
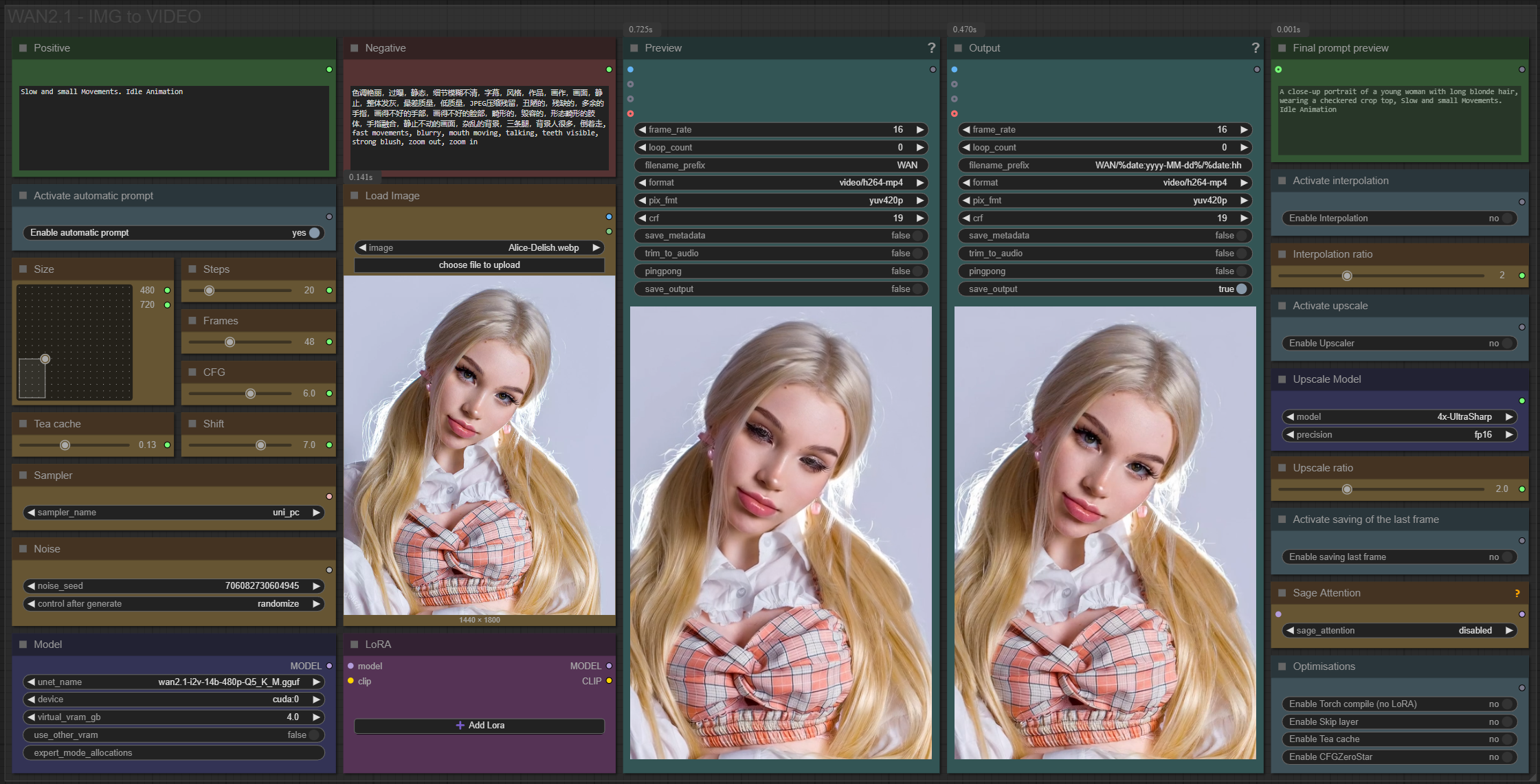
✨ WAN2.1 — Image to video — Simple Workflow
A clean, all-in-one WAN image-to-video workflow built entirely with the UmeAiRT Toolkit for ComfyUI.
Only 12 nodes. No spaghetti wires. Just load your model, write your prompt, and hit generate.
