
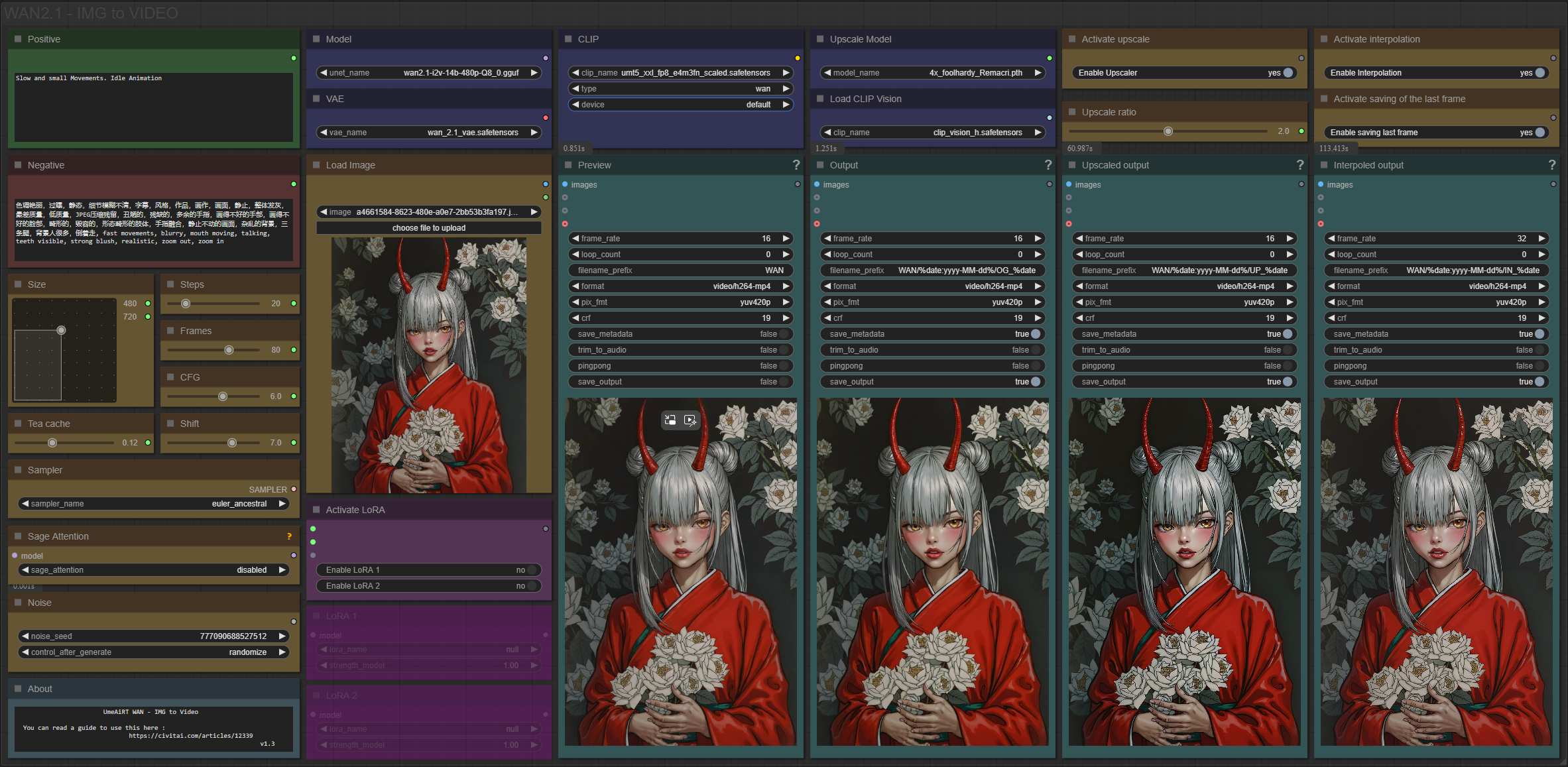
✨ WAN2.1 — Image to video — Simple Workflow
A clean, all-in-one WAN image-to-video workflow built entirely with the UmeAiRT Toolkit for ComfyUI.
