
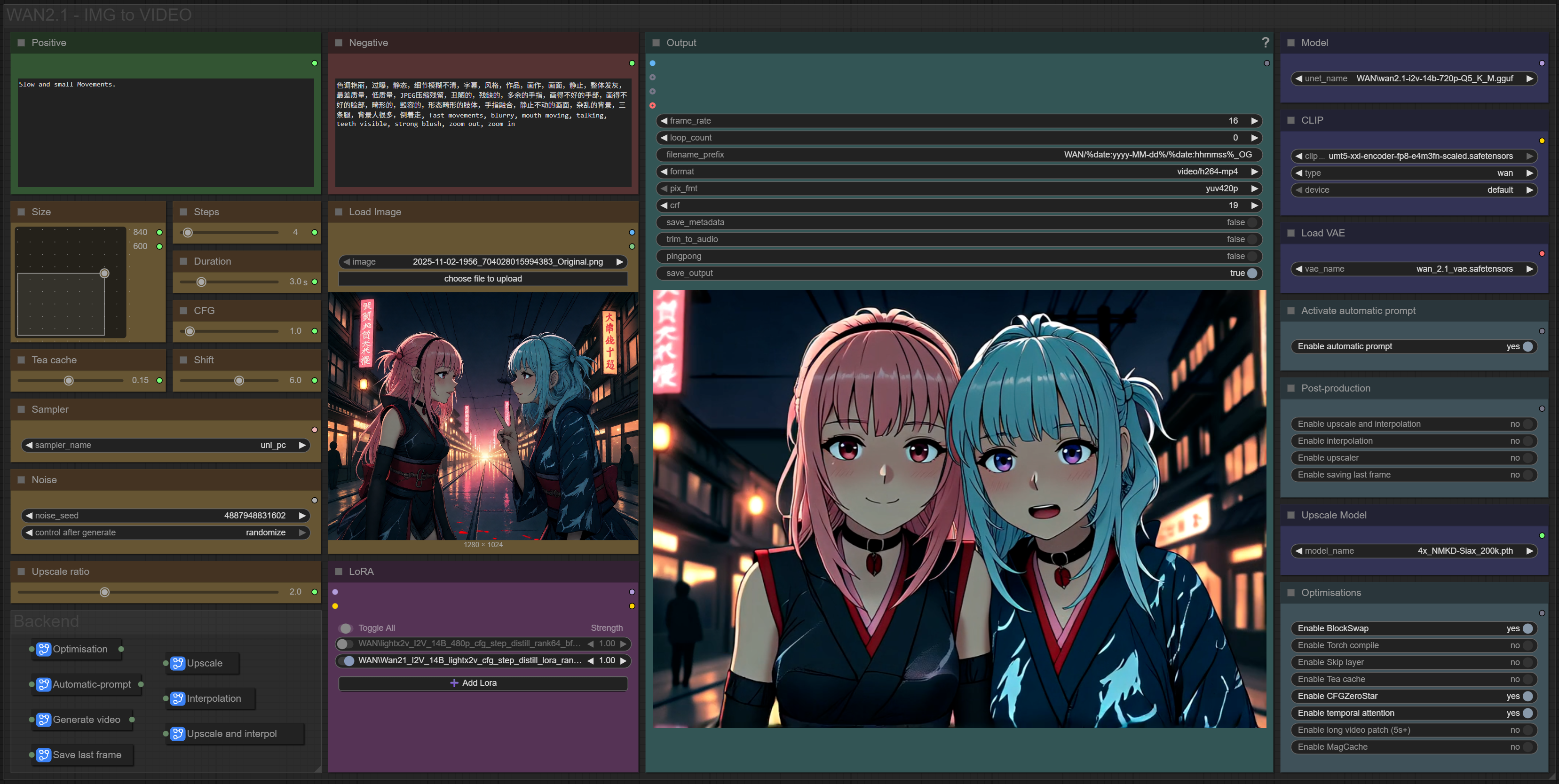
✨ WAN2.1 — Image to video — Simple Workflow
A clean, all-in-one WAN image-to-video workflow built entirely with the UmeAiRT Toolkit for ComfyUI.
Only 12 nodes. No spaghetti wires. Just load your model, write your prompt, and hit generate.
⚠️ IMPORTANT — Nodes 2.0 Required
This workflow is built for the Nodes 2.0 (Vue) interface of ComfyUI. If you don't enable it, the workflow may have display problems.