⚠️ IMPORTANT — Nodes 2.0 Required
This workflow is built for the Nodes 2.0 (Vue) interface of ComfyUI. If you don't enable it, the workflow may have display problems.
How to activate Nodes 2.0:
Open ComfyUI
Go to Settings (⚙️ icon, bottom-left)
Find "Use Nodes V2 (Vue)" and toggle it ON
Refresh the page
Load the workflow
If you prefer the classic interface, check out my Legacy version of this workflow instead (link).
🎯 Features
Text-to-video generation
Automatic download of models in auto version
Built-in SeedVR2 upscaler — high-quality tiled upscaling (toggleable on/off) Slower than a classic upscaler, but significantly better quality
Full metadata embedding — your images are saved with all generation parameters, ready for online publishing and remixing
3 LoRA slots — with individual on/off toggles and strength control and you can connect as many other lora modules to each other for as many LoRA as you want.
📦 Custom Node Required
Only one custom node to install:
Install via ComfyUI Manager (search "UmeAiRT") or use the UmeAiRT Auto-Installer.
The Toolkit packages everything internally — upscaler, face detailer, metadata saver. No other custom nodes needed.
📂 Files you need (in manual version)
For base version
I2V Model : 480p or 720p
In models/diffusion_models
For GGUF version
I2V Quant Model :
- 720p : Q8, Q5, Q3
- 480p : Q8, Q5, Q3
In models/unet
Common files :
CLIP: umt5_xxl_fp8_e4m3fn_scaled.safetensors
in models/clip
CLIP-VISION: clip_vision_h.safetensors
in models/clip_vision
VAE: wan_2.1_vae.safetensors
in models/vae
Speed LoRA: 480p, 720p
in models/loras
ANY upscale model:
Realistic : RealESRGAN_x4plus.pth
Anime : RealESRGAN_x4plus_anime_6B.pth
in models/upscale_models
Description
What's new? :
ComfyUi 0.3.29 positive node fix,
LoRA fix with torch compile.
FAQ
Comments (75)
In Version 2.1, model nodes are unable to select models, and text nodes are unable to enter text.
Checkpoint files will always be loaded safely.
Total VRAM 16376 MB, total RAM 130841 MB
pytorch version: 2.6.0+cu126
xformers version: 0.0.29.post3
Set vram state to: NORMAL_VRAM
Device: cuda:0 NVIDIA GeForce RTX 4080 : cudaMallocAsync
Using sage attention
Python version: 3.12.9 (tags/v3.12.9:fdb8142, Feb 4 2025, 15:27:58) [MSC v.1942 64 bit (AMD64)]
ComfyUI version: 0.3.29
This is strange because I developed it on ComfyUI 0.3.29 and retested on a clean installation without any problems.
Same for me. I can't define my models and all other inputs. When I freshly import it and try to run:
"Prompt outputs failed validation: Required input is missing: expression Required input is missing: frame_rate Required input is missing: filename_prefix Required input is missing: loop_count Required input is missing: pingpong Required input is missing: save_output Required input is missing: format Required input is missing: frame_rate Required input is missing: filename_prefix Required input is missing: loop_count Required input is missing: pingpong Required input is missing: save_output Required input is missing: format VAELoader: - Required input is missing: vae_name RandomNoise: - Required input is missing: noise_seed KSamplerSelect: - Required input is missing: sampler_name BasicScheduler: - Required input is missing: scheduler - Required input is missing: denoise VHS_VideoCombine: - Required input is missing: frame_rate - Required input is missing: filename_prefix - Required input is missing: loop_count - Required input is missing: pingpong - Required input is missing: save_output - Required input is missing: format VHS_VideoCombine: - Required input is missing: frame_rate - Required input is missing: filename_prefix - Required input is missing: loop_count - Required input is missing: pingpong - Required input is missing: save_output - Required input is missing: format LoadImage: - Exception when validating inner node: LoadImage.VALIDATE_INPUTS() missing 1 required positional argument: 'image' CLIPVisionLoader: - Required input is missing: clip_name MathExpression|pysssss: - Required input is missing: expression PathchSageAttentionKJ: - Required input is missing: sage_attention CLIPVisionEncode: - Required input is missing: crop ImageScale: - Required input is missing: upscale_method - Required input is missing: crop WanImageToVideo: - Required input is missing: batch_size GetLatentRangeFromBatch: - Required input is missing: num_frames - Required input is missing: start_index ScheduledCFGGuidance: - Required input is missing: start_percent - Required input is missing: end_percent - Required input is missing: cfg DownloadAndLoadFlorence2Model: - Required input is missing: precision - Required input is missing: model - Required input is missing: attention Florence2Run: - Required input is missing: task - Required input is missing: text_input - Required input is missing: fill_mask Text Find and Replace: - Required input is missing: find - Required input is missing: replace Text Concatenate: - Required input is missing: delimiter - Required input is missing: clean_whitespace UnetLoaderGGUFDisTorchMultiGPU: - Required input is missing: unet_name CLIPLoaderMultiGPU: - Required input is missing: type - Required input is missing: clip_name Text Multiline: - Required input is missing: text"
Same issue here.
