem Third, all this worklow needs really to be perfect!
I don't know of a technical solution to do this. Do you have a node or workflow that does this?
@UmeAiRT Maybe check this one?
https://github.com/blepping/ComfyUI-bleh
it says batch and video preview so maybe it can help. Also with it you can use the TAESD version of wan2.1 vae.
https://github.com/madebyollin/taehv/tree/main
I tried the TAESD node decode and it is working fine, but idk about the preview thing.
I wish if there were a native solution but it seems otherwise.
@UmeAiRT @jasonafex I looked and you can just open up the Sampler stage 1 node from the backend section. If you have previews enabled it will show the realtime previews, It is the greatest optimization because it allows you to cancel bad generations immediately.
@pocketpie What exactly do I have to do in ComfyUI to open the Sampler stage 1 node from the backend section?
There is a big VRAM issue somewhere, either in your installer or this workflow..
i only get it using image to video. using k8 gguf I will alwayss run out of ram at any resolution on a 3090, usually on the second or third generation, but using k6 I don't run out of ram no matter how long the video is. I run out of ram no matter what I set the 'virtual ram' or whatever it's called, too. infact, I have only started running out of ram since you included that node.
It didn't used to be like this. I've only noticed it aftr a reinstall.
I don't quite understand because this node only exists in a particular version of the workflow, if it causes you problems use the normal version of the workflow. I'm working on fixes you can try the beta here: https://civitai.com/articles/13328
I have the same problems, even on a 5090. memory definitely being leaked somewhere in the process, I have to reboot ComfyUI after the 2 or 3 generation
I'm getting this error:
Sizes of tensors must match except in dimension 1. Expected size 12 but got size 13 for tensor number 1 in the list.
You got the frame count probably wrong. If you want a 5 second video, that's 80 frames, but you need to set the slider to 81 frames or you'll get this error. Not sure about the other values, but since wan is generating at a 16 frames per second you can do the math yourself.
I'm finding it difficult to download the Upscale Model custom modes
you can try the bêta version, no custom node for upscaling
@UmeAiRT the beta version for the upscale model? or the beta version of the workflow? if it's the custom node, how do I work my way around this problem with the workflow since its part of the workflow?
i'm trying to use this but it keeps giving me an error and idk where to install/ fix it can someone please help?
`
RuntimeError: Cannot find a working triton installation. Either the package is not installed or it is too old. More information on installing Triton can be found at https://github.com/openai/triton
Set TORCH_LOGS="+dynamo" and TORCHDYNAMO_VERBOSE=1 for more information
You can suppress this exception and fall back to eager by setting:
import torch._dynamo
torch._dynamo.config.suppress_errors = True`
I recommend to just make a new fresh install of comfyUI using this script
https://civitai.com/models/1309415?modelVersionId=1774372 (Read its desc for Prerequisites)
put it in any folder you recognize and then run it.
after installation it should work fine.
edit: DON'T RUN IT IN ADMIN MODE