How to activate Nodes 2.0:
Open ComfyUI
Go to Settings (⚙️ icon, bottom-left)
Find "Use Nodes V2 (Vue)" and toggle it ON
Refresh the page
Load the workflow
If you prefer the classic interface, check out my Legacy version of this workflow instead (link).
🎯 Features
Text-to-video generation
Automatic download of models in auto version
Built-in SeedVR2 upscaler — high-quality tiled upscaling (toggleable on/off) Slower than a classic upscaler, but significantly better quality
Full metadata embedding — your images are saved with all generation parameters, ready for online publishing and remixing
3 LoRA slots — with individual on/off toggles and strength control and you can connect as many other lora modules to each other for as many LoRA as you want.
📦 Custom Node Required
Only one custom node to install:
Install via ComfyUI Manager (search "UmeAiRT") or use the UmeAiRT Auto-Installer.
The Toolkit packages everything internally — upscaler, face detailer, metadata saver. No other custom nodes needed.
📂 Files you need (in manual version)
For base version
I2V Model : 480p or 720p
In models/diffusion_models
For GGUF version
I2V Quant Model :
- 720p : Q8, Q5, Q3
- 480p : Q8, Q5, Q3
In models/unet
Common files :
CLIP: umt5_xxl_fp8_e4m3fn_scaled.safetensors
in models/clip
CLIP-VISION: clip_vision_h.safetensors
in models/clip_vision
VAE: wan_2.1_vae.safetensors
in models/vae
Speed LoRA: 480p, 720p
in models/loras
ANY upscale model:
Realistic : RealESRGAN_x4plus.pth
Anime : RealESRGAN_x4plus_anime_6B.pth
in models/upscale_models
Description
The main purpose of this update is to fix incompatibility issues with newer versions of ComfyUI.
I haven't added any new features, and if the older version works for you, there's no need to change it.
I also took the opportunity to simplify some functions and integrate the subgraph function to make editing easier.
FAQ
Comments (21)
It works great for me! I'm relatively new to AI and I've never tried Wan 2.1 before (only 2.2) and was surpised it's so good and fast. Generated tons of vids in no time on my cheap 3060. Also the auto prompt (Florence-2?) is perfect for lazy people like me - 2 days ago i didn't know such thing existed.
Hi, with version 3.0 I have a problem, maybe someone else does? The cache isn't cleared properly, so i have to do it manually with the vacuum cleaner icon, or else i always get the same video in worse quality changing loras, the image, or whatever. Someone had this problem and foud a way to fix it? I like to be able to have a long queue some times
It's probably not a problem of the workflow itself, I had to update my comfyUI today so it's probably related to that. Anyway I found a solution in case some of you have that problem. I added the flag "--cache-none" to the running script. Just in case this helps someone.
I don't really understand all this and I'm probably doing something wrong, but I'm getting this error: torch.AcceleratorError: CUDA error: invalid argument
CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1
Compile with TORCH_USE_CUDA_DSA to enable device-side assertions.
If anyone knows what to do in this case, please tell me.
Snip it, ask ChatGPT, the torch thing is common. I had to install/uninstall it 3 times when setting up comfyui
Getting Error:
WanImageToVideo
GET was unable to find an engine to execute this computation
For some reason the post-process node in the latest version is completely empty with no options available.
Ok, turns out that's what happens if you have rgthree and swwan installed at the same time.
But now I have another issue, the long video patch won't work because apparently it's missing a latent connection.
Is it possible and/or recommended to use WAN 2.2, replace the 2.1 versions?
If you want to try WAN2.2 use this workflow https://civitai.com/models/1824577
@UmeAiRT 2.2 version is dead and in dire need of updating, there are many depreciated nodes (torch compile nodes and blockswap)
Thanks for this. Your other Wan 2.2 workflow is dead and in dire need of updating, there are many depreciated nodes (torch compile nodes and blockswap)
Blockswap nodes have been depreciated a few months ago, are you planning on integrating the core swap functionality?
The autoprompt translates the image I show it, but how do I disable it to change what I want my video to do?
There is a button on the right to enable or disable auto prompt.
do you think I could generate 480p videos using a 3070 8GB?
It will take long
Thanks for the workflow! Can you make a similar one for the Chroma?
Following your guide and I get to the point where the workflow stops at "Generate Video" node. How do I troubleshoot?
click the sub part and the clip needs to change