Same here
Same here
I'm having the same issue!
I figured this out, in the terminal as it's loading it's showing that I was running an older version of the ComfyUI frontend. Doing a GIT Pull on the folder didn't upgrade this and instead it gives a command to run to upgrade it the UI version. It will be something like: ComfyUI-Sage\ComfyUI\venv\Scripts\python.exe -m pip install -r ComfyUI-Sage\ComfyUI\requirements.txt. After running that and clearing my cache the UI is now showing the Textfields again.
This kind of problem can occur if your ComfyUI frontend is not up to date. The latest updates break my old workflows, but when I update them, they no longer work for older versions.
I just started getting into this today and things are working pretty smoothly. However, all my animations end up in slow motion for some reason, and I can't figure out why. I'm pretty close to the default settings (though I removed most of the negative prompt since it was interfering with my positive prompt) with Shift adjusted to 8 and CFG to 5 (I've tried different values for both). I have attempted different resolutions for the source image. The framerate is 16 fps and I'm rendering a total of 80 frames (5 seconds). No matter what I do, the animation renders as if at 3-4x slow-motion. What am I doing wrong?
So what was new in this version? Saw on your F2V that tensorRT was working with LoRA now?? if yes, also in this I2V release? Or did I misundertand it?
Yes now LoRA work with TorchCompile optimisation
In Version 2.1, model nodes are unable to select models, and text nodes are unable to enter text.
I ended up rolling back to the previous version and using it.
This kind of problem can occur if your ComfyUI frontend is not up to date. The latest updates break my old workflows, but when I update them, they no longer work for older versions.
One question: who understands this Node?
I have a 5070ti 16GB video card. I set the Q5_k_s 480p gguf (virtual_vram_gb 3.5) model in Node
When I start training, I get the following information
Device--------Layers---Memory (MB)---%-Total
-------------------------------------------------
cuda:0 --------559-----7957.32--------69.1%
cpu------------253-----3564.20--------30.9%
In total these two indicators give 12.5 GB, shouldn't it be 16GB? And what settings would be optimal?
To put it simply, "virtual RAM" frees up part of the model on your RAM instead of VRAM. This is useful when you are short on RAM. To find the best virtual VRAM setting, the easiest way is to start a video generation and monitor the "dedicated GPU memory" in your task manager in the "performance" tab. If the latter is at 100% or very close, then you need to increase the virtual VRAM. (You must disable torchcompile during these tests)
@UmeAiRT i know this, but why all memory is - 12.5 not 16?
@_VI_ because the model file is Q5_k_s (arround 13GB)
@UmeAiRT thanks
Hi,I can't find the missing nodes. They can't be installed via the manager, and they're not available via search:
When loading the graph, the following node types were not found
easy cleanGpuUsed
easy showAnything
easy promptReplace
If anyone could help,
Not sure why but on ubuntu running the workflow always when it reaches the upscaler 1 part I get OOM error, but if i run the same workflow and settings in windows it works fine
Same issue here on Arch. ComfyUI or the workflow seems to get really close to RAM usage on 32Gb and just running the workflow from an external browser (another laptop) makes the difference between getting OOM killed or not. I guess I will try Windows at that point
Do you use torchcompile? Can yo ugive me more information on hardware and generation parameter?
I had more consistent in Windows, especially with installing Blackwell GPU (5070 ti) 16 GB VRAM and 32 GB or RAM. Still get out OOM if I start using upscaling 2x, but I can do upscaling after if needed so I'm not too worried.