Only 12 nodes. No spaghetti wires. Just load your model, write your prompt, and hit generate.
⚠️ IMPORTANT — Nodes 2.0 Required
This workflow is built for the Nodes 2.0 (Vue) interface of ComfyUI. If you don't enable it, the workflow may have display problems.
How to activate Nodes 2.0:
Open ComfyUI
Go to Settings (⚙️ icon, bottom-left)
Find "Use Nodes V2 (Vue)" and toggle it ON
Refresh the page
Load the workflow
If you prefer the classic interface, check out my Legacy version of this workflow instead (link).
🎯 Features
Text-to-video generation
Automatic download of models in auto version
Built-in SeedVR2 upscaler — high-quality tiled upscaling (toggleable on/off) Slower than a classic upscaler, but significantly better quality
Full metadata embedding — your images are saved with all generation parameters, ready for online publishing and remixing
3 LoRA slots — with individual on/off toggles and strength control and you can connect as many other lora modules to each other for as many LoRA as you want.
📦 Custom Node Required
Only one custom node to install:
Install via ComfyUI Manager (search "UmeAiRT") or use the UmeAiRT Auto-Installer.
The Toolkit packages everything internally — upscaler, face detailer, metadata saver. No other custom nodes needed.
📂 Files you need (in manual version)
For base version
I2V Model : 480p or 720p
In models/diffusion_models
For GGUF version
I2V Quant Model :
- 720p : Q8, Q5, Q3
- 480p : Q8, Q5, Q3
In models/unet
Common files :
CLIP: umt5_xxl_fp8_e4m3fn_scaled.safetensors
in models/clip
CLIP-VISION: clip_vision_h.safetensors
in models/clip_vision
VAE: wan_2.1_vae.safetensors
in models/vae
Speed LoRA: 480p, 720p
in models/loras
ANY upscale model:
Realistic : RealESRGAN_x4plus.pth
Anime : RealESRGAN_x4plus_anime_6B.pth
in models/upscale_models
Description
Bugfix: Cleared the cache after generation to limit bugs during upscaling
Added: Frame interpolation, saving the last frame, model shifting
FAQ
Comments (59)
On v1.3 getting a "Invalid argument" error during the upscale stage:
!!! Exception during processing !!! [Errno 22] Invalid argument Traceback (most recent call last): File "e:\ComfyUI\execution.py", line 327, in execute output_data, output_ui, has_subgraph = get_output_data(obj, input_data_all, execution_block_cb=execution_block_cb, pre_execute_cb=pre_execute_cb) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "e:\ComfyUI\execution.py", line 202, in get_output_data return_values = _map_node_over_list(obj, input_data_all, obj.FUNCTION, allow_interrupt=True, execution_block_cb=execution_block_cb, pre_execute_cb=pre_execute_cb) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "e:\ComfyUI\execution.py", line 174, in _map_node_over_list process_inputs(input_dict, i) File "e:\olive\ComfyUI\execution.py", line 163, in process_inputs results.append(getattr(obj, func)(**inputs)) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "E:\ComfyUI\custom_nodes\comfyui-videohelpersuite\videohelpersuite\nodes.py", line 501, in combine_video output_process.send(image) File "E:\ComfyUI\custom_nodes\comfyui-videohelpersuite\videohelpersuite\nodes.py", line 130, in ffmpeg_process proc.stdin.write(frame_data) OSError: [Errno 22] Invalid argumentI HOPE im not the only one that at the middle of the animation there is this "Shimmer" effect
is there a way to get rid of it ?
I would need an image to know for sure but maybe adding artifacts in the negative will help, or to drop the frame length a little I get a few issues if I go to high.
@synalon973 exactly in the middle of the videos the brigthnes/contracts got 100 and then quickly waters down . you can see from the example videos here
@Skynetz Try with 40 frames or less and see if it helps.