Good job on your workflow. Really help me kickstart
Does anyone have the solution to this problem were UmeAiRT workflow doesn't preview whist the video is being generated?
This kind of problem can occur if your ComfyUI frontend is not up to date. The latest updates break my old workflows, but when I update them, they no longer work for older versions.
Nvm I was wrong. Everything works great, 2.1 is perfect, appreciate you, @UmeAiRT!!
nitpick: Would it be better to add florence created prompt after the user provided prompt.
I guess it could be better when you only add trigger words as user prompt to start the prompt with trigger word.
Anyone have any insight into manipulating loras in prompts?
My understanding is that, if I use sage attention, I can load loras in with 0 strength and then turn them on, up/down, or off with prompts on a timeline. Like this:
0%:<lora:cool_lora_01:1.0> Prompt related to that lora
25%:<lora:cool_lora_01:0.0> <lora:cool_lora_02:1.0> Prompt related to those loras
50%:<lora:cool_lora_03:1.0> Prompt related to that lora
But I can't seem to get that work and I'm wondering if it's something I'm not understanding about the pipeline or loras in general. 😅 Any ideas?
Hi, I have never head of this before. You are saying there may be a way to call the Loras at different strengths and at different times during rendering? Interesting. Let us know if you ever get this working.
I was having an issue where it seemed to be skipping over the lora loading altogether - let me know if you find something that works here!
Anyone have any idea why my output is just a black screen?
I've tried a bunch of workflows with Wan2.1 I2V, trying both the 480 and 720 scaled models and also the fp32 and bf16 VAEs with no change at all. The only different result I got was a output of pure noise when setting the steps to 1, besides that always a black output.
Not sure if I'm missing something to get I2V working properly, I'm kinda new to all of this
what do you normally set the steps to?
@miquel96 I still haven’t gotten a single good output, so I don’t think the steps have made any difference (at least I don’t think so). But when I use just 1 step, the output is noise, and if I use more than 1, the output is black.
black output for me too. I used to be able to generate wan video just fine but not since I updated
I was having a similar issue when using SageAttention. (Win 11 / ComfyUI 0.3.29)
I tried changing the "mode" to sageattn_qk_int8_pv_fp16_triton, fixing the issue.
I'm not really technical, but narrowing down the issues and messing around with nodes worked out.
Got the following error in Console before using ___: RuntimeWarning: invalid value encountered in cast return tensor_to_int(tensor, 8).astype(np.uint8)
I have it working now, I was trying to create videos using comfyui portable but switching to the desktop app made it work for me instantly.
Has anybody got this working on the 50 series cards? if so how?
https://github.com/comfyanonymous/ComfyUI/discussions/6643
install the new ver comfyui v0.3.30
Any idea why the positive prompt box has changed? It's no longer a big text box like the negative prompt box, and I'm not sure if it's taking my full prompt as things aren't quite generating as I hoped
You are using the latest V2.1? I didn't notice anything diffferent about the positive or negative prompt box. I am still testing it but everything seems to be working ok for me. Note: I do not use Interpolation, Upscale or Teacache tho.
Can't install some nodes on the latest comfy:
[ComfyUI-Manager] Installation failed: Node 'ComfyUI-Upscaler-Tensorrt@nightly' not found in [dev, cache]x2 :(
x2
Try using this version:
.\python_embeded\python.exe -m pip install tensorrt==10.8.0.43
Fixed it for me.
https://github.com/yuvraj108c/ComfyUI-Upscaler-Tensorrt/issues/45#issuecomment-2715616081
I used this install guide and it fixed the issue for me. Note: I do not use the built in upscaler tho, I was just trying to clear the error.
https://github.com/yuvraj108c/ComfyUI-Upscaler-Tensorrt/issues/46
@nrocka Bro you saved my ass
我也这样,装不上
completely broken on comfyui v0.3.29, don't update
Hmmm...I am on: ComfyUI: v0.3.29, (2025-04-17), Manager: V3.31.10.....works fine for me w/o any issues. Could be some other issue. I am on Windows 11, Python V3.12.8, pytorch version: 2.6.0+cu126, ComfyUI frontend version: 1.16.9.