Exact same issue. Still trying to fix that. It's quite annoying. It's around the 4s mark.
@synalon973 not a solution.
@null What negative prompt are you using and other settings?
1.3 is working great for me, but is it normal that the frame interpolator is installed and loads, but it has a thin red square around it?
'rel_l1_thresh' error
This is from Tea Cache, three solutions:
- update comfyui and all nodes : https://i.snipboard.io/lEwm7I.jpg
{kind=link}
- uninstall and reinstall the custom node ComfyUI-KJNodes
- bypass the node to disable Tea Cache https://i.snipboard.io/lEwm7I.jpg
when ever i use lora it get stuck at 62% on sampler stage 1. (I m using rtx 4070 12gb vram 32gb ram with q4_0 gguf model). Edit : I have been trying it for 2 hrs now and it loaded this time but its showing it'll take 28 min to generate 512x512 4 sec vid without lora it takes 7 min to generate one idk what is happnin anymore.
I found out why this was happening it was happening cause of the preview if u generate like 2 -3 times the browser takes like 60-80% gpu just to show the preview maybe cause of the 4k res preview stacking on each other or something so i minimized the preview and its fine now
@Thr_u Thanks for you feedback. Yes, if you run out of memory, the preview will consume some, which can cause problems.
@Thr_u It should not be forgotten that each LoRA consumes a little VRAM, if you were already just this could cause a big loss of speed due to a lack of VRAM.
This workflow is seems to be broken due to issues with "WanVideoEnhanceAVideoKJ"
Due to lack of resources, I can't test workflows for at least a week. Is this a problem related to the latest updates?
Hmm? Interesting, I have been using this WF consistently since it came out and it's always worked flawlessly for me. It's my go to Wan WF. Is it saying it's missing? Since I had used a number of other Hunyuan and Wan WFs, this one just loaded up w/o me having to install any missing nodes. I already had sage, triton, torch, etc installed. I am on (portable) ComfyUI: v0.3.26, (2025-03-09), Manager: V3.30.3
@yajukun @UmeAiRT I was having a lot of issues, nuked my whole comfy install and all seems well now. GG
@uggiugi681 Sometimes it's time to start afresh ^^
@uggiugi681 Sorry to hear about that dude. This is what I don't like about Comfy, our installs can be radically different because of OS, Python ver, other existing custom nodes installed(that cause conflicts) , etc. So 1/2 the people are fine and the other 1/2 are borked. I only use Comfy for Hunyuan and Wan video. I use Forge for stills. I try to keep Comfy as clean/simple as possible.
Great workflow but I disabled both teacache nodes as the output is pure trash even with a .12 setting. I don't think the small amount of render time saved is worth it. Anyone else having that issue? Amazing work though and can also add a third lora to the chain though I wish there was a way to add PowerLoraLoader by rgthree but very unlikely I will ever be using 4 loras at once so its more of a want then a need.
Hmm? I heard this from others, that teacache was not worth the time savings due to it's effect on the output. Also, someone else mentioned that it also eats up a lot of VRAM? Maybe I'll try disabling it today and check out the difference. Is there any benefit to using Lora doublebocks for Wan? I get pretty good results with this WF "as is" with x1 or x2 Loras.
Thanks for your feedback. I don't have any problems with Teacache, all the videos I posted use it but there have been a lot of updates recently and some had problems so it may still be the case.
Do you think I should add a button to easily disable teacache?
@UmeAiRT I think most people know they can just right click things and bypass it. Just my opinion.
@UmeAiRT I just tried to bypass it for the Text2Img version and it gives an error for me. EDIT: NM, I had to also bypass ApplyTeaCache on the other side of the WF.
Use sampler : uni_pc
and scheduler : simple
Teacache works great for me. Perhaps issue with model?
@thisisarandomaccount2025 Yeah, I did some test w/ and w/o and to me there isn't much difference in quality so I turned mine back on.
Could be something on my end but I was only getting a minimal improvement in speed and the results had a lot more artifacts etc then without when using same seed and same settings. You could add a bypass for teacache as people may not know they have to disable two different nodes (easy enough to figure out). All in all you did an incredible job and this is by far my favorite Wan workflow to date. I really appreciate the hard work you put into this.
@davedrewhull898 Yeah, I can't say I am getting massive speed gains myself. I am on a 4090 and maybe it has a bigger speed benefit for other GPUs? So maybe it would be a good ideal to have a toggle to turn it on/off in the WF? Also, does anyone know if Wan can use double blocks like the Hunyuan WFs did?
By far the workflow that I found that works the best!
Is there any chance it could be modified to accept three loras, though?
Big thanks, so far the best workflow for me. Its fast and has good results. Im using 720p Q8 and it only uses 84% vram of my 4090. 81 in 220 seconds is way faster then every other workflow I came across so far.
Where did you get the 720p model?
@randmanqt635 here : city96/Wan2.1-I2V-14B-720P-gguf at main
What settings do you use? Uses all vram for me and my ram also spikes up to 64gb when upscaling starts.
@rkleol I currently only have a laptop with a 3070 and 16GB of RAM and I can make 5s videos. (but it takes a lot of time per step and I don't have enough VRAM for interpolation)
What resolution are you selecting? I am curious because I have 3090 and wanted to compare speed.
i can't do a video with a landscape view, it seems not keeping the pictures i imported, it's ok in portrait or square res, did someone have this problem ?
Do you mean the image format changes or is it completely ignored? You must choose the desired format in the "Size" node and select an I2V type model.
@UmeAiRT yes it's ignore the original image, the model is the good one, it works perfectly in a portrait size
@Meandre66 Unfortunately, I can't take any more tests at the moment. Normally, I could next week.
Never mind, just work right now, i did'nt change anything, maybe just a problem with some pictures
Works good on 4070 12GB VRAM + 32 GB RAM. Took 444.99s to generate a 3s clip using Q4 gguf + tea cache + sageattn
Thanks for your feedback.
Is it possible to disable upscale but keep interpolation? I think it stop before interpolation after I disable upscaling.
Thanks
This week I don't have a graphics card to do a test but if you want you can just reconnect the "clean VRAM" node directly to "frame interpolation" and thus completely ignore the upscaling.
{kind=link}
Anyone getting high system ram usage when upscaling starts?
i got same issue. although i have lots of system ram about 64gb, must be failed to generate more than 5 sec with high resolution, which is normally working in other workflow i used before.
@budemrra223 Upscaling is done in three steps: upscaling with a model, applying the ratio, and then saving. Do you know which of these three steps you have a problem with?
@budemrra223 It should be remembered that if you use an upscale model most of them are based on 4x, and my setting only applies after so your graphics card will have to process a set of images 4x larger than the initial one during the process which can consume a lot of vram.
I had to turn off upscale... otherwise the webpage says "it is running out of memory" and my GPU pegs at 99% I personally dont like upscale in the workflow... upscale should be a post production thing. Also it creates the upscaled video, but then media player says "format is invalid" So guys not having good luck with upscale. but I dont care for it in the workflow anyway. The just consumes a lot of time.
@UmeAiRT of course i knew about that trade-offs about upscale, but its quite different with that. because i used well other workflow with same setting, more than 3 sec. also i haven't seen sys ram usage more than 40 gb before, but in yours over 60gb and often stopped because of sys ram oom.
maybe it fixed with v1.4! working well!! thanks
@UmeAiRT 1.5 seems to have fixed the memory issue. Only 40gb now. What did you change?
@rkleol I completely modified the upscaler, the memory problems were my fault.
@rkleol To put it simply, I've already reversed the interpolation and upscaling to limit the consumption of interpolation. I've added a VRAM cleaner between the two. And for upscaling, the formula for applying the user's ratio was poorly implemented, resulting in multiplication by 4 and then again multiplication by the chosen ratio, so if it was 2 in the end the video was upscaled 8x.
@UmeAiRT thank you for the fixes