For some installs the ComfyUI Frontend isn't automatically updated. For me as the app started it gives a warning and a path to run to run the update. Example path: ComfyUI\venv\Scripts\python.exe -m pip install -r ComfyUI\requirements.txt
Works great out of the box, BUT my length and steps, Size, Tea cache, CFG, Frames... has no sliders or inputs.... Any idea why? (first time user)
did you update comfyui, update all? I had an issue the other week where my sliders were stuck but they are fine now with everything updated and running V2.1 of this workflow.
@yajukun I took away comfyui-mixlab-nodes, and then sliders and other ui elements came back.
EDIT: PSA on v2.1 LORAs are working as they should! Guess some node got updated and borked older versions of this workflow
EDIT2: Welp, my bad, the changelog says "ComfyUi 0.3.29 positive node fix," so that's probably what was broken
On ComfyUI Desktop 0.4.40 it seems that the LORAs got borked. Both in the v2.0 version of this workflow and also the v1.8. LORAs are just not applying
I have this issue when I use V2.1. You say you've fixed the issue with (Enable Torch Compile) so you can use it with Lora's but I had this error come up "SamplerCustomAdvanced
Allocation on device"
Any help in why this is happening?
The sliders don't work. I think is best just use another nodes for that
Did a couple of outputs and I must say that for a locally installed free solution the outcomes are really good. Looking forward for future releases with even better quality!
Maybe i missing something, but i getting completely random video, wf don't use my image
Has anyone had a problem with the brightness of the picture going down? The tone of the skin color changes
Not me, I have used all of the versions quite a bit. I do notice that if you have highly detailed skin for the input image it tends to smooth out as the video gets created unless I reinforce with a character lora I trained for WAN. Not sure why your video would get darker as it progresses? I've never seen that.
Check if you have a workflow that includes the 'colormatch' node, it somewhat corrects that problem. It's also recommended to use Wan 720p, since that brightness change is more noticeable in 480p. And well, it also depends on the background color and the number of frames; if you do tests, sometimes you'll have that problem, and sometimes you won't.
@EechiZero How can i include the "colormatch" node in the workflow?
@saffff Double-click anywhere on the workspace, search for 'color match', and choose either of the two that appear.
Connect the input image to 'image reference'.
Connect the VAE decode node to 'image or image target'.
Now, take the Image output node from 'colormatch' to the VHS output node.
I added this node to the "simple" version and it will be on the full version very soon.
First of all, thanks a lot for this workflow. I learned a lot about Wan video gen already.
I have noticed that the first pass generally has a lot more motion and is generally far more dynamic than the 2nd pass - and therefore the end result. Is this something that is expected? Can it be addressed somehow?
EDIT: I figured it out myself. It's the Tea cache node that's causing this. The start percent field is set to 0.1 by default, which, while avoiding artifacts in messy scenes, also kills a lot of detailed movements in regular animations. The solution is to set it to 0. I'd suggest that you document this and ideally give this its own slider input, so users can adjust it based on what kind of scene they're generating.
BUG for v2.1 (2.0 works fine)
got All your ComfyUI nodes are missing required inputs, like vae_name, expression, format, frame_rate, noise_seed, sampler_name, etc.
same issue described detailed here https://civitai.com/models/1363672
Please read the big red ligne in the description before spaming all my model :
Warning: The latest version of this workflow (2.1) fixes compatibility issues with the latest ComfyUI frontend updates. The problem is that it is therefore not compatible with older versions of the frontend. I don't have a miracle solution to create a workflow compatible with all versions, so if you have a problem with 2.1, please try 2.0.
https://civitai.com/models/1309415/comfyui-auto-installer-wan21-or-sageattention-or-50xx-cards-compatible-or
can install this,when i install new comfyui is work fine
Interesting. I have been using v2.1 since it came out and I have not had any of these issues. I do not use UmeAiRT's autoinstaller, I manually install everything myself. I always update comfyui and all my nodes when using a new WF.
The issue is that ComfyUI's front end version (separate from the actually app) is not automatically updated. If you watch the command line as it starts it might give the command line to run to update the frontend version. For me it was this: ComfyUI\venv\Scripts\python.exe -m pip install -r ComfyUI\requirements.txt
this is a user issue. obviously. lol.